Исследовательская группа из Шанхайского университета Цзяо Тонг и Шанхайской лаборатории искусственного интеллекта представила Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) — новый подход к обучению крупных мультимодальных моделей агентным возможностям. Методика демонстрирует значительные улучшения в способности моделей использовать внешние инструменты для решения сложных визуальных задач. Код доступен на Github.
Мультимодальные агенты
Visual-ARFT устраняет критический пробел в развитии мультимодальных систем искусственного интеллекта. В то время как языковые модели достигли значительного прогресса в агентных способностях, включая вызов функций и интеграцию инструментов, развитие мультимодальных агентов остается менее изученным.
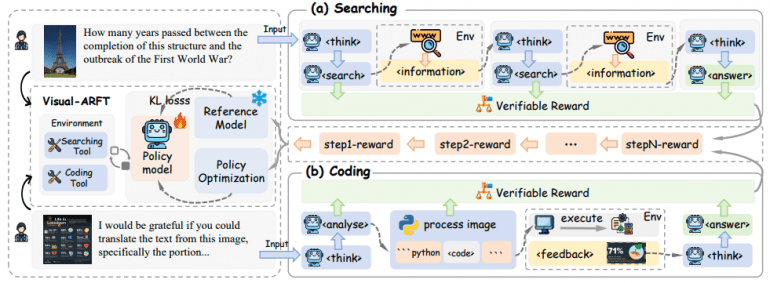
Фреймворк применяет обучение с подкреплением на основе верифицируемых вознаграждений для обучения Large Vision-Language Models (LVLM) двум критически важным сценариям:
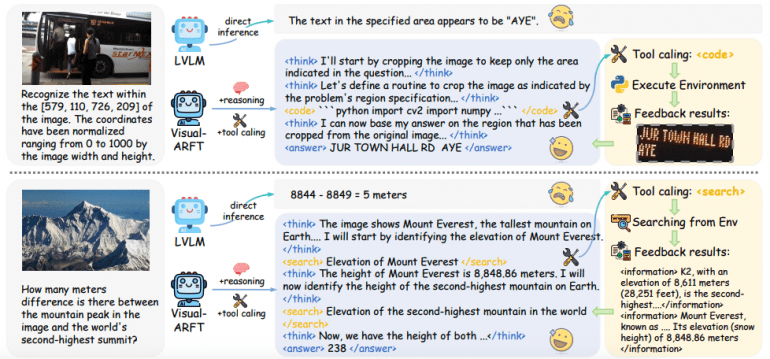
Агентный поиск: модель планирует, декомпозирует исходную задачу и извлекает информацию из внешних источников для ответа на сложные мультимодальные многошаговые VQA вопросы.
Агентное программирование: модель рассуждает о задаче, пишет и выполняет код для обработки изображений и решения сложных задач визуального анализа.
Техническая реализация
Система вознаграждений
Visual-ARFT использует модульную систему верифицируемых вознаграждений:
Format Reward обеспечивает соблюдение предопределенного формата выходных данных, включая теги <think>, <search> и <code>. Это стимулирует структурированное пошаговое рассуждение и корректное использование инструментов.
Accuracy Rewards оценивают качество окончательных ответов с использованием F1-score, семантическое сходство для поисковых запросов и выполнимость сгенерированного кода.
Алгоритм обучения
Исследователи применяют Group Relative Policy Optimization (GRPO) для обновления политики модели на основе обратной связи от вознаграждений. KL-дивергенция предотвращает чрезмерное отклонение обновленной политики от референсной модели.
Multimodal Agentic Tool Bench (MAT)
Для поддержки обучения и оценки команда представила MAT — бенчмарк, включающий два подмножества:
MAT-Search: 150 высококачественных мультимодальных многошаговых VQA примеров, требующих внешнего поиска знаний.
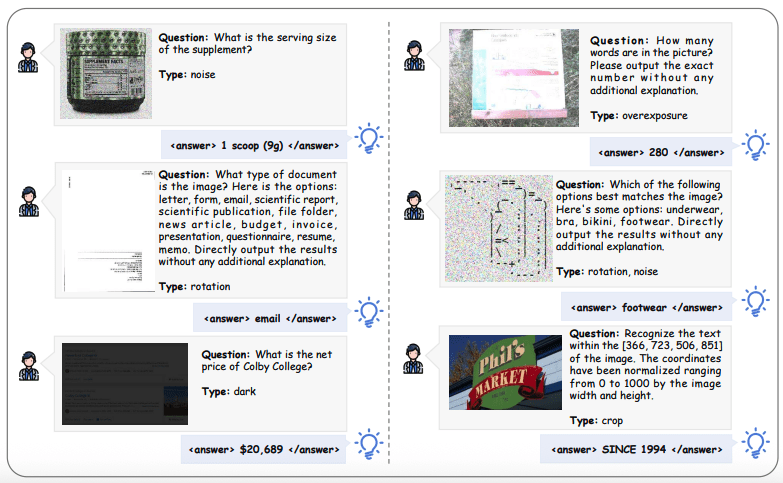
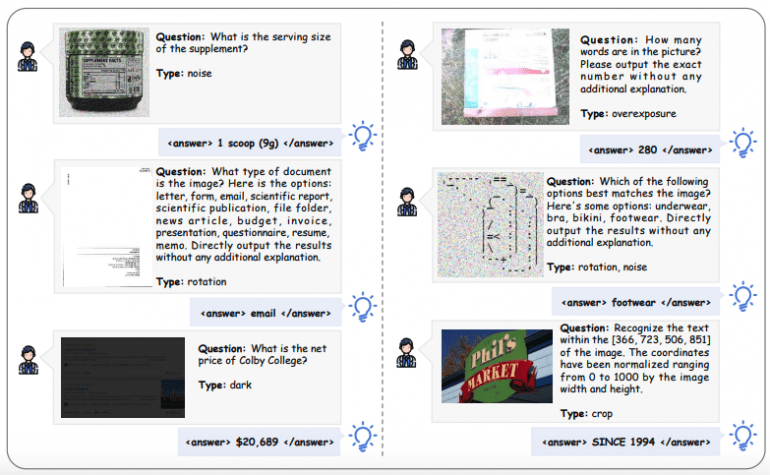
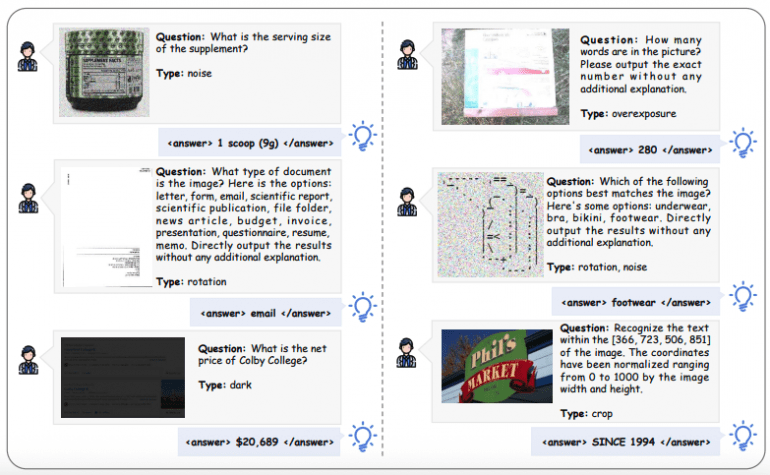
MAT-Coding: 200 примеров с различными типами искажений изображений (поворот, затемнение, размытие, шум), требующих предварительной обработки через код.
Количественные результаты
Эффективность Visual-ARFT подтверждается впечатляющими эмпирическими данными:
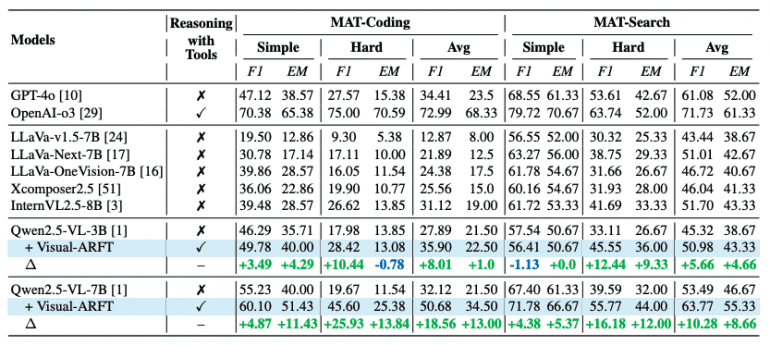
На MAT-Coding модель Qwen2.5-VL-7B с Visual-ARFT достигает улучшений +18.56% F1 и +13.00% EM по сравнению с базовой версией, превосходя GPT-4o.
На MAT-Search та же модель демонстрирует прирост +10.28% F1 и +8.66% EM.
При оценке на внешних многошаговых QA бенчмарках Visual-ARFT показывает устойчивую генерализацию с приростом +29.3% F1 и +25.9% EM на 2WikiMultihopQA и HotpotQA.
Практическое применение
Подход демонстрирует несколько ключевых преимуществ:
Контроль процесса обучения: разработчики могут точно контролировать информацию, с которой AI сталкивается во время обучения, что приводит к более надежным результатам.
Гибкость фреймворка: Visual-ARFT совместим с широко используемыми алгоритмами RL, включая PPO, GRPO и Reinforce++.
Снижение зависимостей: техника указывает на будущее, где AI-системы могут развивать сложные возможности через симуляцию, уменьшая зависимость от внешних сервисов.

Будущие направления
Visual-ARFT представляет многообещающий путь к созданию робастных и обобщаемых мультимодальных агентов. Подход демонстрирует, что эффективное обучение агентным способностям возможно с минимальными аннотированными данными — всего 20 примеров для агентного поиска и 1200 для агентного программирования.
Исследование открывает новые возможности для развития open-source мультимодальных AI-агентов с сильными способностями к рассуждению и использованию инструментов, потенциально изменяя экономику разработки AI и снижая зависимость от крупных технологических платформ.
Этот основанный на доказательствах подход к обучению LVLM с агентными способностями представляет жизнеспособную альтернативу традиционным методам, с документально подтвержденными улучшениями в производительности и стабильности обучения.







