Воссоздание реалистичной 3D-модели объекта по 2D-данным — непростая и захватывающая задача, которую решают многие исследователи. Процесс создания и рендеринга высококачественной 3D-модели сложен сам по себе, а оценка формы трехмерного объекта по двумерному изображению — тем более. Особый интерес представляет получение виртуальных оцифрованных моделей (для разных случаев — от видеоигр до медицинских приложений). Несмотря на успехи в этой области, до создания высококачественных реалистичных 3D-объектов еще далеко. Говоря о моделировании человеческих фигур, например, можно отметить значительный прогресс в построении формы человеческого лица, но гораздо меньше сделано для создания 3D-моделей волос.
Исследователи из Института креативных технологий в Южной Калифорнии, компании Pinscreen и лаборатории Microsoft Research Asia рассмотрели задачу восстановления 3D-модели волос и предложили метод глубокого обучения для трехмерной реконструкции по единственному обычному 2D-изображению.
В отличие от существующих подходов, описанный метод основан на глубоком обучении и фактически способен напрямую генерировать пряди волос вместо объемных сеток или структур “облаков точек”. Новый подход, по мнению авторов, удовлетворяет современным требованиям к разрешению и качеству в целом, значительно оптимизирует скорость и занимаемый объем. Большим плюсом является то, что модель обеспечивает гладкое, компактное и непрерывное представление геометрии волос, что открывает возможности плавного сэмплинга и интерполяции.

Метод
Метод состоит из трех шагов:
- В качестве предварительной обработки вычисляется двумерное поле направлений в области волос на изображении;
- Далее глубокая нейронная сеть принимает двумерное поле направлений и выводит генерируемые линии прядей (в виде последовательностей трехмерных точек);
- Этап восстановления, который генерирует гладкую и плотную модель волос.
Предобработка
Как упоминалось ранее, первым шагом является предварительная обработка картинки, когда авторы хотят получить двумерное поле ориентаций, но только для области волос. Поэтому первый фильтр фактически извлекает из портрета область с изображением волос, для этого используется специальная жесткая маска. После этого для определения поля в каждой точке используются фильтры Габора и строится пиксельная 2D-карта ориентаций. Стоит также отметить, что исследователи не принимают во внимание направление ориентации, т. е. фактическое направление роста волос. Чтобы улучшить результат при сегментировании области волос, применяется специальная маска для определения головы и тела человека на картинке. Наконец, после предобработки выход представляет собой изображение 3 x 256 x 256, где первые два канала содержат ориентацию, закодированную цветом, а третья — фактическая сегментация.
Глубокая нейронная сеть
Представление данных
Результатом сети прогнозирования является модель волос, которая представлена последовательностями упорядоченных трехмерных точек, соответствующих смоделированным прядям. В экспериментах все последовательности состоят из 100 точек, каждая из которых содержит атрибуты положения в трехмерном пространстве и кривизны. Таким образом, модель волос будет состоять из N прядей (последовательностей).

Карта ориентаций на входе сначала кодируется в высокоуровневый вектор признаков, а затем декодируется до 32 x 32 отдельных признаков пряди. Затем каждый из этих признаков декодируется в геометрию волос, представленную позициями и кривизнами для всех точек в цепочке.
Архитектура сети
Используемая сеть принимает карту ориентаций в качестве входных параметров и дает две матрицы в качестве выхода: позиции и кривизны, как объяснялось ранее. Сеть имеет сверточную архитектуру энкодера/декодера, которая детерминированно кодирует входное изображение в скрытый вектор фиксированного размера 512. Этот скрытый вектор фактически представляет собой признаки волос, который затем преобразовывается декодером. Энкодер состоит из 5 сверточных слоев и max pooling слоя. Закодированный скрытый вектор затем расшифровывается декодером (состоит из 3 деконволюционных слоев) в множество векторов признаков прядей (как упоминалось выше), и, наконец, для дальнейшего декодирования векторов в желаемую геометрию, состоящую из кривизн и координат, используется многослойный перцептрон.
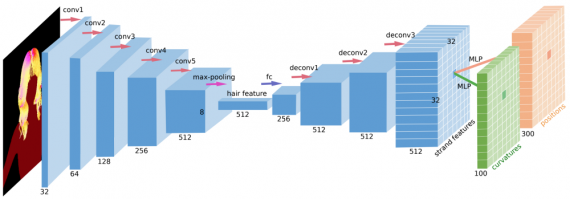
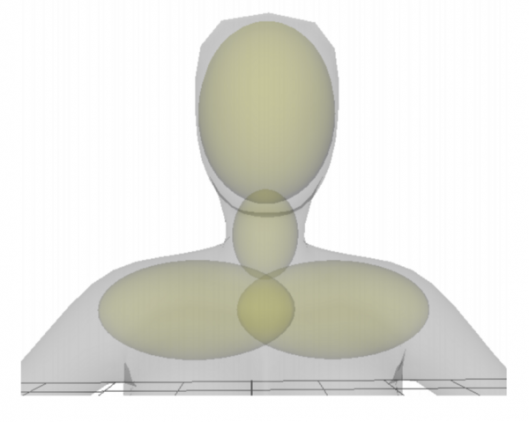
Чтобы выполнить оптимизацию такой определенной архитектуры для поставленной задачи, авторы используют три функции потерь: две из них — L2-потери для геометрии (трехмерное положение и кривизна), а третья — потери столкновений, измеряющих столкновение между волосами и человеческим телом.
Оценки и выводы
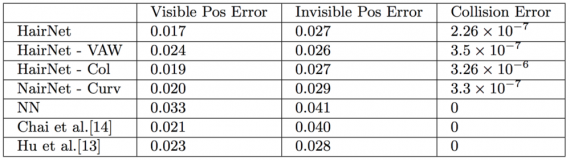
Чтобы оценить определенный метод и подход к проблеме реконструкции трехмерной модели волос, авторы используют количественные и качественные оценочные показатели. Фактически, для количественного анализа вычисляется потеря реконструкции видимой и невидимой части прически отдельно, чтобы можно было провести сравнение. При этом создается искусственный набор тестов со 100 случайными моделями прически и 4 изображениями, полученными из случайных представлений для каждой модели. Результаты и сравнение с существующими подходами приведены в следующей таблице.

С другой стороны, чтобы иметь возможность качественно оценить эффективность предлагаемого подхода, исследователи подают на вход несколько реальных портретных фотографий и показывают, что метод способен обрабатывать различные формы волос (короткие, средние, длинные) и степени кучерявости.

Кроме того, проверяется также плавный сэмплинг и интерполяция. Они показывают, что их модель способна плавно интерполировать между стилями волос (от прямых до кудрявых или коротких до длинных).

Предложенный подход интересен во многих отношениях. Сквозная сетевая структура способна успешно восстанавливать 3D-модель волос по 2D-изображению, что само по себе впечатляет, а также возможен плавный переход между прическами посредством интерполяции благодаря используемой архитектуре энкодера/декодера.