
Исследователи из Show Lab Национального университета Сингапура и ByteDance представили Show-o2 — второе поколение мультимодальной модели, которая демонстрирует превосходные результаты в задачах понимания и генерации изображений и видео. Show-o2 использует улучшенную архитектуру с dual-path механизмом, которая позволяет 7B модели превосходить даже 14B конкурентов при меньших вычислительных затратах. Модель достигает конкурентоспособной производительности, используя в 2-3 раза меньше обучающих данных по сравнению со state-of-the-art моделями. Код модели доступен на Github.
Архитектурные инновации
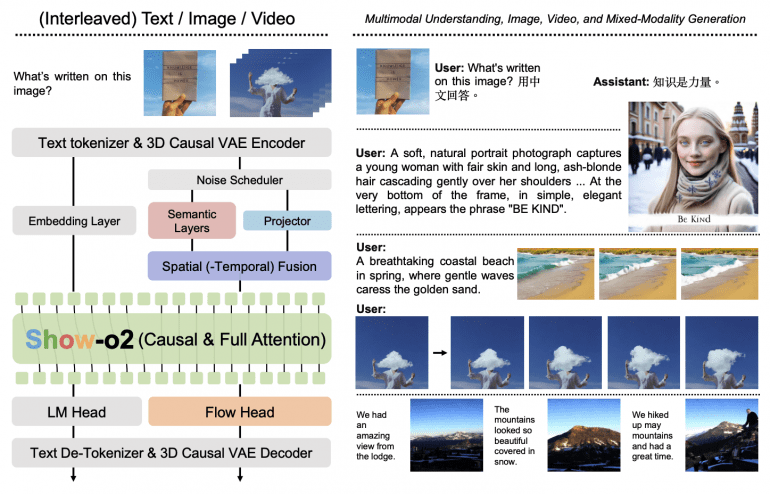
В основе архитектуры Show-o2 лежит принципиально новый подход к созданию унифицированных визуальных представлений. Модель использует трехмерное каузальное VAE пространство, которое масштабируемо поддерживает как изображения, так и видео через механизм двойной (dual-path) обработки пространственно-временного слияния (Spatial(-Temporal) Fusion).
Унифицированное визуальное представление строится через комбинацию семантических слоев и проектора. Семантические слои, основанные на архитектуре SigLIP с новым слоем встраивания патчей размером 2×2, извлекают высокоуровневые контекстуальные представления. Проектор сохраняет полную низкоуровневую информацию из визуальных скрытых представлений.
Процесс слияния объединяет высокоуровневые и низкоуровневые представления через конкатенацию по размерности признаков с применением RMSNorm и двух MLP-слоев. Механизм пространственно-временного слияния обрабатывает как пространственную, так и временную информацию для создания унифицированных визуальных представлений.
Flow Head использует несколько слоев трансформера с модуляцией временного шага через блоки adaLN-Zero для предсказания скорости через алгоритм flow matching. Во время обучения модель одновременно применяет предсказание следующего токена к языковой голове и flow matching к голове потокового сопоставления с балансировкой потерь через весовой коэффициент.
Двухэтапная стратегия обучения
Show-o2 использует инновационную двухэтапную стратегию обучения, которая эффективно сохраняет языковые знания при одновременном развитии способностей визуальной генерации.
Этап-1 включает обучение только обучаемых компонентов: проектора, пространственно-временного слияния и головы потокового сопоставления на приблизительно 66 миллионах пар изображение-текст с прогрессивным добавлением чередующихся данных и пар видео-текст.
Этап-2 включает тонкую настройку полной модели с использованием 9 миллионов высококачественных мультимодальных instruction-данных и 16 миллионов высококачественных генеративных данных, отфильтрованных из 66 миллионов пар изображение-текст.
Для масштабирования исследователи используют предобученную flow head от 1.5B модели для более крупной 7B модели, вводя легковесную MLP трансформацию для выравнивания размера скрытых состояний.
Экспериментальные результаты
Ключевые достижения Show-o2 включают превосходство над моделями аналогичного размера: 1.5B версия показывает лучшие результаты на MME-p (1450.9) и MMMU-val (37.1), а 7B версия устанавливает новые рекорды на MME-p (1620.5), MMMU-val (48.9) и MMStar (56.6). В задачах генерации изображений модель демонстрирует впечатляющие результаты на GenEval (0.73 для 1.5B, 0.76 для 7B) и DPG-Bench (85.02 для 1.5B, 86.14 для 7B), используя при этом значительно меньше обучающих данных по сравнению с конкурентами.
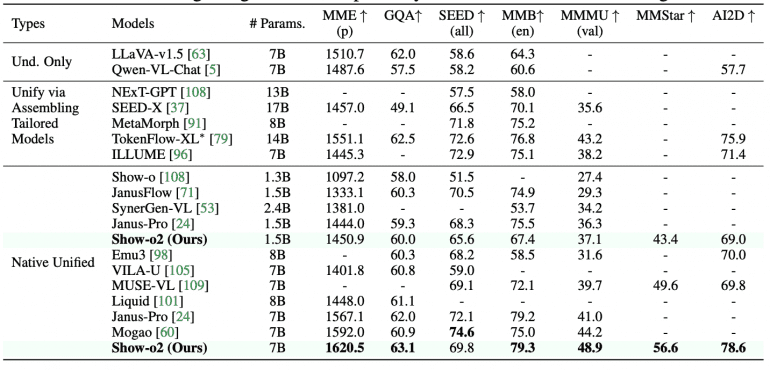
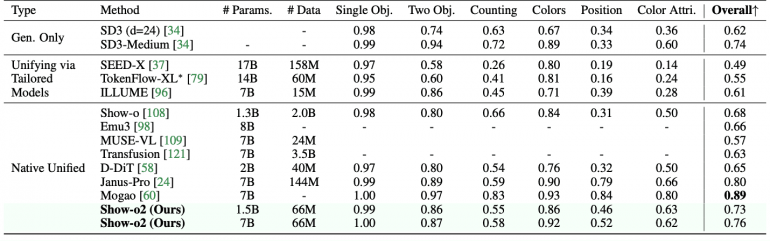
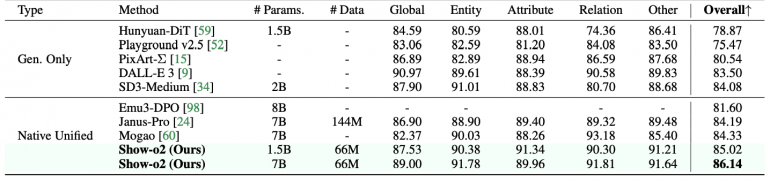
На бенчмарках генерации изображений Show-o2 превосходит большинство подходов, включая TokenFlow-XL, Show-o, Emu3 и Transfusion на GenEval. При сравнении с Janus-Pro, которая была обучена на значительно большем датасете (144M пар изображение-текст), Show-o2 достигает конкурентоспособных результатов, используя только 66M пар.
В задачах генерации видео модель с всего 2B параметрами превосходит модели с более чем 6B параметрами, такие как Emu3 и VILA-U. Show-o2 демонстрирует конкурентоспособную производительность по сравнению с CogVideoX и Step-Video-T2V на VBench бенчмарке.
Практические применения
Show-o2 демонстрирует выдающиеся возможности смешанно-модальной генерации через чередующиеся последовательности изображение-текст. При тонкой настройке модель может предсказывать токены [BOI] для начала генерации изображений, при обнаружении которых к последовательности добавляется шум для постепенной генерации изображения.
Модель поддерживает:
- Высококачественную генерацию изображений с детальным следованием текстовым инструкциям;
- Генерацию видео из текста и изображений с консистентными кадрами;
- Мультимодальное понимание на английском и китайском языках;
- Смешанно-модальную генерацию для визуального сторителлинга.
Абляционные исследования подтверждают эффективность механизма пространственно-временного слияния, показывая улучшения как в мультимодальном понимании (MME-p: +23.1, GQA: +1.4), так и в генерации (FID-5K: -1.3). Второй этап обучения критически важен, обеспечивая значительные улучшения на GenEval (+0.10) и DPG-Bench (+1.42).
Дополнительные примеры text-to-video и image-to-video генерации:

Технические характеристики
Show-o2 выпускается в двух конфигурациях, основанных на Qwen2.5-1.5B-Instruct и Qwen2.5-7B-Instruct с 3D causal VAE из Wan2.1 с восьмикратной и четырехкратной пространственной и временной компрессией соответственно. Обучение 1.5B модели занимает приблизительно полтора дня на 64 H100 GPU, в то время как 7B модель требует около двух с половиной дней на 128 H100 GPU.
Исследование демонстрирует возможность создания высокоэффективных унифицированных мультимодальных моделей через комплексную оптимизацию архитектуры.








