Исследователи использовали предсказание оптического потока для заполнения отсутствующих фрагментов в видеозаписи. Метод был протестирован на задачах DAVIS и YouTubeVOS. Модель получила state-of-the-art результаты по скорости обучения и качеству предсказаний.
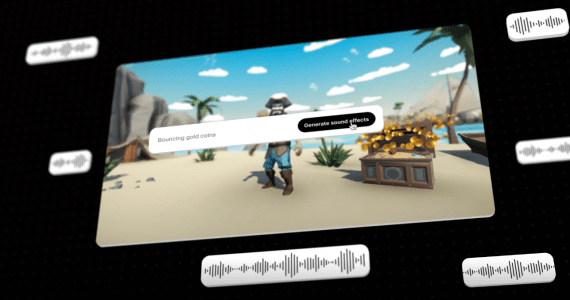
Оптический поток — это последовательность передвижений объектов на видеозаписи. Задача заполнения пробелов в видеозаписи остается актуальной из-за сложности сохранения временной и пространственной последовательности кадров. Исследователи предлагают поточное видео заполнение. Вместо того, что бы заполнять RGB пиксели каждого кадра напрямую, модель распространяет предсказанные пиксели с одного кадра на другой. Сначала генерируется оптический поток с помощью Deep Flow Completion нейросети. Сгенерированный поток используется для распространения пикселей из отсутствующего фрагмента кадра на другие кадры с этим фрагментом. Deep Flow Completion сеть использует coarse-to-fine, чтобы повысить точность предсказанных пикселей и сохранить гладкость оптического потока.
Архитектура фреймворка
Подход состоит из двух шагов:
- Заполнить отсутствующий оптический поток;
- Распространить пиксели с опорой на заполненный оптический поток
На первом шаге используется Deep Flow Completion Network (DFC-Net). DFC-Net состоит из похожих подсетей, которые называются DFC-S. Первая подсеть оценивает поток в широком масштабе и подает кадры на вход второй и третьей подсетям для последующего улучшения предсказанного потока.
На втором шаге, когда оптический поток получен, большинство отсутствующих частей видеозаписи могут быть заполнены с помощью существующих частей через распространение пикселей с других кадров. Распространение пикселей основывается на предсказанном на первом шаге оптическом потоке. Если существуют части кадров, которые не были заполнены после второго шага, они заполняются стандартным методом.
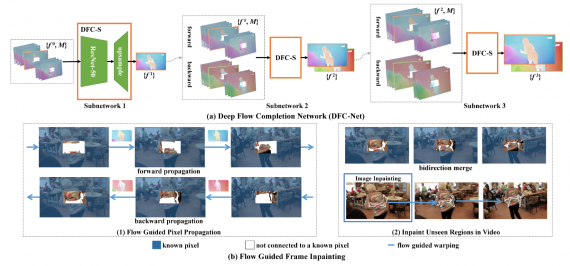
Результаты экспериментов
Исследователи проверили работу модели на двух задачах — DAVIS и YouTubeVOS. В качестве метрик были выбраны PSNR и SSIM. Ниже видно, что предложенный подход более точно заполняет видеозаписи, чем предшествующие модели.
Видеодемонстрация работы алгоритма доступна ниже.