
Распознавание лицевых точек — основа для выполнения задач по распознаванию лиц, анимации лиц и создания цифровых копий. Корректное обнаружение лендмарок – все еще не решенная проблема. Несмотря на работу, проведенную по обнаружению лицевых точек на основе изображений, детекторы допускают погрешности. При малом смещении может быть большая дисперсия по двум причинам:
- Недостаток обучающих примеров;
- Неточные описания,
поскольку ручное аннотирование ограничено в точности и согласованности. Методы, предназначенные для обнаружения лиц на видео, используют как обнаружение, так и отслеживание для устранения дрожания сигнала и увеличения точности. Но такой подход требует описания каждого кадра в видео.
В исследовании описывается подход к обучению без учителя для решения описанной проблемы. Обучение регистрацией (Supervision-by-Registration или SBR) улучшает функцию потерь обучением на данных, автоматически полученных из неразмеченных видео. Для этого предлагается согласовать:
- положение точки в смежных кадрах;
- регистрацию (оптического потока), как способа обучения.
Фреймворк
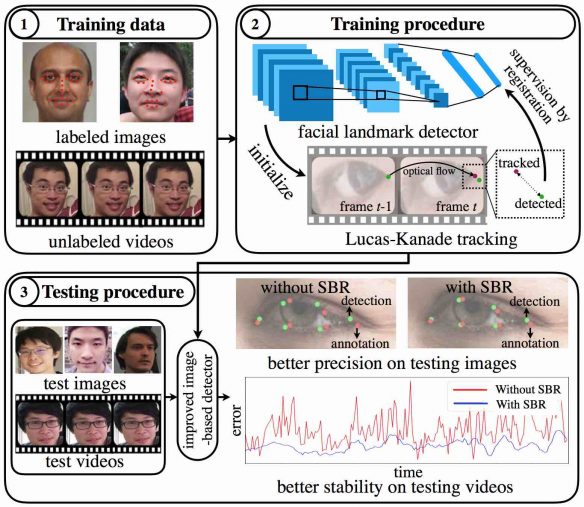
SBR представляет собой сквозную обучаемую модель, состоящую из двух компонентов: общего детектора, построенного на сверточных нейронных сетях и дифференциального метода Лукаса – Канаде (LK). Во время прямого прохода LK принимает обнаруженные точки из предыдущего кадра и оценивает их местоположения в текущем кадре. Затем отслеживаемые точки сравниваются с обнаруженными на текущем кадре. Функция регистрационных потерь (registration loss) определяется как смещение между ними. При обратном проходе градиент от функции потерь обратно распространяется через LK для поддержания временной согласованности в детекторе. Конечный результат метода — улучшенная основанная на изображениях модель обнаружения лицевых точек, которая использует большое количество неразмеченных видео для достижения более высокой точности как на изображениях, так и на видео, а также для получения более стабильных прогнозов в случае с видео. SBR вносит более обучающие сигналы из регистрации, что повышает точность детектора. Суммируя, SBR имеет следующие преимущества:
- SBR может повысить точность обнаружение лицевых точек на изображениях и видео методом обучения без учителя.
- Поскольку обучающий сигнал SBR получен не из аннотаций, SBR может использовать очень большое количество неразмеченного видео для улучшения модели.
- SBR может быть обучен c применением широко используемого метода обратного распространения ошибки.
Архитектура нейросети
SBR состоит из двух дополнительных частей: детектор, распознающий основные точки лица, и алгоритм LK. Обучение SBR с двумя дополнительными функциями потерь выглядит следующим образом. Функция потерь на первом этапе использует информацию из одного изображения для создания разметки и обучения наилучшей версии модели. Все детекторы принимают на вход изображение l и выдают координаты лицевых точек, то есть D(I) = L. Квадратичная функция потерь (L^2) рассчитывается на полученных координатах L и реальных метках L*.
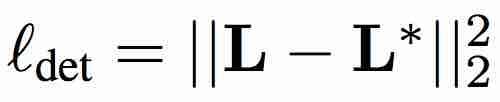
Используя метод Лукаса – Канаде (LK), можно оценить временную согласованность при помощи функции регистрационных потерь (registration loss). Эти потери могут быть рассчитаны методом обучения без учителя для усиления детектора. Это реализуется методом обратного распространения ошибки между входными данными и выходными из LK алгоритма. Во время прямого прохода вычисляется функция регистрационных потерь, в то время как во время обратного оценивается надежность работы алгоритма LK. Функция потерь имеет следующий вид:
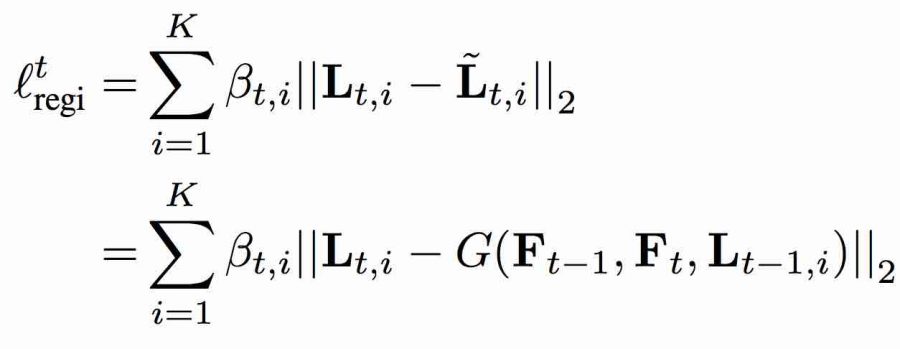
Полная функция потерь: Пусть N – число объектов для обучения с реальными метками. Для краткости, предположим, есть только одно неразмеченное видео с T кадрами. Тогда полная функция потерь SBR выглядит следующим образом:
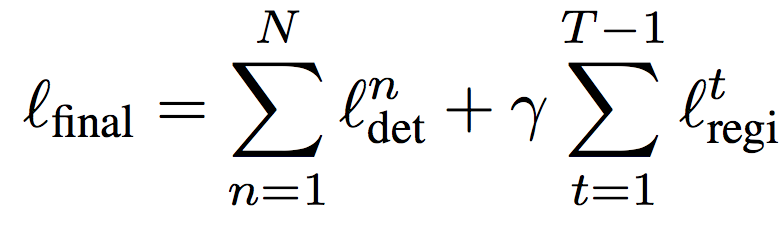
Первым детектором является CPM, который использует предварительно обученные модели ImageNet для извлечения признаков. Для генерации признаков используются первые четыре сверточных слоя VGG- и только три слоя CPM осуществляют прогноз тепловой карты. Изображения лиц обрезаются и изменяются до размеров 256 × 256 для предварительной обработки. Мы обучали CPM с батчами (сериями) размера 8 в течение 40 эпох (циклов) в общей сложности. Скорость обучения начиналась с 0,00005 и уменьшалась на 0,5 в 20-й и 30-й эпохах.
Второй детектор – обычная регрессионная сеть, обозначаемая Reg. VGG-16 используется как базовая модель, она меняет выходные нейроны последнего полносвязного слоя на K × 2, где K – число локаций лицевых точек. Входные изображения обрезаются до размера 224 × 224 для этой регрессии.
Используемые для сравнения наборы данных: 300-W, AFLW, youtube-face, 300-VW и YouTube Celebrities. Результаты SBR, показанные на рисунке ниже, получены как при помощи Reg (на основе регрессии), так и с использованием CPM (на основе тепловой карты) на AFLW и 300-W. Для оценки качества работы алгоритмов на изображениях была выбрана нормализованная средняя ошибка (NME).
Результаты
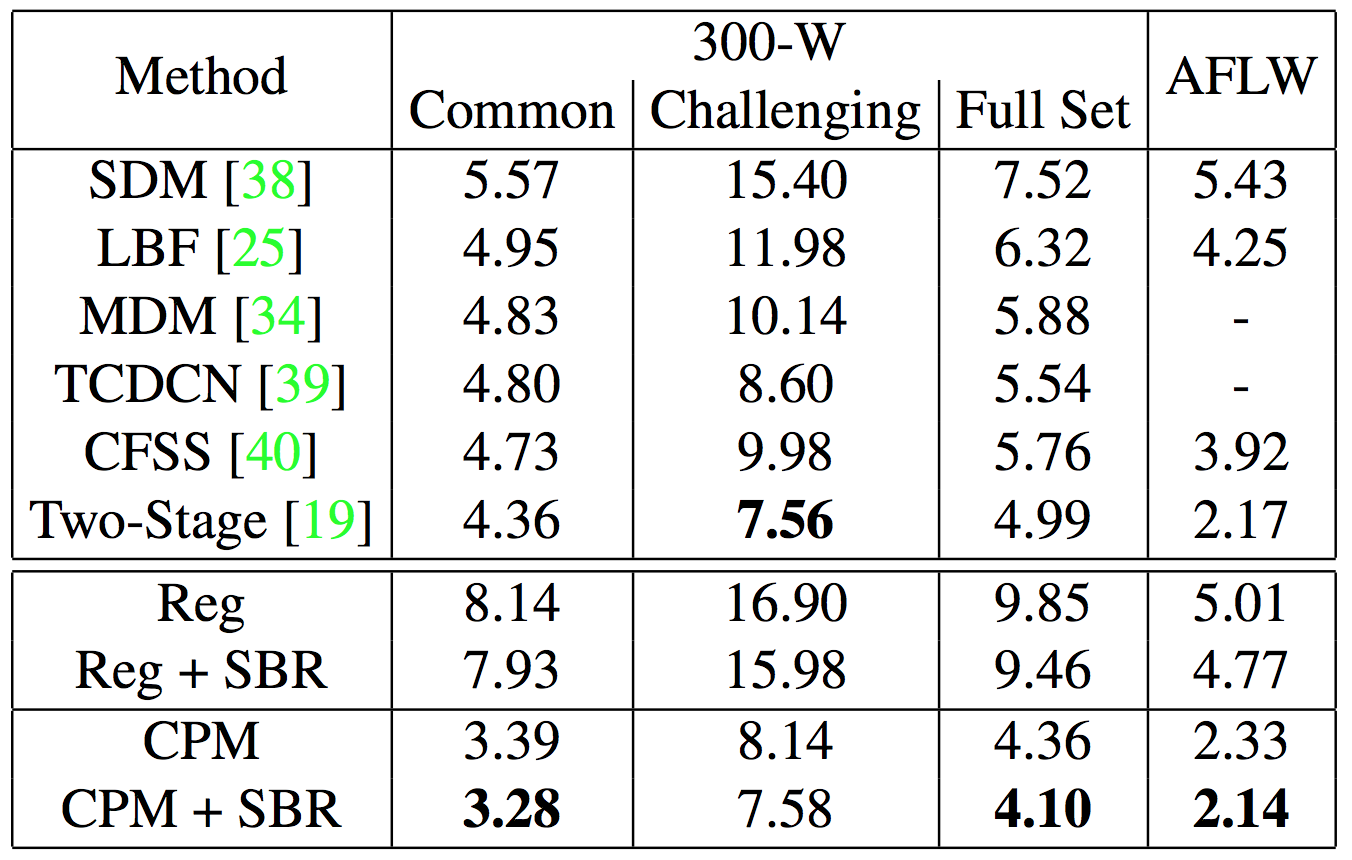

В сухом остатке

SBR демонстрирует результаты современного уровня на выбранных датасетах со следующими преимуществами:
- Модель не полагается на сделанные вручную аннотации, которые могут быть неточными;
- Детектор больше не ограничивается количеством и качеством аннотаций.
- Метод обратного распространения через слой LK позволяет получать более точные градиентные обновления, чем при самообучении.
Кроме того, эксперименты на синтетических данных показывают, что ошибки аннотации в наборе оценок могут привести к тому, что хорошо работающая модель будет производить впечатление, будто она плохо работает. Избегайте неточных аннотаций при интерпретации результатов.



