
Исследователи из Чжэцзянского университета представили R1-Onevision, открытую мультимодальную модель рассуждений с 7 миллиардами параметров. R1-Onevision решает сложные математические, научные и инженерные задачи с показателями производительности, превосходящими GPT-4o в математике и рассуждениях.
Модель связывает визуальное восприятие и логический вывод с помощью нового подхода, основанного на формальном языке. R1-Onevision преобразует информацию на основе пикселей в структурированные представления, о которых можно систематически рассуждать.
Исследователи опубликовали в открытом доступе датасет R1-Onevision, бенчмарк и модель. Все ресурсы доступны на GitHub, Hugging Face, есть веб-демо.

Техническая архитектура модели
R1-Onevision построена на базе архитектуры Qwen2.5-VL-Instruct и была разработана с использованием библиотеки с открытым исходным кодом LLama-Factory с оптимизированными параметрами для задач на рассуждение.
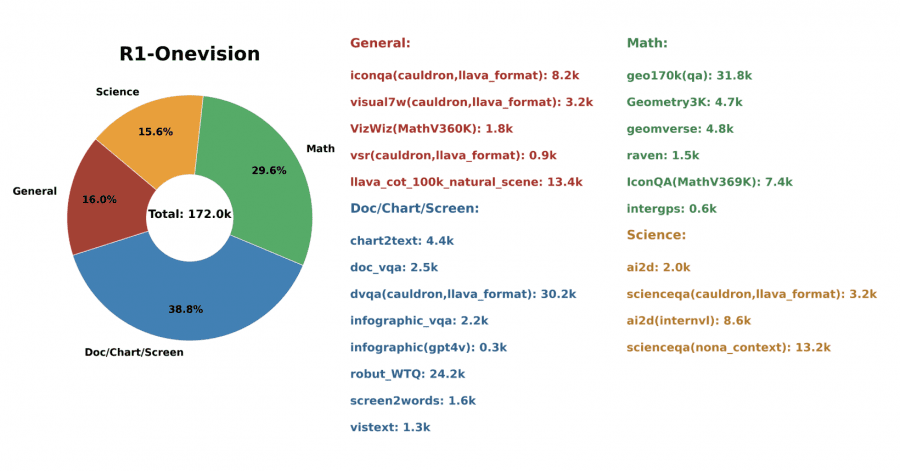
Первый ключевой компонент метода — построение датасета R1-Onevision.
Процесс создания датасета состоит из четырех стадий:
- различные типы изображений были собраны и отфильтрованы по качеству и релевантности для задач рассуждения;
- изображения прошли формальную аннотацию с использованием комбинации инструментов: GPT-4o для создания текстовых подписей и перевода визуальных элементов в формальные представления, Grounding DINO для предоставления пространственных координат объектов и EasyOCR для извлечения текста из изображений.
- модель DeepSeek-R1 сгенерировала начальные рассуждения Chain-of-Thought на основе формальных текстовых описаний. Ролевой подход имитировал визуальное понимание путем итеративного уточнения.
- GPT-4o выполняет контроль качества для фильтрации цепочек рассуждения, содержащих логические ошибки или несоответствия.
Полученный датасет содержит структурированные записи с уникальными идентификаторами, путями к изображениям, эталонными значениями, источниками данных, диалогами, фильтрами валидности и метриками оценки качества.
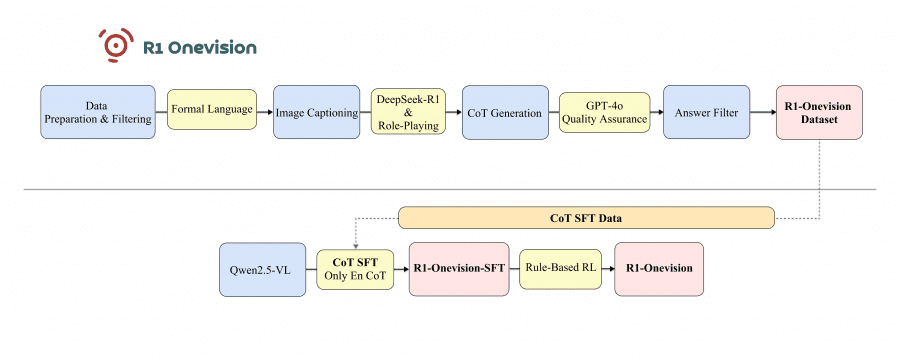
Фреймворк обучения с подкреплением на основе правил (Rule-Based RL), второй ключевой компонент метода, совершенствует процесс рассуждения модели путем внедрения явных правил оценки точности и структуры ответов. Этот подход объединяет сильные стороны обучения с подкреплением с инструкциями на основе правил и состоит из 5 компонентов:
- Основа: процесс начинается с модели, которая уже прошла Supervised Fine-Tuning (SFT) на датасете R1-Onevision. Это обеспечивает базовые возможности для мультимодальных рассуждений.
- Интеграция правил: вместо использования общих моделей вознаграждения или обратной связи от людей (как в типичных подходах RLHF), эта система включает явные, специфичные для предметной области правила, которые определяют верное рассуждение.
- Проверка структуры рассуждения: правила гарантируют, что модель следует логическим шагам в связной последовательности, делает обоснованные математические или научные выводы, поддерживает последовательные схемы рассуждения, приходит к точным заключениям.
- Проверка точности и формата, корректности вычислений, принципов логических рассуждений, структуры и правильности интерпретации информации.
- Процесс обучения: во время обучения модель получает вознаграждения, когда она придерживается этих правил, и штрафы, когда нет, постепенно оптимизируя свои процессы рассуждения в соответствии с принципами структурированного мышления.
Ключевое преимущество этого подхода заключается в том, что он оптимизирует не просто общую производительность, а конкретно нацелен на возможности структурированного рассуждения, необходимые для решения сложных визуально-математических задач. Кодируя экспертные знания в форме правил, модель учится следовать схемам рассуждения, которые доказали свою эффективность при решении сложных задач.
Диаграмма иллюстрирует пайплайн разработки модели R1-Onevision, разделенный на две основные фазы:
Результаты и сравнения
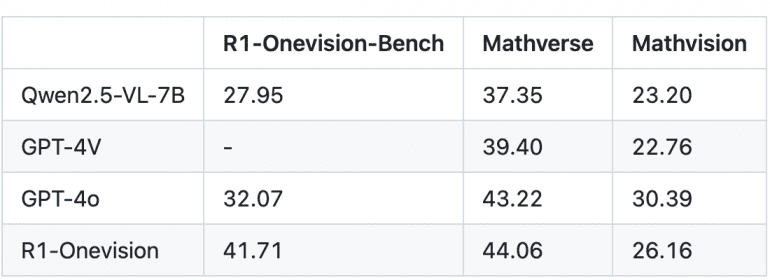
R1-Onevision демонстрирует производительность, превосходящую GPT-4o, GPT-4V и Qwen2.5-VL-7B на нескольких бенчмарках:
- На R1-Onevision-Bench: R1-Onevision достигла показателя 41.71, значительно превосходя GPT-4o (32.07) и Qwen2.5-VL-7B (27.95)
- На Mathverse: R1-Onevision получила 44.06, превосходя GPT-4o (43.22), GPT-4V (39.40) и Qwen2.5-VL-7B (37.35)
- На Mathvision: R1-Onevision достигла 26.16, показывая результаты между GPT-4o (30.39) и GPT-4V (22.76)
Модель демонстрирует особые сильные стороны в распознавании закономерностей, решении математических задач, рассуждениях в геометрии, физических расчетах, анализе схем и алгоритмических задачах. Документированные примеры показывают ее способность систематически прорабатывать сложные цепочки рассуждений для достижения точных выводов в различных проблемных областях.
Эти результаты подтверждают эффективность подхода к визуальным рассуждениям на основе формального языка и Rule-Based RL в улучшении возможностей мультимодальных рассуждений за пределами возможностей state-of-the-art моделей.







