
Researchers from Carnegie Mellon University, Google Research, and the University of Georgia have introduced MAGVIT (Masked Generative Video Transformer), an open-source video generation model. MAGVIT is a unified model that enhances FPS, extrapolates frames, creates videos beyond frames, fills in missing video segments, and generates videos based on specific conditions. It has surpassed state-of-the-art approaches on three video generation benchmarks, showing a remarkable 39% improvement on the Kinetics-600 dataset.
The authors will present their work at the CVPR 2023 conference, and you can access the model code on Github.
Model Description
Here is an overview of the MAGVIT model. The model utilizes a 3D-VQ encoder to quantize videos into discrete tokens and a 3D-VQ decoder to map them back into pixel space. During each training step, a specific task is selected, and its input conditions are created by cropping and padding the original video. In this context, green represents actual pixels, while white represents padding. Conditional inputs are quantized using the 3D-VQ encoder, and the non-padding portion serves as conditional tokens.
Additionally, a sequence of masked tokens combines conditional tokens, [MASK] tokens, target tokens, and a class token as a prefix. The bidirectional transformer learns to predict target tokens through three objectives: refining conditional tokens, predicting masked tokens, and reconstructing target tokens.
For a visual representation of the MAGVIT model, refer to the following image:
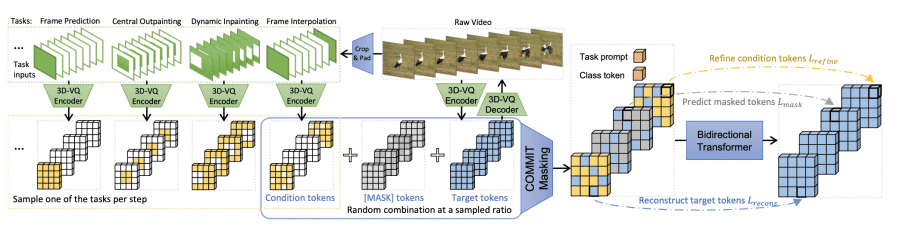
To gain further insights into MAGVIT, you can watch the following video:
The authors have developed a high-quality video quantization architecture called 3D-VQ. This architecture performs quantization with a temporal rate of 4 and a spatial rate of 64 using a codebook containing 1024 elements. As a result, the base version of MAGVIT achieves a speed of 37 frames per second on a single V100 graphics processor.
MAGVIT Training
The model underwent a two-stage training process using the publicly available Something-Something-V2 dataset. In the first stage, a VQ autoencoder was employed to quantize videos into discrete tokens in spatial and temporal dimensions. In the second stage, a Transformer model with token masking received masked visual tokens and conditional tokens as input, predicting tokens in the masked positions.
Results
MAGVIT showcases state-of-the-art performance in synthesizing videos based on class descriptions and the first frame. It operates significantly faster than diffusion video models and autoregressive models.
Let’s check the generation performance of MAGVIT on the UCF-101 dataset:
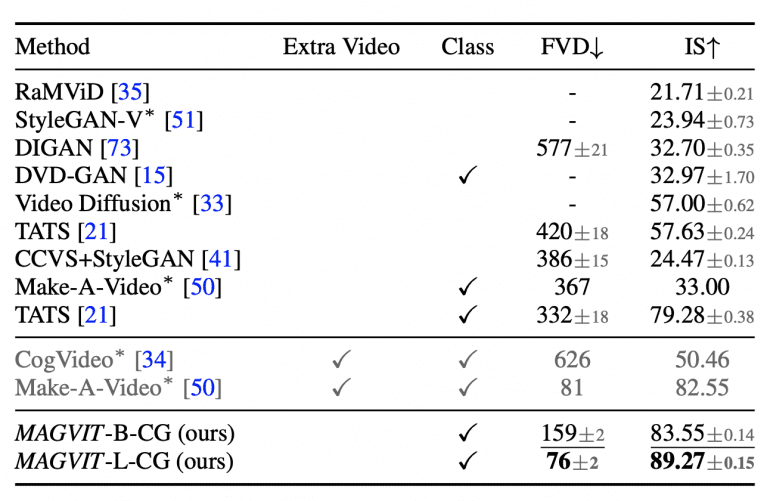
The gray-colored methods were pre-trained on additional large video datasets. Methods marked with a ✓ in the “Class” column are class-conditional, while the others are unconditional.
Regarding frame prediction performance, consider the following results obtained on the BAIR and Kinetics-600 datasets:

Now, let’s compare the time efficiency of different video generation approaches:
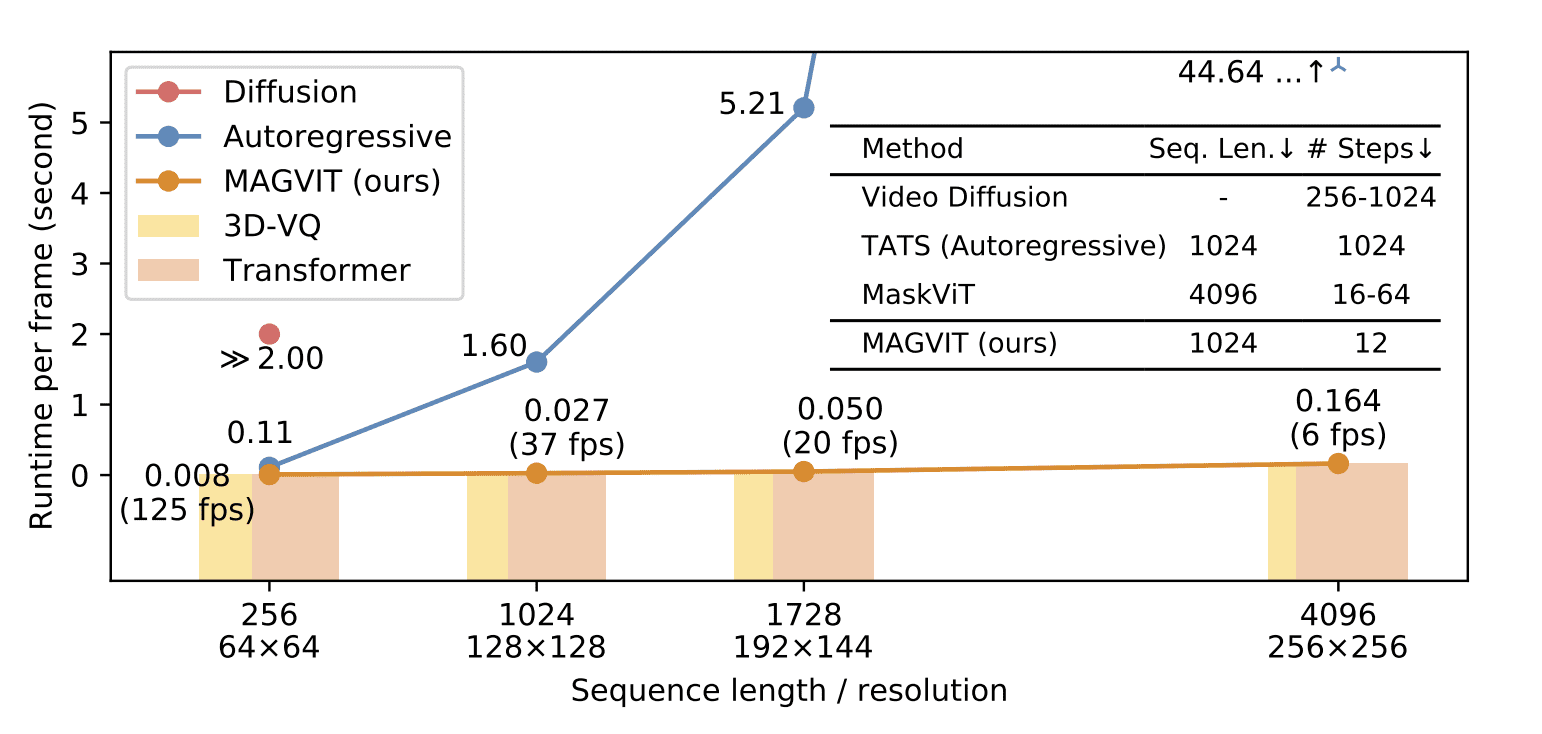
The average time taken to generate one frame was measured at various resolutions. The colored bars represent the distribution of time between 3D-VQ and the transformer. The embedded table compares key factors affecting output efficiency across different methods at a resolution of 16 frames, 128×128, excluding Video Diffusion at a resolution of 64×64.







