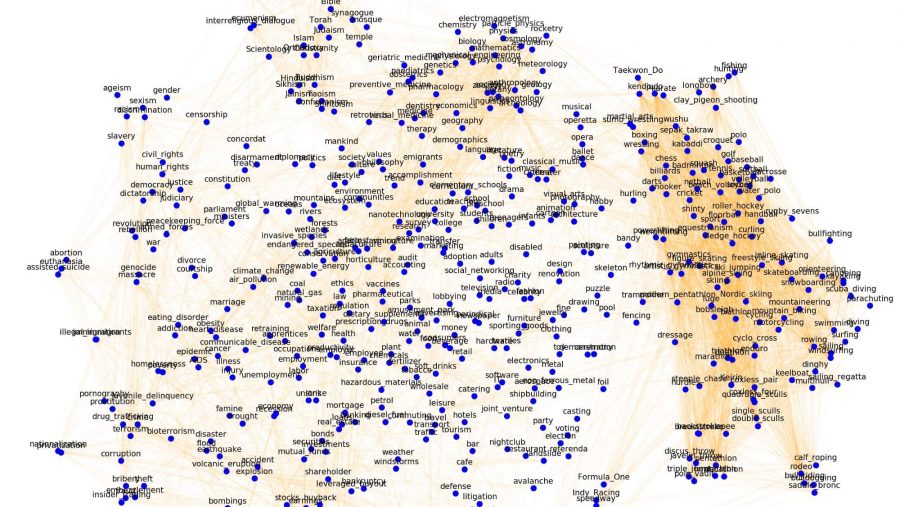
Статья рассказывает об алгоритмах word2vec, на выходе которых получаются векторные представления слов. Векторы слов лежат в основе многих систем обработки естественного языка (NLP), захлестнувших современный мир (Amazon Alexa, Google translate и т.д.).
Читайте также: Нейросети, пишущие тексты на русском языке: топ 5 сервисов
Векторные представления слов: все дело в контексте
Давайте же погрузимся в тему. Слова-векторы (word vectors) — это численные представления слов, сохраняющие семантическую связь между ними. Например, для вектора cat (кошка) одним из наиболее близких будет слово dog (собака). Однако векторное представление слова pencil (карандаш) будет достаточно сильно отличаться от вектора cat. Эта схожесть обусловлена частотой встречаемости двух слов (т.е. [cat, dog] или [cat, pencil]) в одном контексте. Рассмотрим следующее предложение:
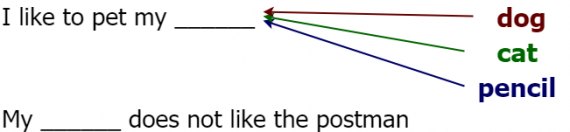
Думаю, не стоит объяснять, какое слово в этом предложении не подходит (очевидно, что это pencil). Как мы понимаем, что оно не подходит? С произношением все в порядке, с грамматикой все в порядке, тогда что же не так? Все дело в контексте, pencil не подходит по смыслу. Этот пример должен убедить вас в важности контекста. Алгоритмы word2vec используют контекст, чтобы сформировать численные представления слов, поэтому слова, используемые в одном и том же контексте, имеют похожие векторы.
Применение word2vec
Чтобы понять, как word2vec применяется в реальных проектах, попробуем следующее. Зайдем на google scholar и поищем там связанные с NLP задачи (например, вопросно-ответные системы, чат-боты, машинный перевод и прочее). Отфильтруем документы, опубликованные после 2013 года, когда появились методы word2vec. Если посчитать отношение количества статей, в которых рассказывается об использовании векторных представлений слов, к общему количеству статей, то получится довольно большое число.
Векторные представления слов используются во многих областях:
- Моделирование языков;
- Чат-боты;
- Машинный перевод;
- Вопросно-ответные системы;
- …и многое другое.
Вы можете заметить, что все современные приложения NLP основываются на алгоритмах word2vec. Давайте обсудим, как же можно улучшить существующие модели векторными представлениями слов. Они позволяют нам отобразить семантически сходные слова в близкие друг другу вектора в некоторой модели, в то время как далекие по смыслу слова будут выглядеть по-разному. Это желаемое свойство модели, которое приведет к лучшему результату.
Процесс создания векторов слов
Теперь, обладая интуитивным пониманием, мы первым делом обсудим общие принципы действия алгоритмов word2vec, а более детально рассмотрим их позднее. Чтобы обучить выборку слов без заранее размеченных данных, сначала нам нужно решить несколько задач:
- Создать кортежи данных в формате [входное слово, выходное слово], каждое слово представлено в виде двоичного вектора длины n, где i-ое значение кодируется единицей на i-ой позиции и нулями на всех остальных (one-hot кодировка);
- Создать модель, которая на вход и выход получает one-hot векторы;
- Определить функцию потерь, предсказывающую верное слово, чтобы оптимизировать модель;
- Определить качество модели, убедившись, что похожие слова имеют похожие векторные представления.
Как вы видите, процедура не очень сложная. В следующем разделе мы займемся каждым из шагов детально.
Создание структурированных данных из исходного текста
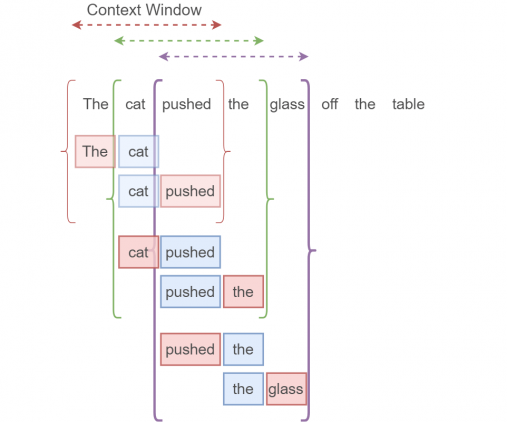
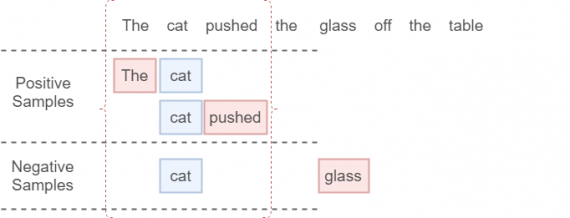
Возьмем такой пример:
The cat pushed the glass off the table.
Нужные нам данные будут получаться так. Каждая скобка обозначает единичное контекстное окно. Синее поле обозначает входной one-hot вектор (целевое слово), красное поле — выходной one-hot вектор (любое слово в контекстном окне за исключением целевого слова, так называемое контекстное слово). Из одного контекстного окна получаются два элемента данных (на одно целевое слово приходится два соседних). Размер окна обычно определяется пользователем. Чем больше размер контекстного окна, тем лучше наша модель, но это влияет на время выполнения алгоритма. Не надо путать целевое слово с целевыми данными, это совершенно разные вещи.
Определение embedding layer и нейросети
Наша нейросеть будет обучаться на входных данных, которые мы задали выше. Нам потребуется следующее:
- набор входных one-hot векторов;
- набор выходных one-hot векторов (после обучения);
- embedding layer;
- нейросеть.
Не беспокойтесь, если вы пока не понимаете, как работают два последних компонента. Мы рассмотрим их подробнее.
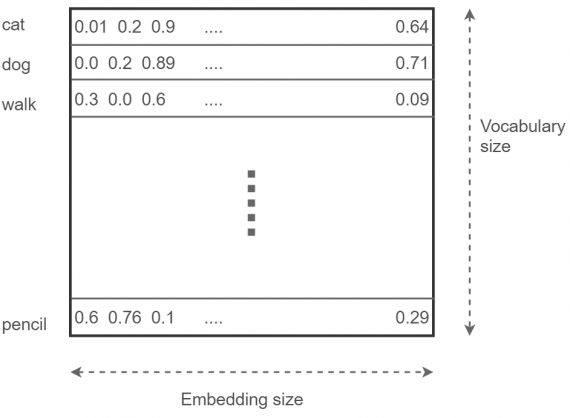
Embedding layer
Начнем с embedding layer. Он хранит вектора всех слов в словаре. Представьте себе огромную матрицу размера [число слов в словаре x размерность пространства сжатого векторного представления слов]). Эта размерность (embedding size) является настраиваемым параметром. Чем она больше, тем лучше модель (но по достижении определенного embedding size вы не получите большой прирост производительности). Эта гигантская матрица инициализируется случайным образом (как и нейросеть) и настраивается бит за битом в процессе оптимизации. Выглядит это так:
Нейронная сеть
Последний кирпичик нашей модели — нейронная сеть. В процессе обучения нейросеть получает входной вектор и пытается предсказать результат в виде распределения вероятностей слова быть в контексте входного слова на множестве всех слов (также его можно интерпретировать как линейную комбинацию one-hot кодировок этих слов). Затем с помощью функции потерь мы штрафуем модель за неправильную классификацию и награждаем за верную. Сейчас мы ограничимся обработкой одного входа и одного выхода за раз. В реальных проектах данные обрабатываются батчами (то есть группами; например, по 64 элемента). Опишем процесс обучения в общих чертах:
- Для данного введенного слова (целевого слова) найдем соответствующий вектор из embedding layer;
- Скормим этот вектор нашей нейросети, затем попытаемся предсказать правильное выходное (контекстное) слово;
- Сравнив предсказанное слово и то слово, которое на самом деле находится в контекстном окне, вычислим функцию потерь;
- Используя функцию потерь вместе со стохастическим градиентным спуском, оптимизируем нейросеть и embedding layer.
Нужно заметить, что при вычислении предсказания мы используем функцию softmax, чтобы нормализовать прогнозы до допустимого распределения вероятностей.
Собираем все вместе
Зная все детали алгоритма word2vec, мы можем собрать все воедино. После обучения модели нам остается только сохранить embedding layer на диске, после чего мы можем наслаждаться векторами с сохраненной семантикой в любое время. Вот так выглядит общая картина:
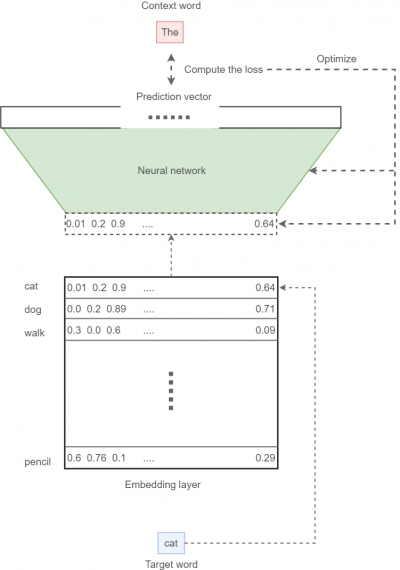
Эта модель известна как skip-gram алгоритм, это один из алгоритмов word2vec, на нем мы и сфокусируемся. Другой алгоритм известен как “непрерывный мешок со словами” (continuous bag-of-words model, CBOW).
Функция потерь: оптимизируем модель
Мы не обсудили одну из ключевых деталей — функцию потерь. Стандартная функция перекрестной энтропии (softmax cross entropy loss) является хорошим решением для задач классификации. Но для модели word2vec использование этой функции не является практичным, как например для более простой задачи вроде анализа тональности, где есть только два выходных варианта: положительный и отрицательный. В реальной задаче обработки слов, где их число может измеряться миллиардами, размер словаря запросто может вырасти до 100,000 значений или даже больше, что значительно усложняет вычисление softmax-нормализации. Это связано с тем, что для полного вычисления softmax требуется рассчитать потери в кросс-энтропии по всем выходным узлам.
Поэтому мы будем использовать более изящную альтернативу под названием sampled softmax loss функция. У нее есть ряд отличий от стандартной перекрестной энтропии.
Сначала мы вычисляем функцию перекрестной энтропии между истинным значением контекстного слова для заданного целевого слова и значением предсказанного слова, соответствующего истинному значению контекстного слова. Затем мы добавим кросс-энтропийную потерю k негативных семплов (целевое слово + слово вне контекстного окна), которые мы отбирали в соответствии с некоторым распределением шума.
Функция потерь определяется следующим образом:
![]()
SigmoidCrossEntropy это ошибка, которую мы можем определить на одном выходном узле независимо от остальных. Это идеальное решение нашей проблемы, когда словарь становится слишком большим. Не будем вдаваться в детали этой функции. Вам необязательно понимать, как именно она реализована, поскольку в TensorFlow эта функция встроенная, но стоит понять, что такое k, что это за параметр. Самое важное — это что sampled softmax loss вычисляет ошибку, рассматривая два типа объектов:
- индекс правильного контекстного слова в предсказанном векторе (индекс слова в контекстном окне);
- k индексов шумовых слов.
Мы проиллюстрируем это примером. Тут k = 1 (cat + glass):
Реализация на TensorFlow: skip-gram алгоритм
В этом разделе мы соберем все части воедино и попробуем реализовать наш алгоритм. Код доступен тут. В этой секции мы займемся следующим:
- генератор данных;
- skip-gram модель (на TensorFlow);
- запуск skip-gram алгоритма.
Генерация данных
Мы не будем углубляться в код детально, так как уже обсудили внутренние механизмы генерации данных. Просто опишем наши действия на Python:
def generate_batch(batch_size, window_size):
global data_index
# two numpy arras to hold target words (batch)
# and context words (labels)
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
# span defines the total window size
span = 2 * window_size + 1
# The buffer holds the data contained within the span
queue = collections.deque(maxlen=span)
# Fill the buffer and update the data_index
for _ in range(span):
queue.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // (2*window_size)):
k=0
# Avoid the target word itself as a prediction
for j in list(range(window_size))+list(range(window_size+1,2*window_size+1)):
batch[i * (2*window_size) + k] = queue[window_size]
labels[i * (2*window_size) + k, 0] = queue[j]
k += 1
# Everytime we read num_samples data points, update the queue
queue.append(data[data_index])
# If end is reached, circle back to the beginning
data_index = (data_index + np.random.randint(window_size)) % len(data)
return batch, labels
Определим skip-gram модель
Сначала мы определим некоторые гиперпараметры:
batch_size = 128 embedding_size = 64 window_size = 4 num_sampled = 32 # Number of negative examples to sample.
batch_size устанавливает количество элементов данных, которые мы обрабатываем в данный момент времени. embedding_size это длина вектора. Гиперпараметр window_size определяет размер контекстного окна. Наконец, num_sampled — число негативных семплов в функции потерь (k). Теперь мы определим входные и выходные данные:
tf.reset_default_graph() # Training input data (target word IDs). train_dataset = tf.placeholder(tf.int32, shape=[batch_size])
# Training input label data (context word IDs) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
train_dataset принимает на вход список идентификаторов слов batch_size, который представляет выбранный набор целевых слов. train_labels представляет собой список batch_size
соответствующих контекстных слов для выбранных целевых слов.
Затем мы определяем параметры нейронной сети:
################################################
# Model variables #
################################################
# Embedding layer
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
# Neural network weights and biases
softmax_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=0.1 / math.sqrt(embedding_size))
)
softmax_biases = tf.Variable(tf.random_uniform([vocabulary_size],-0.01,0.01))
Embedding layer в TensorFlow определяется переменной embeddings, веса — переменной softmax_weights, параметры сдвига — softmax_biases.
Соединим embedding layer и нейросеть, чтобы оптимизировать результат:
# Look up embeddings for a batch of inputs. embed = tf.nn.embedding_lookup(embeddings, train_dataset)
Функция tf.nn.embedding_lookup принимает на вход embedding layer и набор идентификаторов слов (train_dataset), а на выходе выдает соответствующие вектора.
Теперь настало время функции sampled softmax loss:
################################################ # Computes loss # ################################################ loss = tf.reduce_mean(tf.nn.sampled_softmax_loss( weights=softmax_weights, biases=softmax_biases, inputs=embed, labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size) )
Здесь tf.nn.sampled_softmax_loss получает на вход набор весов (softmax_weights), сдвигов (softmax_biases), полученный в предыдущей функции набор векторов embed, идентификаторы верных контекстных слов (train_labels), количество шумовых семплов (num_sampled) и размер словаря (vocabulary_size).
Оптимизируем функцию потерь по параметрам embedding layer и нейросети:
################################################ # Optimization # ################################################ optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
Нормируем embedding layer:
################################################ # For evaluation # ################################################ norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keepdims=True)) normalized_embeddings = embeddings / norm
Запускаем код
Как же мы запустим нашу TensorFlow модель? Для начала определим session и инициализируем все переменные случайным образом.
num_steps = 250001
session = tf.InteractiveSession()
# Initialize the variables in the graph
tf.global_variables_initializer().run()
print('Initialized')
average_loss = 0
Теперь в течение заранее определенного числа шагов мы формируем группы данных: целевые слова (batch_data) и контекстные слова (batch_labels):
for step in range(num_steps):
# Generate a single batch of data
batch_data, batch_labels = generate_batch( batch_size, window_size)
Затем для каждой сгенерированной группы мы оптимизируем embedding layer и нейронную сеть с помощью session.run([optimize, loss],…). Также мы вычислим ошибку, чтобы убедиться, что она уменьшается.
# Optimize the embedding layer and neural network
# compute loss
feed_dict = {train_dataset : batch_data, train_labels : batch_labels}
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
Каждые пять тысяч шагов мы печатаем на экране среднюю ошибку:
if (step+1) % 5000 == 0:
if step > 0:
average_loss = average_loss / 5000
print('Average loss at step %d: %f' % (step+1, average_loss))
average_loss = 0
И вот мы получаем вектора, которые позже используем для визуализации определенных слов:
sg_embeddings = normalized_embeddings.eval() session.close()
Если мы визуализируем результат с помощью какого-нибудь алгоритма вроде t-SNE, получим следующее:
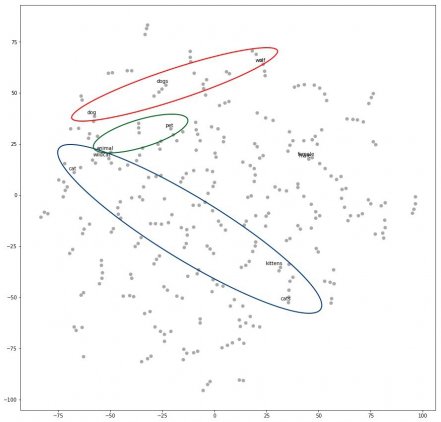
Как можно заметить, слова, относящиеся к кошкам, находятся в определенной области (cat, kitten, cats, wildcat), а слова, относящиеся к собакам, находятся в другой области (dog, dogs, wolf). Слова между этими областями (например, animal или pet) по смыслу относятся и к кошкам, и к собакам, что нам и требовалось.
Заключение
Вот мы и подошли к концу. Векторные представления слов — это очень мощный инструмент, который помогает улучшать современные модели машинного обучения. Мы научились генерировать данные и разобрались в базовых принципах работы word2vec. Затем мы обсудили skip-gram алгоритм и реализовали его на TensorFlow. В довершение ко всему мы визуализировали наши векторные представления и убедились, что семантическая составляющая действительно сохраняется. Надеюсь, эта статья была для вас полезной.






