Исследователи Университета Цинхуа разработали алгоритм LCM-LoRA, позволяющий в реальном времени генерировать изображения по текстовому описанию или наброску.
Наиболее популярным text-to-image моделям, таким как Stable Diffusion, Midjourney и DALLE-3, требуется от нескольких секунд до двух минут для генерации изображения. LCM-LoRA (Latent Consistency Model – Low-Rank Adaptation) – надстройка над Stable Diffusion, уменьшающая время генерации до порядка 100 миллисекунд.
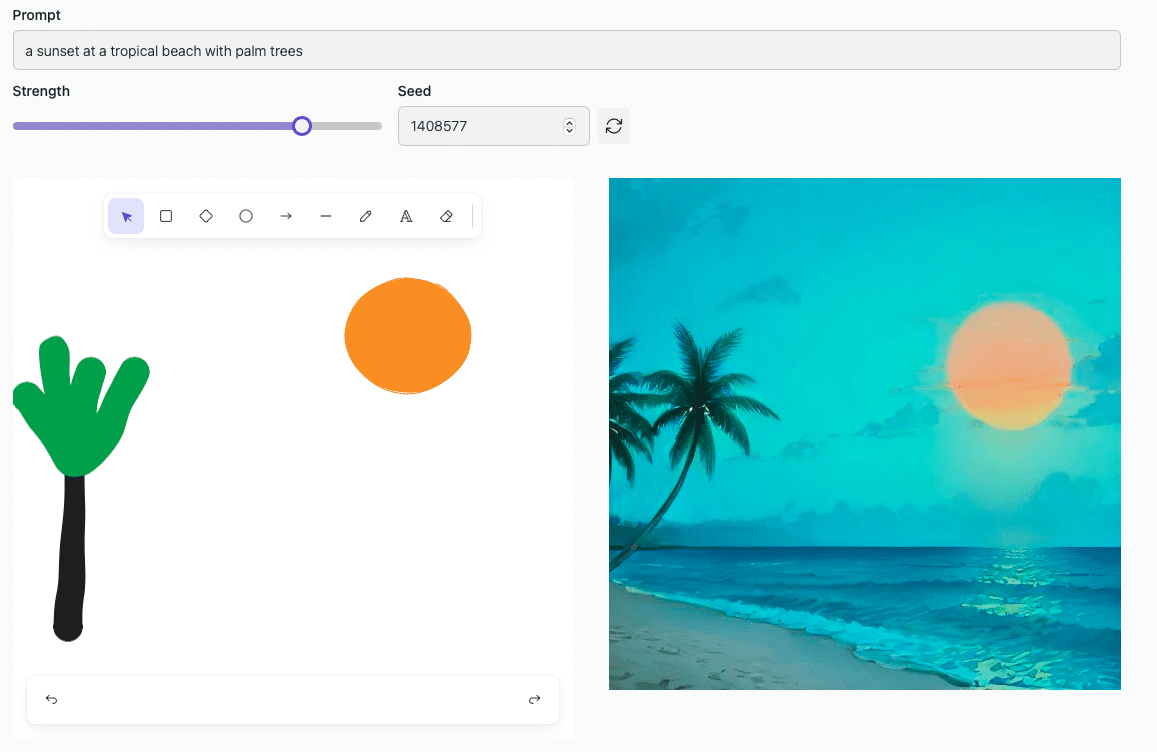
LCM-LoRa ускоряет генерацию изображений за счет сокращения количества необходимых шагов семплирования — процессов преобразования исходного текста или изображения в более качественное и детализированное изображение. Примеры изображений, сгенерированных алгоритмом за 4 шага: 
В качестве входных данных LCM-LoRa может выступать только текстовый запрос, а также комбинация текстового запроса и наброска из примитивных фигур (например, прямоугольников, линий и овалов) или изображения, которое необходимо модифицировать.
Метод применим для генерации не только двумерных, но и трехмерных сцен, что позволит значительно ускорить разработку видеигр, спецэффектов в кино, а также сред дополненной и смешанной реальности. Помимо этого, снижение количества шагов для семплирования означает снижение требований к вычислительным ресурсам.
Потенциально LCM-LoRa можно интегрировать с любой text-to-image моделью, но на текущий момент авторы протестировали ее только на Stable Diffusion. Протестировать алгоритм можно по ссылке. Код LCM-LoRA опубликован в открытом доступе.