
Новый Популяционный метод аугментации (Population based augmentation, PBA) сравним по качеству с текущим state-of-the-art методом AutoAugment от Google, однако работает в тысячу раз быстрее, что позволяет широко использовать его разработчикам. В эксперименте на датасете CIFAR-10, удалось увеличить показатели по сравнению с state-of-the-art методом. Реализация метода доступна на github.
Проблема
Ключевой проблемой в использовании аугментации данных для обучения нейронной сети является выбор эффективной политики аугментации из большого пространства поиска операций-кандидатов. Правильно выбранная политика аугментации может привести к значительным улучшениям обобщений; однако современные подходы, такие как AutoAugment, в вычислительном отношении невозможны для обычного пользователя.
AutoAugment — очень дорогой алгоритм, который требует обучения 15 000 моделей сходимости, чтобы получить достаточно выборок для решения, основанного на обучении с подкреплением. Никакие вычисления не распределяются, и для обучения для ImageNet требуется 5000 часов графического процессора NVIDIA Tesla P100, а для обучения для CIFAR-10 — 5000 часов GPU. Например, при использовании графических процессоров P100 Google Cloud для CIFAR потребуется около 7500 долларов, а для ImageNet — 37 500 долларов!
Решение
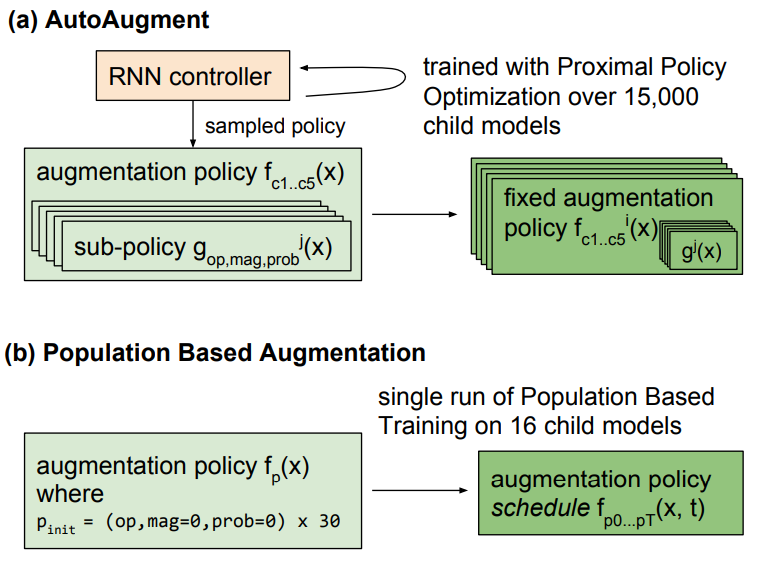
PBA использует алгоритм обучения на основе популяции для создания расписания политики аугментации, которое можно адаптировать в зависимости от текущей эпохи обучения. В этом ее отличие от фиксированной политики аугментации, которая применяет те же преобразования, но независимо от текущего номера эпохи.
Результаты
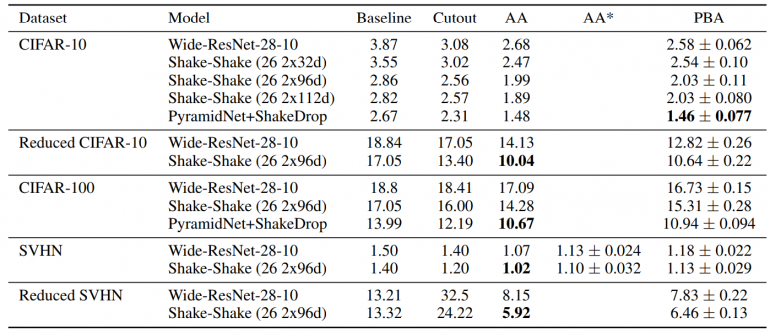
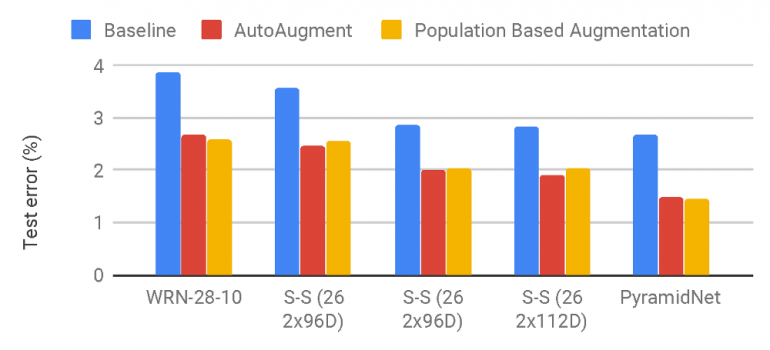
Ошибка на тестовой выборке (%) на CIFAR-10, CIFAR-100 и SVHN. Чем ниже значение — тем лучше. Средняя итоговая ошибка на тестовой выборке считалась на 5 случайных инициализациях модели. Код для оценивания AA на SVHN не был выпущен, поэтому различия между реализациями могли повлиять на результаты. Таким образом, были сообщены AA* из переоценки разработчиков.
