
Researchers from HKUST, Ant Group, Zhejiang University, and Northeastern University introduced Ditto — a comprehensive open framework addressing the training data scarcity problem in text-instruction-based video editing. The developers created a data synthesis pipeline to build the Ditto-1M dataset containing over one million videos. The Editto model trained on this dataset performs both global style editing and precise local modifications – object replacement, attribute changes, element addition and removal. The pipeline generates videos of 101 frames at 1280×720 resolution. Code, data, and model are available on Github, weights on HuggingFace.
Editto Model Capabilities
Editto performs instruction-based video editing by processing three inputs: a text instruction describing the desired edit, source video, and depth information for structural guidance. The model handles diverse editing scenarios including style transfer (anime, pixel art, cyberpunk), object replacement, attribute modification, and complex scene transformations.
Built on the VACE in-context video generator with Wan2.2 as the base model, Editto generates videos at 1280×720 resolution with 101 frames at 20 FPS. The architecture includes a Context Branch extracting spatiotemporal features and a DiT-based Main Branch producing the final output. Through attention mechanisms, the model consistently propagates edits across all frames while preserving original motion dynamics and scene structure.
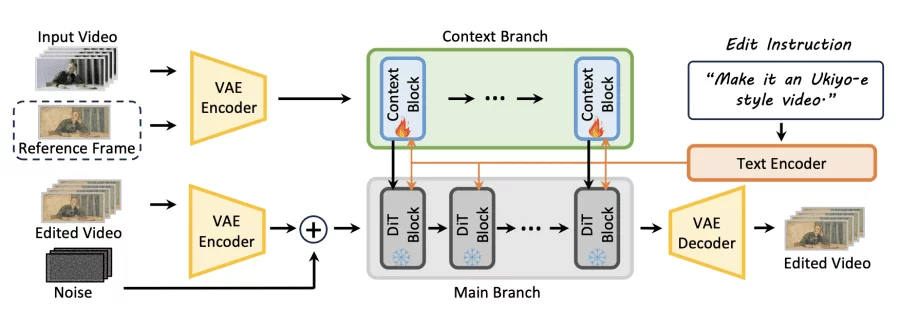
Training employed a modality curriculum learning strategy over 16,000 steps on 64 NVIDIA H-series GPUs. Initially, the model learns with both text instructions and visual reference frames. Gradually, visual guidance is reduced and eventually removed, enabling the model to perform editing based solely on text descriptions. Only linear projection layers of context blocks are fine-tuned, preserving the strong generative capabilities of the pretrained base model.
Ditto-1M Dataset
Creating Ditto-1M required over 12,000 GPU-days across three stages. In preprocessing (60 GPU-days), suitable videos are automatically selected from over 200,000 videos on Pexels, a professional content platform: the DINOv2 visual encoder removes duplicates by computing pairwise similarity of feature vectors, while CoTracker3 tracks points on a grid and calculates average cumulative displacement to assess motion quality — static videos with low scores are filtered out.
In the generation stage (6,000 GPU-days), a VLM agent creates descriptions and editing instructions, an image editing model generates the edited key frame, and video depth is extracted. The in-context generator synthesizes the edited video using a distilled model to reduce costs to 20%. In post-processing (6,000 GPU-days), a VLM filter evaluates quality across four criteria, and a denoiser performs step-by-step texture enhancement.
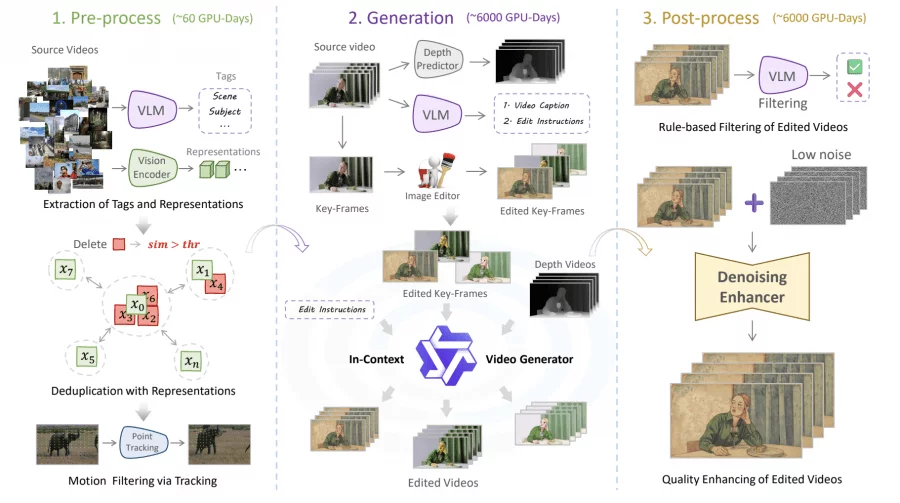
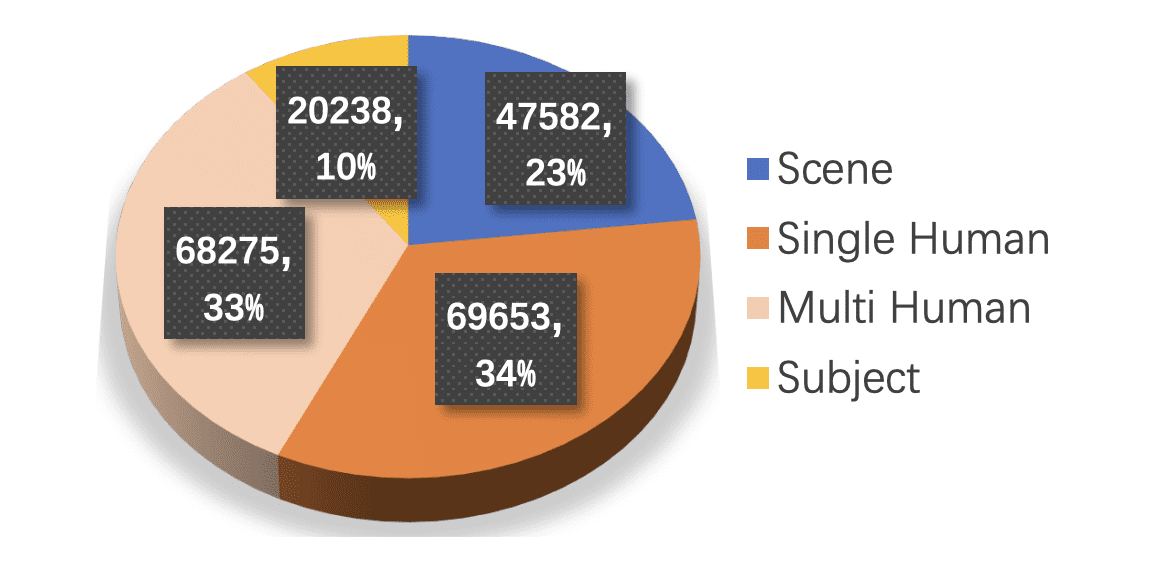
The final dataset contains over 1 million videos at 1,280×720 with 101 frames at 20 FPS: 700,000 global editing examples and 300,000 local ones. Distribution: 23% scenes, 34% single-person activities, 33% group activities, 10% objects.
Performance Results
Editto achieves state-of-the-art results across all evaluation metrics. CLIP-T of 25.54 vs 23.56 for InsViE, indicating more accurate instruction following. CLIP-F reaches 99.03 (vs 98.78), demonstrating superior temporal consistency. Holistic VLM score of 8.10 vs 7.35 confirms comprehensive quality improvement.

Human evaluation with 1,000 ratings shows substantial preference for Editto: Edit-Acc 3.85 vs 2.28 for InsViE on instruction following, Temp-Con 3.76 (vs 2.30) on smoothness and frame consistency, and Overall 3.86 vs 2.36 on overall quality. Users consistently rated Editto results as more accurately following instructions while maintaining better frame consistency.
Qualitative comparisons demonstrate Editto’s advantages. For complex stylizations like pixel art or LEGO transformations, the model generates clean, consistent results across all frames, while competitors produce blurry or temporally unstable outputs. For local edits like clothing color changes, Editto precisely modifies target objects while preserving subject identity and background accuracy. Baseline methods either fail to perform the edit or introduce unwanted changes to other scene elements.
Ablation studies confirm that performance scales with dataset size, showing visible improvements from 60K to 500K examples. Modality curriculum learning proves critical — without it, the model struggles to interpret abstract text descriptions and produces edits only partially matching instructions. The trained model also demonstrates synthetic-to-real capability, successfully reverting stylized videos to photorealistic originals, indicating robust understanding of both stylistic transformations and natural video characteristics.
Ditto enables practical instruction-based video editing through scalable data synthesis producing high-quality, diverse training examples. The combination of automated instruction generation, multimodal visual guidance, and intelligent quality control creates a dataset supporting training of models capable of performing complex editing operations from simple text descriptions while maintaining temporal coherence across extended video sequences.







