Команда исследователей NVIDIA представила Nemotron-Nano-9B-v2 — гибридную Mamba-Transformer языковую модель, которая выдает ответы в 6 раз быстрее Qwen-3-8B на задачах рассуждения, превосходя ее в точности. Модель с 9 миллиардами параметров была сжата с исходных 12 миллиардов специально для работы на одном GPU NVIDIA A10G. Nemotron-Nano-9B-v2 основана на архитектуре Nemotron-H, где большинство слоев self-attention традиционной Transformer архитектуры заменены слоями Mamba-2 для повышения скорости вывода при генерации длинных трасс рассуждений.
Базовая модель Nemotron-Nano-12B-v2-Base была предварительно обучена на 20 триллионах токенов с использованием формата обучениия FP8. После выравнивания разработчики применили стратегию Minitron для сжатия и дистилляции модели, чтобы она смогла обрабатывать входные последовательности длиной до 128 тысяч токенов на одном GPU NVIDIA A10G (22 ГБ памяти, bfloat16 точность). По сравнению с моделями аналогичного размера Nemotron-Nano-9B-v2 достигает сопоставимой или лучшей точности на бенчмарках рассуждений при увеличении пропускной способности до 6 раз в сценариях типа 8k входных и 16k выходных токенов.
Архитектура модели
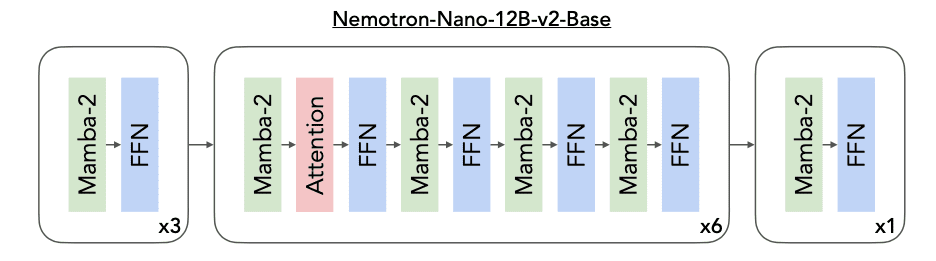
Nemotron-Nano-12B-v2-Base использует 62 слоя, из которых 6 являются self-attention слоями, 28 — FFN, и 28 — Mamba-2 слоями. Скрытая размерность — 5120, FFN промежуточная размерность — 20480, Grouped-Query Attention с 40 query головами и 8 key-value головами. Для Mamba-2 слоев используются 8 групп, размерность состояния 128, размерность головы 64, фактор расширения 2 и размер окна для свертки 4.
Как и в Nemotron-H, модель не использует позиционные эмбеддинги, применяется RMSNorm нормализация, отдельные веса слоя эмбеддинга и выходного слоя, не использует dropout и bias веса для линейных слоев. Для FFN слоев применяется активация squared ReLU.
Предварительное обучение
Nemotron-Nano-12B-v2-Base обучалась на корпусе отобранных и синтетически сгенерированных данных. Математические данные получены через новый пайплайн Nemotron-CC-Math-v1 объемом 133 миллиарда токенов из Common Crawl с использованием конвейера Lynx + LLM. Пайплайн сохраняет уравнения, стандартизирует в LaTeX и превосходит предыдущие математические наборы данных на бенчмарках.
Код получен из GitHub репозиториев через многоэтапную фильтрацию, дедупликацию и фильтры качества. Включены данные code Q&A на 11 языках программирования.
Выравнивание модели
После предварительного обучения модель прошла постобучение через комбинацию контролируемого дообучения (SFT), групповой относительной оптимизации политики (GRPO), прямой оптимизации предпочтений (DPO) и обучения с подкреплением на основе человеческой обратной связи (RLHF). Применялись множественные этапы SFT по различным доменам, за которыми следовало целевое SFT на ключевых областях: использование инструментов, производительность на длинных контекстах и усеченное обучение.
GRPO и RLHF улучшили следование инструкциям и способности к диалогу, в то время как дополнительные этапы DPO еще больше усилили использование инструментов. Постобучение выполнялось на примерно 90 миллиардах токенов.
Сжатие модели
Для работы на одном GPU NVIDIA A10G модель была сжата с использованием стратегии Minitron. Применялось сокращение глубины (удаление 6-10 слоев из исходной 62-слойной архитектуры) в сочетании с сокращением ширины каналов эмбеддинга (4480-5120), FFN размерности (13440-20480) и голов Mamba (112-128).
Финальная архитектура использует 56 слоев с 4 attention слоями, каналы эмбеддинга сокращены с 5120 до 4480, а промежуточный размер FFN — с 20480 до 15680. Это позволило достичь сжатия с 12B до 9B параметров при сохранении производительности.
Результаты
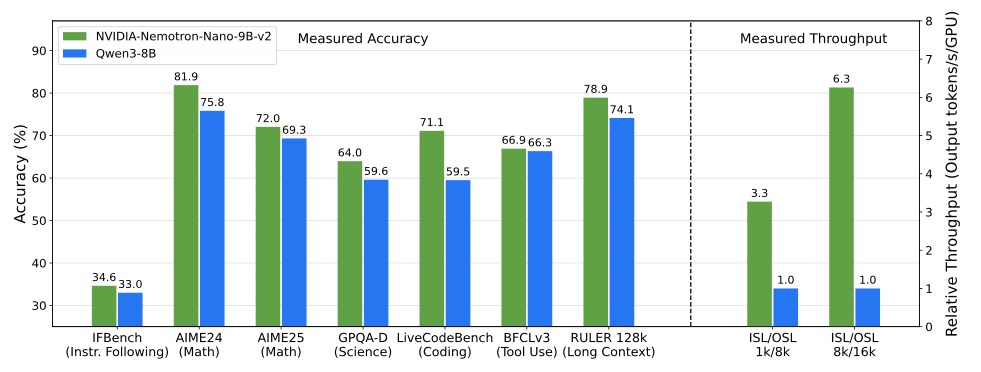
Nemotron-Nano-9B-v2 достигает сопоставимой или лучшей точности по сравнению с Qwen3-8B на бенчмарках рассуждений при увеличении пропускной способности в 3-6 раз для сценариев с большим объемом генерации. На AIME-2024 модель показывает 56.67 pass@32 против 20.00 у Qwen3-8B, на MATH-500 — 97.75 против 96.3, на GPQA-Diamond — 64.48 против 59.61.
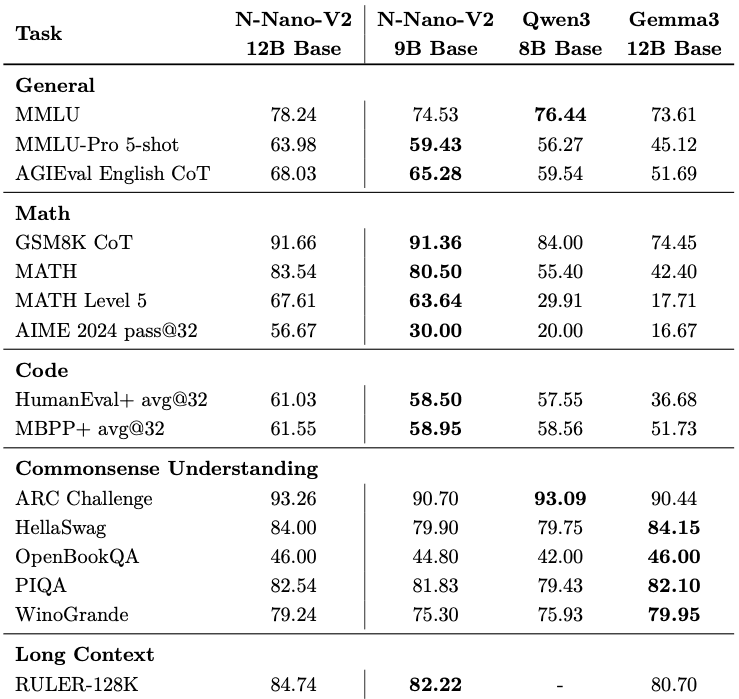
Для многоязычных математических задач (MGSM) средний результат составляет 84.80 против 64.53 у Qwen3-8B. На задачах длинного контекста RULER-128k показывает 82.22 балла.
Результаты оценки подчеркивают конкурентоспособную точность по сравнению с другими открытыми малыми моделями. Протестированная в режиме «рассуждение включено» с использованием набора NeMo-Skills, Nemotron-Nano-9B-v2 достигает 72.1 процента на AIME25, 97.8 процента на MATH500, 64.0 процента на GPQA и 71.1 процента на LiveCodeBench.

По всем направлениям Nano-9B-v2 показывает более высокую точность, чем Qwen3-8B — общая точка сравнения. Как показано в техническом отчете, модель рассуждений NVIDIA-Nemotron-Nano-v2-9B достигает сопоставимой или лучшей точности на сложных бенчмарках рассуждений, чем ведущая сопоставимая по размеру открытая модель Qwen3-8B при увеличении пропускной способности до 6 раз.
Особенности развертывания и использования
NVIDIA-Nemotron-Nano-9B-v2 представляет собой универсальную модель для задач рассуждения и диалога, предназначенную для использования на английском языке и языках программирования. Другие неанглийские языки (немецкий, французский, итальянский, испанский и японский) также поддерживаются. Модель оптимизирована для разработчиков, создающих AI-агентов, чатботы, RAG-приложения и другие AI-приложения.
Для корректной работы требуется указание флага —mamba_ssm_cache_dtype float32 для поддержания точности ответов. Без этой опции точность модели может снижаться. Модель поддерживает контекст до 128K токенов и работает с 15 языками и 43 языками программирования.
Контроль бюджета рассуждений
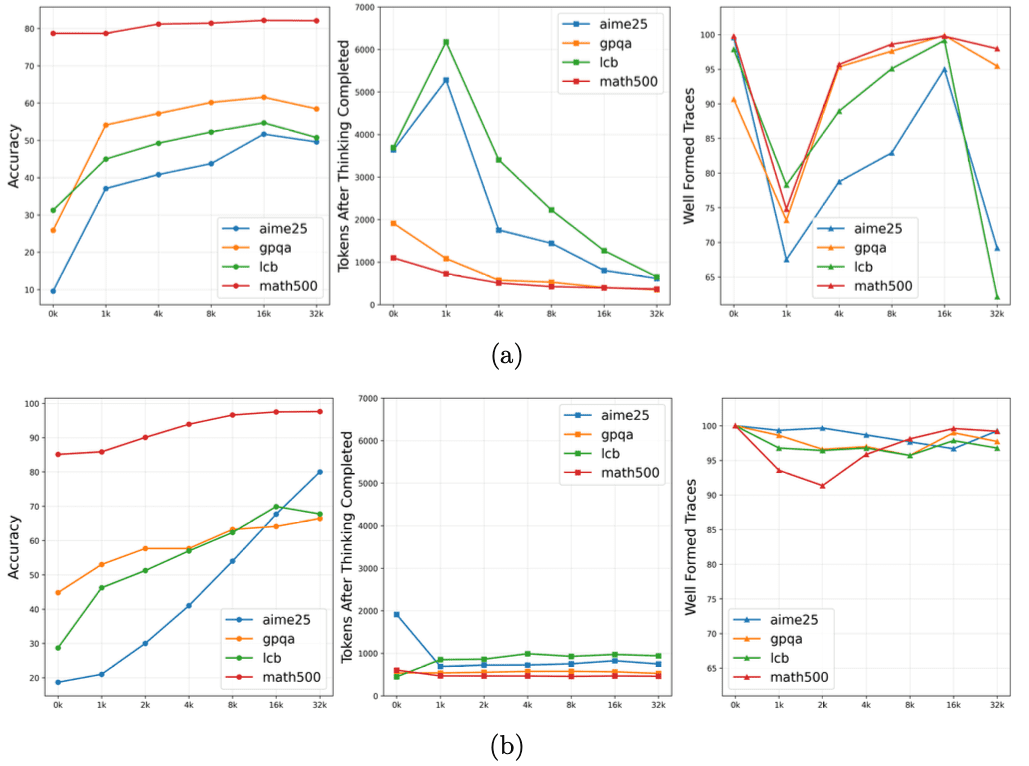
Особенность Nemotron Nano 2 — возможность указания количества токенов, которые модель может использования для размышлений в процессе инференса. Модель по умолчанию генерирует цепочку рассуждений перед предоставлением финального ответа, хотя пользователи могут переключать это поведение через простые управляющие токены, такие как /think или /no_think.
Модель также вводит управление «бюджетом мышления» во время выполнения, что позволяет разработчикам ограничить количество токенов, посвященных внутреннему рассуждению, прежде чем модель завершит ответ. Этот механизм направлен на балансировку точности и задержки, что особенно ценно для приложений поддержки клиентов или автономных агентов.
Лицензия
Модель Nano-9B-v2 выпущена под лицензией Nvidia Open Model License Agreement. Лицензия явно разработана для коммерческого использования. NVIDIA не заявляет права собственности на любые выходные данные, сгенерированные моделью, оставляя полные права и ответственность за разработчиком.
Nemotron-Nano-9B-v2 выпускается вместе с соответствующими базовыми моделями и большинством данных предварительного и постобучения на HuggingFace в рамках коллекции Nemotron-Pre-Training-Dataset-v1, содержащей 6.6 триллиона токенов премиальных данных веб-краулинга, математики, кода, SFT и многоязычных данных Q&A.