DeepMind представила языковую модель RETRO, в которой реализована схема обучения, основанная на использовании внешней памяти. RETRO демонстрирует сравнимые с GPT-3 результаты несмотря на то, что она имеет в 25 раз меньше параметров.
За два года, прошедшие с тех пор, как OpenAI выпустила свою языковую модель GPT-3, большинство крупных компаний, включая Google, Facebook, Microsoft и несколько китайских корпораций, создали свои аналоги, которые могут генерировать текст, общаться с людьми, отвечать на вопросы и многое другое.
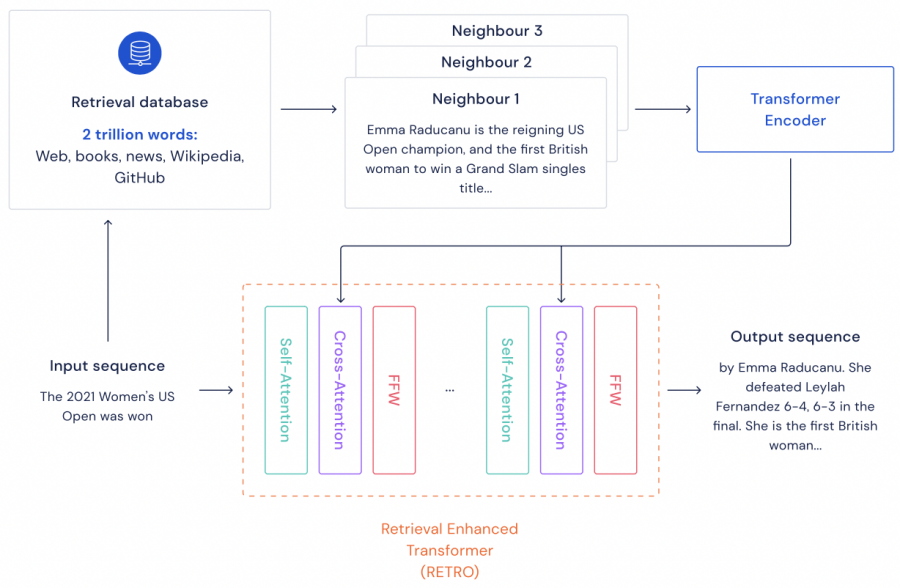
Называемая RETRO (Retrieval-Enhanced Transformer), модель DeepMind демонстрирует эффективность, сравнимую с нейронными сетями, которые в 25 раз больше RETRO. Это сокращает затраты, необходимые для обучения моделей. Особенностью модели DeepMind является внешняя память в виде обширной базы данных, содержащей отрывки текста, которые она использует как шпаргалку при создании новых предложений. Разработчики DeepMind утверждают, что база данных облегчает анализ того, что узнала их модель, для последующей борьбы с предвзятостью.
Языковые модели генерируют текст, предсказывая, какие слова будут следующими в предложении или разговоре. Чем больше модель, тем больше информации она может узнать во время обучения, что делает ее прогнозы лучше. Например, GPT-3 имеет 175 миллиардов параметров, а модель Microsoft — 530 миллиардов параметров. Но большие модели также требуют огромных вычислительных мощностей для обучения.
С помощью RETRO DeepMind пытается сократить расходы на обучение без уменьшения объема обучающей выборки. Исследователи обучили модель на датасете, состоящем из новостных статей, текстов Википедии, книг и текста из GitHub. Датасет содержит тексты на 10 языках, включая английский, испанский, немецкий, французский, русский, китайский, суахили и урду.
Нейронная сеть RETRO имеет всего 7 миллиардов параметров. Но система компенсирует это с помощью базы данных, содержащей около 2 триллионов отрывков текста. Нейронная сеть и база данных обучаются одновременно.
Когда RETRO генерирует текст, она использует базу данных для поиска и сравнения отрывков, похожих на тот, который он пишет, что делает его прогнозы более точными. Передача части памяти нейронной сети на аутсорсинг в базу данных позволяет RETRO использовать меньше вычислительных ресурсов.
База данных также может быть обновлена без переобучения нейронной сети. Это означает, что новая информация может быть быстро добавлена, а устаревшая или ложная — удалена. В DeepMind утверждают, что такие системы, как RETRO, более прозрачны по сравнению с моделями-черными ящиками, такими как GPT-3.