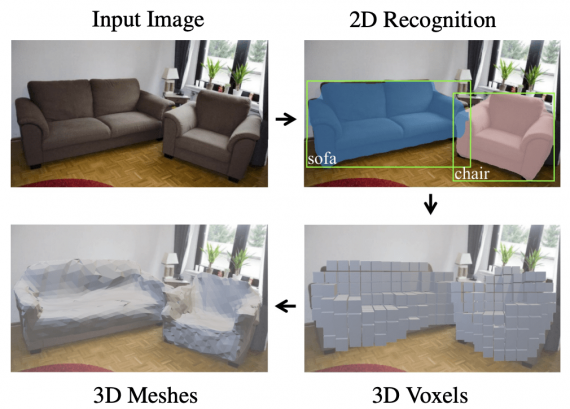
Mesh R-CNN — это нейросетевая архитектура, которая для объектов входного изображения предсказывает их форму. Модель была описана в работе от Facebook AI Research (FAIR). По метрикам Mesh R-CNN обходит существующие state-of-the-art подходы по моделированию 3D формы объектов.
Последние исследования в компьютерном зрении фокусировались на распознавании объектов в 2D пространстве. В большинстве работ игнорировалась 3D структура объектов. Ранние модели, предсказывающие 3D форму объектов, не были обучены определять форму на реальных изображениях для множества объектов одновременно. Исследователи объединили последние решения из обоих задач и представили Mesh R-CNN.
Модель принимает на вход изображение, классифицирует объекты на изображении и для всех объектов определяет их форму в формате полигональной сетки (mesh). Чтобы ухватить разнообразие форм объектов, модель сначала предсказывает воксели объекта, которые затем преобразуются в сетку. Полигональная сетка — это понятие из 3D моделирования, которое используется для определения совокупности вершин, рёбер и граней, которые описывают форму объекта в 3D пространстве.
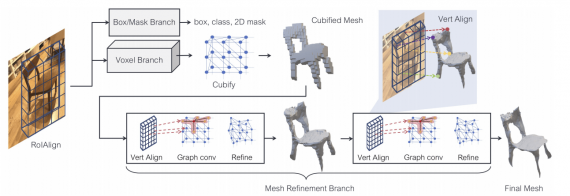
Архитектура модели
Mask R-CNN — это стандартный подход для распознавания объектов на 2D изображении. Mesh R-CNN — это end-to-end модель, которая расширяет Mask R-CNN с помощью блока для предсказания полигональной сетки. Модель была обучена на датасете Pix3D.
Процесс обучения модели:
- Стандартная Mask R-CNN предсказывает класс объекта, его границы на изображении и 2D маску;
- Для объекта определяется его приблизительная форма с помощью блока с предсказанием вокселей;
- Приблизительная форма уточняется с помощью графовой сверточной нейросети и дополнительных модификаций;
- На выходе отдается сетка для объекта
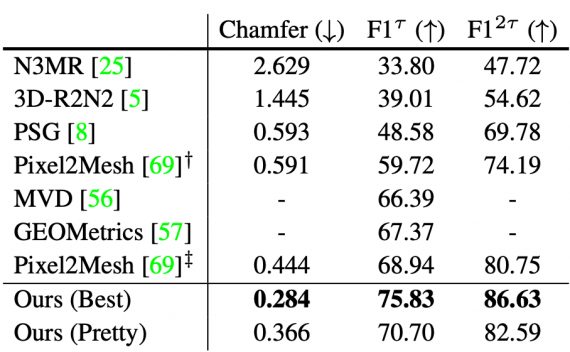
Оценка работы модели
Блок предсказания формы (mesh predictor) валидировался на датасете ShapeNet. Затем результаты модели сравнивались с результатами конкурирующих архитектур на данных Pix3D. Ниже видно, что полная модель значительно обходит более ранние архитектуры на задаче предсказания 3D формы объектов на изображении.