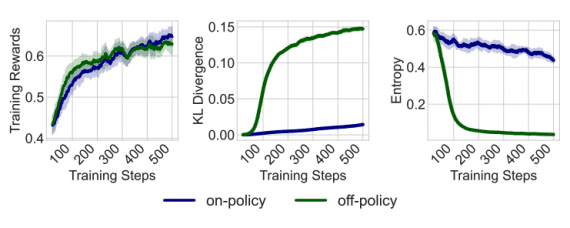
Исследователи Microsoft Research представили Phi-1 — языковую модель для генерации кода всего с 1,3 миллиардами параметров, которая смогла достигнуть близкого к state-of-the-art уровня генерации кода с помощью собранного авторами датасета. Исследователи обнаружили, что большинство существующих датасетов с кодом непригодны для обучения моделей: они не содержат полной информации, не имеют осмысленных комментариев, в основном представляют собой конфигурационные файлы или черновые варианты.
Авторы создали собственный близкий по качеству к учебнику по программированию датасет CodeTextBook с программным кодом на языке Python, содержащим 6 миллиардов токенов, отобранных из The Stack и StackOverflow, а также 1 миллиард токенов, сгенерированных моделью GPT-3.5, при этом последние включали комментарии и описание.

Дообучение модели на датасете CodeExercises, содержащим 180M токенов с синтетически сгенерированными упражнениями с качественным описанием, неожиданно наделила модель эмергентными свойствами, например, использовать внешние библиотеки Pygame и Tkinter, хотя в датасете библиотеки не упоминались.

Авторы исследовали модель phi-1-base, которая не дообучалась на датасете CodeExercises, и модель phi-1-small, более компактную модель с 350 миллионами параметров, обученную с использованием той же методологии, что и модель phi-1, достигающая 45% на тесте HumanEval.
Описание модели
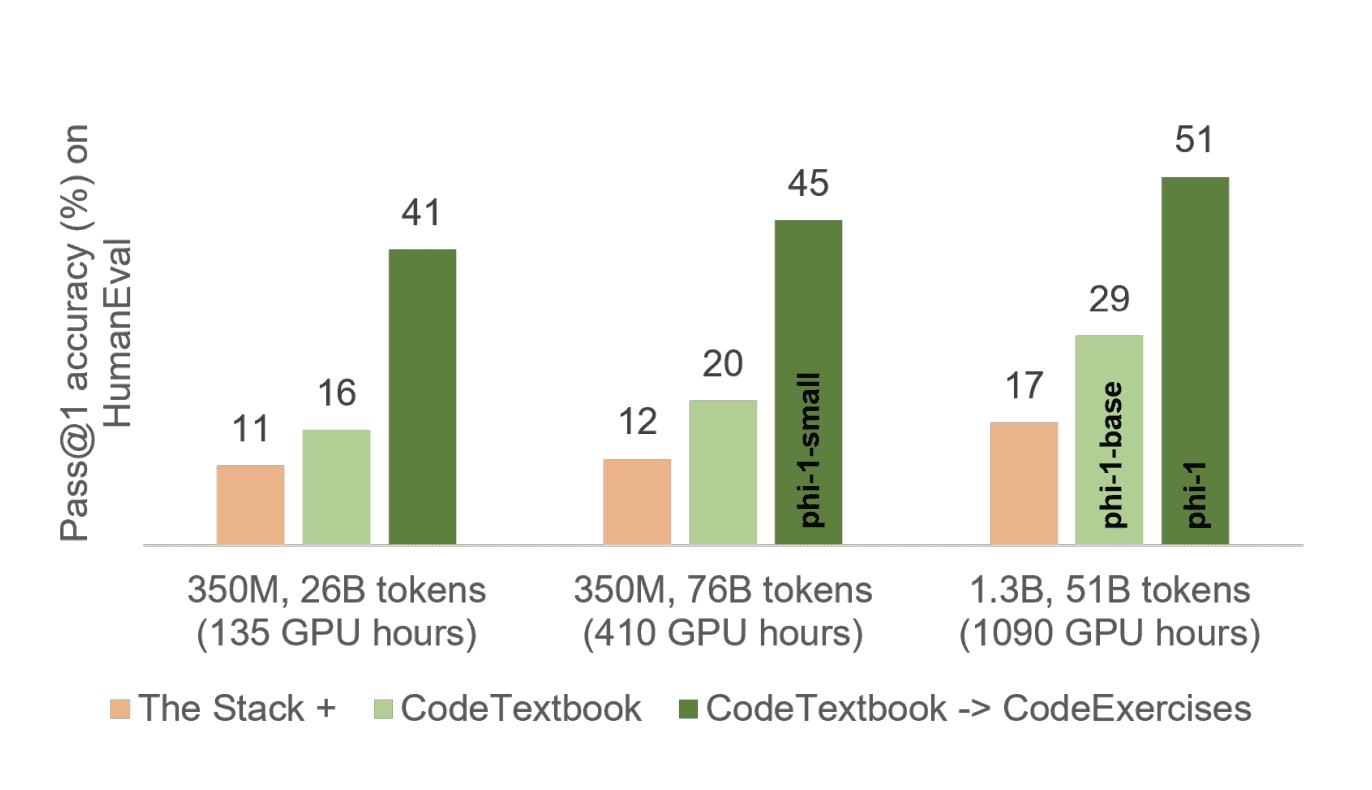
Phi-1 основана на архитектуре Transformer и содержит 1,3B параметров. Модель обучалась в течение 4 дней на 8 Nvidia A100 на разработанном авторами датасете CodeExerсises по качеству приближающегося к учебнику по программированию, состоящего из 6 миллиардов токенов. Датасет дополнили 1 миллиардом токенов, синтетически созданных моделью GPT-3.5.
Слева представлен пример качественных данных для обучения, справа — низкого качества:

Результаты Phi-1
Предварительное обучение на наборе данных CodeTextbook и дообучение на CodeExercises дали близкие к state-of-the-art результаты. Несмотря на относительно небольшой масштаб, phi-1 достигает точности pass@1 на уровне 50,6% на бенчмарке HumanEval и 55,5% на бенчмарке MBPP, уступая GPT-4 и WizardCoder (последней только на бенчмарке HumanEval).
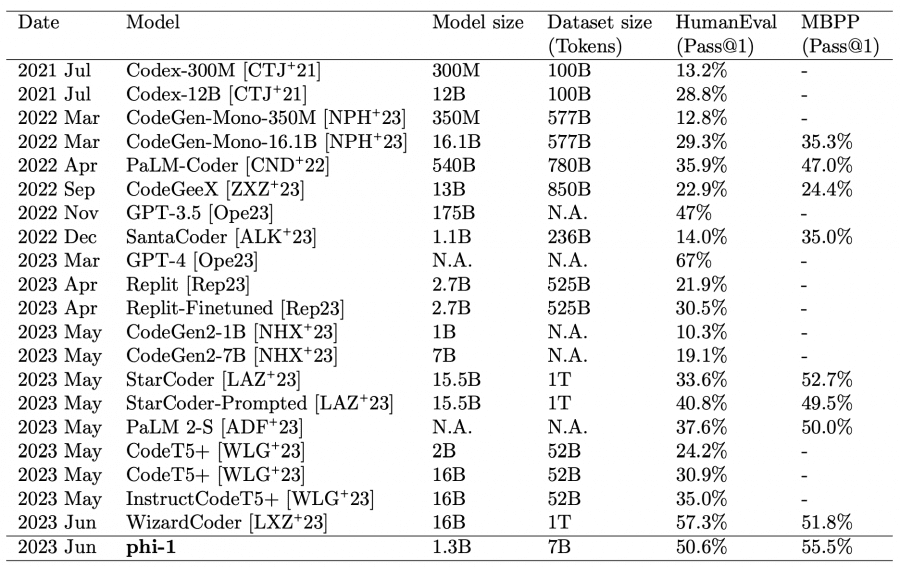
Модель проявляет удивительные эмергентные свойства по сравнению с базовой моделью phi-1-base, которая не дообучалась на высококачественном датасете. Например, после дообучения на датасете CodeExercises модели научилась использовать внешние библиотеки Pygame и Tkinter, хотя упражнения не содержали эти библиотеки.

Исследование подтверждает, что качество данных для обучения важнее их количества.