Исследовательская команда NVIDIA представила подход для генерации временных меток на уровне слов в модели синхронного перевода Canary. Точная информация о времени критически важна для создания синхронизированных субтитров. Исследователи опубликовали код в репозитории NeMo, а предварительно обученные контрольные точки модели доступны на Hugging Face.
Техническая проблематика
Традиционные гибридные методы, обученные с выравниванием фонем, естественным образом обеспечивают выравнивание между речевыми фреймами и текстом. В end-to-end фреймворках модели выполняют предсказание временных меток как отдельный проход в дополнение к обычному декодированию.
Методы вроде WhisperX выполняют детекцию речевой активности и отдельное принудительное выравнивание фонем для генерации временных меток на уровне слов. WhisperTimestamped работает в два этапа: сначала во время декодирования создаются веса перекрестного внимания между аудиосигналом и предсказанными словами, затем применяется алгоритм динамического выравнивания по времени для построения соответствий на уровне отдельных слов.
Архитектура решения
Для добавления способности предсказания временных меток исследователи ввели новый prompt <|timestamp|> для оригинальной модели Canary как новую задачу. Временные метки — токены с максимальной длительностью в 36 секунд.

Как показано на схеме выше, обучающие данные форматируются двумя способами: <|timestamp|> или <|notimestamp|>. В случае <|timestamp|> для каждого слова в предложении добавляются токены времени начала и окончания. Временные метки сначала получаются путем принудительного выравнивания речи и эталонного текста с использованием NeMo Forced Aligner (NFA) — специального инструмента для автоматического сопоставления аудио и текста, затем конвертируются в индексы фреймов с частотой 80 мс.
Временные токены представляются как <|t|>, где t — целое число от 0 до 450. Каждый шаг соответствует 80 миллисекундам, что дает максимальную длительность записи 36 секунд (450 × 80 мс = 36 секунд). Например, транскрипт с временными метками выглядит как: <|3|> classifying <|14|> <|15|> was <|16|>, где числа обозначают временные отметки в единицах по 80 мс. Каждый timestamp токен токенизируется точно в один ID в выходном пространстве токенизатора.
Двухэтапный процесс перевода речи
Для обучения автоматического перевода речи (AST) команда использует двухэтапный процесс. Сначала с помощью моделей машинного перевода создаются синтетические переводы из обычных ASR транскриптов.
Затем для получения временных меток выполняется двойное выравнивание: сначала NeMo Forced Aligner сопоставляет исходную речь с транскриптом на том же языке, определяя когда произносится каждое слово. После этого инструмент awesome-align находит соответствия между словами в исходном транскрипте и переводе. Таким образом временные метки «переносятся» с исходного языка на переведенный текст — каждое переведенное слово получает временные координаты соответствующего ему слова в оригинальной речи.
Эксперименты и результаты
Данные и архитектура
Команда взяла существующие обучающие данные модели Canary и создала из них новый датасет с временными метками: 4,275 часов речи для английского, 1,410 для немецкого, 1,397 для испанского и 1,795 часов для французского языков. Эти данные были специально размечены временными метками с помощью NeMo Forced Aligner для текущего исследования и составили 15% от всего ASR обучающего датасета. То есть они взяли уже имеющиеся аудиозаписи и транскрипты из датасета Canary, но добавили к ним временные метки с помощью NFA.
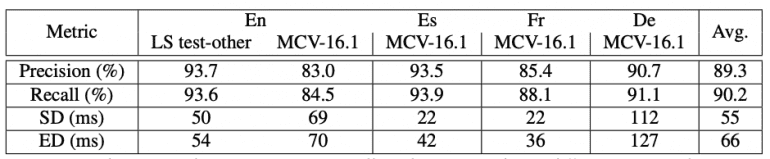
Результаты в таблице демонстрируют высокую точность предсказания временных меток. Модель достигает precision 93.7% для LibriSpeech test-other и 89.3% в среднем по всем языкам. Recall составляет 93.6% и 90.2% соответственно. Ошибки start time варьируются от 22 до 112 мс, а end time — от 36 до 127 мс.

Важно отметить минимальную регрессию качества ASR. Сравнение WER между baseline моделью Canary и новой моделью показывает деградацию всего около 0.2% в среднем при использовании prompt <|timestamp|>.
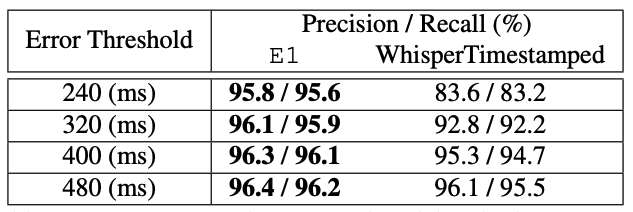
Сравнение с WhisperTimestamped на LibriSpeech test-other показывает превосходство предложенного подхода. При пороге 240 мс модель демонстрирует precision/recall 95.8%/95.6% против 83.6%/83.2% у WhisperTimestamped. При увеличении порога преимущество сохраняется.
Результаты для автоматического перевода речи

Предсказание временных меток для AST значительно сложнее, чем для ASR. Средние ошибки start и end time составляют 204 и 224 мс соответственно для 6 языковых пар. Производительность заметно хуже при переводе с немецкого на английский из-за различий в грамматической структуре.

Добавление временных меток для AST приводит к существенной регрессии качества перевода. Средняя деградация составляет 4.4 BLEU точки и 2.6 COMET балла по сравнению с baseline моделью.
Практические примеры

Пример перевода с английского на немецкий демонстрирует способность модели изучать синтаксическое переупорядочивание. Модель корректно предсказывает немецкий глагол hinterherbleiben в конце предложения с временными метками, соответствующими английскому lag behind, следуя структуре SOV немецкого языка.

Интересное наблюдение: модель, обученная только на ASR данных с временными метками, демонстрирует способность предсказывать разумные временные метки для AST. Пример французско-английского перевода показывает корректное соответствие временных меток между языками, несмотря на отсутствие AST данных в обучении.
Заключение
Предложенный data-driven подход с teacher-student обучением представляет первое исследование предсказания временных меток на уровне слов для автоматического перевода речи. Метод достигает precision и recall в диапазоне 80-90% с ошибками 20-120 мс для ASR при минимальной WER деградации. Для AST система достигает ошибок около 200 мс, но с существенной деградацией качества перевода, что указывает на направления для будущих исследований.