
Виды живой природы запоминаются нами не одинаково хорошо после одного просмотра. Некоторые сцены мы можем вспомнить в деталях даже через десятки лет, другие забываем на следующий день. Одни фотографии врезаются нам в память, другие же забываются за короткое время. На степень запоминаемости, вероятно, влияет индивидуальный опыт, но в некоторой степени это зависит и от характеристики самой сцены.
При перенасыщении визуальными образами, субъекты проявляют тенденцию запоминать или же забывать одни и те же снимки. Это применимо в основном к общим изображениям, фотографиям объектов и лиц. Тем не менее, сложно отыскать признаки, определяющие запоминаемость естественной сцены. На 2018 год методы прогнозирования визуальной запоминаемости естественной сцены не развиты.
Предыдущие работы
Предыдущие исследования показали, что запоминаемость — это измеримая величина. Исследователями MIT были предложены подходы, основанные на глубоком обучении, для оценки запоминаемости изображений.
- Ученые из Массачусетского технологического института натренировали MemNet на крупной базе изображений, и добились точности прогнозирования близкой к тому, как человеческий разум ранжирует фотографии.
- В MIT также создали базу данных для оценки запоминаемости человеческих лиц. Они дополнительно исследовали вклад отдельных признаков (например, доброта, степень доверия) на запоминаемость, но такие характеристики лишь частично объяснили степень запоминаемости лиц.
Новый подход
Исследователи Бэйханского университета в Пекине создали базу данных LNSIM. В базе данных LNSIM 2632 изображений естественных сцен. Для получения этих изображений из датасетов MIR Flickr, MIT1003, NUSEF и базы данных AVA было выбрано 6,886 изображений, из которых затем отобрали исключительно природные сцены.

Специальная игра на память используется для количественной оценки запоминаемости каждого изображения в базе данных LNSIM. Разработано программное обеспечение, в котором было задействовано 104 субъекта (47 женщин и 57 мужчин). В их числе не было добровольцев, которые участвовали в отборе изображений. Схема нашей игры приведена на рисунке 2.
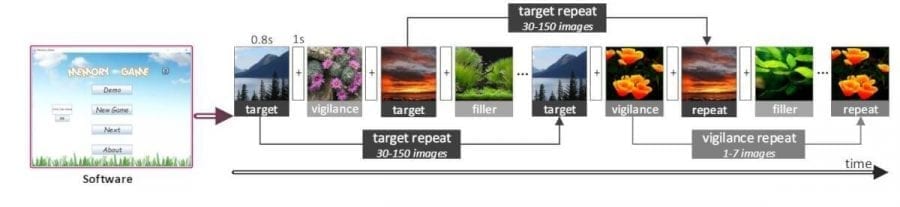
В этом эксперименте было использовано 2632 целевых изображения, 488 изображений на бдительность и 1200 изображений-наполнителей, все они были неизвестны испытуемым. Изображения на бдительность и наполнители были случайным образом отобраны из 6886 изображений. Образцы на бдительность повторялись в пределах 7 изображений, чтобы быть уверенным, что испытуемые сосредоточены на игре. Изображения-наполнители были представлены один раз, так чтобы можно было задать расстояние между одинаковыми целевыми изображениями или изображениями бдительности. После сбора данных каждому изображению присваивается оценка для определения запоминаемости. Кроме этого, для оценки того, как человеческий разум ранжирует фотографии субъекты разделяются на две независимые группы (группы 1 и 2).
Анализ запоминаемости естественной сцены
Датасет LNSIM собран для лучшего понимания влияния низко-, средне-, высокоуровневых рукописных образов и глубоких образов (deep features) на запоминаемость природной сцены.
Низкоуровневые образы — пиксели, SIFT и HOG2 — оказывают влияние на запоминаемость общих изображений. Чтобы оценить это влияние, регрессия опорных векторов (SVR) для каждого низкоуровневого образа использует тренировочный датасет для предсказания запоминаемости, а затем оценивает SRCC этих низкоуровневых образов с запоминаемостью в тестовом наборе. Ниже в таблице 1 представлены результаты SRCC для естественных сцен, SRCC для общих изображений используется в сравнении. Очевидно, что пиксели (ρ = 0,08), SIFT (ρ = 0,28) и HOG2 (ρ = 0,29) не так эффективны для запоминаемости, как ожидалось, особенно по сравнению с их эффективностью для общих изображений
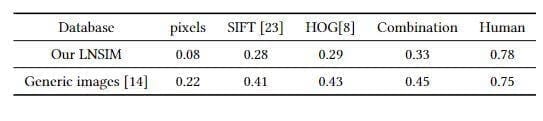
Это говорит о том, что низкоуровневые образы не способны эффективно охарактеризовать визуальную информацию для запоминания естественных сцен.
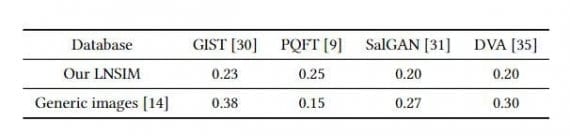
Образы GIST среднего уровня описывают пространственную структуру изображения. Однако в таблице 2 показано, что SRCC у GIST составляет всего 0,23 для естественной сцены, что намного меньше, чем ρ = 0,38 для общих изображений. Это говорит о том, что структурная информация, предоставляемая функцией GIST, менее эффективна для прогнозирования значений запоминаемости на естественных сценах.
В изображениях естественных сцен нет какого-либо бросающегося в глаза объекта, животного или человека, чтобы можно было определить сцену как состоящую из образов высокого уровня. Чтобы получить действительные категории сцен, было создано два эксперимента, предназначенных для определения категории для 2,632 изображений в базе данных.
- Задача 1 (Классификации): пятерых участников попросили указать, какие категории сцен они видят на изображениях. Каждому участнику попадалось случайное изображение. Участникам нужно было выбрать подходящую категорию сцены для каждого из них
- Задача 2 (Подтверждение): Отдельная задача выполнялась на одном и том же наборе изображений путем случайного выбора новых пятерых участников после Задания 1. Участников попросили дать ответ “да” или “нет” на вопрос про каждое изображение. Ответ по умолчанию был установлен на «Нет».
Все изображения относились к категориям на основе большинства голосов после задач 1 и 2.
Далее SVR обучалась для распознавания категории сцен. Определение категории сцены достигает производительности SRCC (ρ = 0,38), превосходя результаты комбинаций низкоуровневых образов.
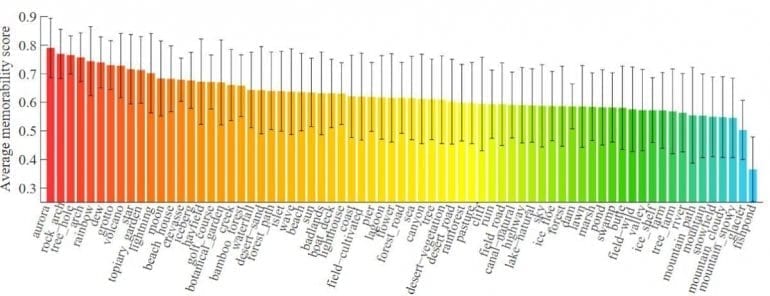
На рисунке ниже горизонтальная ось представляет категории сцены в порядке убывания средних значений запоминаемости. Средний балл варьируется от 0,79 до 0,36, что дает представление о том, как меняется запоминаемость в зависимости от категории сцены. Распределение на рисунке ниже показывает, что некоторые редкие классы изображений, такие как северное сияние, как правило, являются более запоминающимися, в то время как обычные классы, такие как горы, более вероятно, скорее будут забыты. Возможно, это связано с тем, как часто категория встречается в повседневной жизни.
Чтобы понять, как глубокие образы влияют на запоминаемость естественной сцены, настроенная сеть MemNet обучается на базе данных LNSIM, используя евклидово расстояние между предсказанными и известными значениями запоминаемости как функцию потерь. Выходные значения последнего скрытого слоя извлекаются как глубокий образ (размер: 4096). Чтобы оценить корреляцию между глубоким образом и запоминаемостью естественной сцены, аналогично со случаем рукописных образов, предсказатель SVR с гистограммой пересечения ядра обучается для работы с глубокими образами.
SRCC глубокого образа составляет 0,44, что превышает показатели для рукописных образов. DNN действительно хорошо работает для прогнозирования запоминаемости естественной сцены, поскольку глубокий образ показывает довольно высокую точность предсказания. Тем не менее, нет никаких сомнений в том, что точно настроенная сеть MemNet также имеет свое ограничение, поскольку она по-прежнему не достигает человеческих результатов (ρ = 0,78).
DeepNSM
Настроенная (fine-tuned) сеть MemNet служит базовой моделью для прогнозирования запоминаемости природной сцены. В предлагаемой архитектуре DeepNSM deep features прикрепляются к элементу из категории естественных сцен, чтобы точно предсказать запоминаемость изображений естественных сцен. Обратите внимание, что «deep feature» это образ размера 4096, извлеченный из базовой модели.
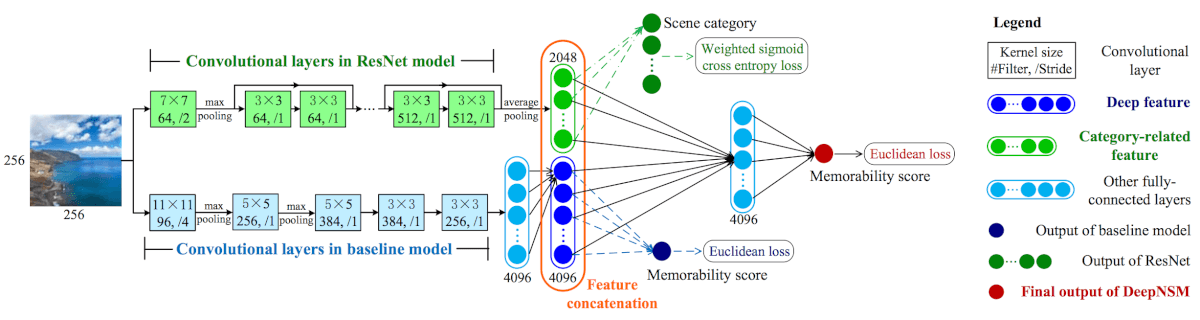
Архитектура модели DeepNSM представлена на рисунке 2. В модели DeepNSM вышеупомянутый образ из категории объединен с deep feature, полученными из базовой модели. На основе такой связи элементов, дополнительные полносвязные слои (включая один скрытый слой размера 4096) служат для прогнозирования запоминаемости естественных сцен. При обучении базовые слои и модели ResNet инициализируются индивидуально подготовленными моделями, а добавленные полносвязные слои случайным образом инициализируются.
Вся сеть совместно обучается методом end-to-end, используя оптимизатор Adam с евклидовым расстоянием, принятым в качестве функции потерь.
Сравнение с другими моделями
Показатели модели DeepNSM в прогнозировании запоминания природной сцены в отношении SRCC (ρ). Модель DeepNSM тестируется как на тестовом наборе базы данных LNSIM, так и на базе базы данных NSIM. Производительность SRCC модели DeepNSM сравнивается с самыми современными методами прогнозирования запоминаемости, включая MemNet, MemoNet и Lu et al. Среди них MemNet и MemoNet — новейшие методы DNN для общих изображений, которые превзошли обычные методы, используя вручную построенные образы. Lu et al. это современный способ предсказания запоминаемости природной сцены.
-

Рис 3. Показатели SRCC DeepNSM и сравниваемых методов
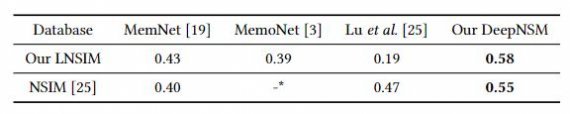
На рисунке 3 показатели SRCC DeepNSM и три сравниваемых метода. DeepNSM достигает значений Ρ = 0,58 и 0,55 по базам LNSIM и NSIM, соответственно. Это значительно превосходит современные методы DNN, MemNet и MemoNet. Результаты демонстрируют эффективность DeepNSM в прогнозировании запоминаемости природной сцены.
Выводы
Ученые из Пекина исследовали запоминаемость естественной сцены дата-ориентированным подходом. Они создали базу данных LNSIM для анализа запоминаемости человеком естественной сцены. Изучив соотношение запоминаемости со низко-, средне- и высоко- уровневыми образами стоит отметить, что высокоуровневые образы играют важную роль в прогнозировании запоминаемости естественной сцены.



