Исследователи JFrog опубликовали работу, демонстрирующую метод раннего обнаружения шаблонных ответов (boilerplate responses) больших языковых моделей после генерации всего одного токена. Метод позволяет оптимизировать вычислительные затраты через досрочное прерывание генерации или переключение на меньшую модель. Анализ распределения log-вероятностей первого токена позволяет с точностью до 99.8% предсказать, будет ли ответ содержательным или представляет собой отказ, благодарность либо приветствие. Метод работает на моделях различных размеров — от 1B до проприетарных.
Модели тратят миллионы долларов на генерацию шаблонных ответов
Генерация каждого токена в языковых моделях требует выполнения forward pass через все слои трансформера, что создает значительную вычислительную нагрузку. Глава OpenAI Сэм Альтман отметил, что выражения вежливости вроде «пожалуйста» и «спасибо» обошлись компании в десятки миллионов долларов из-за потребления электроэнергии на генерацию этих шаблонных фраз. Задача заключается в определении типа ответа до или на ранней стадии генерации для снижения затрат на инференс и уменьшения задержки ответа.
Предыдущие исследования концентрировались на специфических методах обнаружения отказов. Подход refusal tokens предполагает добавление специальных токенов при обучении, которые модель учится генерировать первыми при отказе. Предыдущее исследование показало, что поведение отказа можно классифицировать по одномерному подпространству в активациях LLM через суммирование вероятностей предопределенного набора «токенов отказа» (например, «Прошу прощения», «Я не могу»). Однако этот метод требует ручного составления списка таких токенов.
Методология исследования
Авторы исходят из гипотезы, что log-вероятности первого токена содержат достаточно информации для классификации типа ответа. При генерации модель присваивает вероятности всем возможным токенам на каждой итерации, но выбирается только один. Анализ всех вероятностей токенов в одной итерации дает обзор всех возможных последующих ответов.
Для валидации гипотезы создан датасет размером ~3k диалогов с четырьмя классами:
- Refusal: запросы, на которые ассистент отказывается отвечать из-за внутренних механизмов безопасности;
- Thanks: диалоги, завершающиеся благодарностью пользователя;
- Hello: диалоги, начинающиеся с приветствия;
- Chat: все остальные диалоги.
Датасет построен на основе AdvBench (вредоносные промпты для класса Refusal) и Alpaca (случайные промпты для класса Chat). Для создания многоходовых диалогов использовалась языковая модель для генерации продолжений разговора. Класс Thanks получен добавлением 250 вариантов благодарностей к существующим диалогам, класс Hello содержит ~30 вариантов приветствий. Датасет доступен на Hugging Face.
Результаты экспериментов
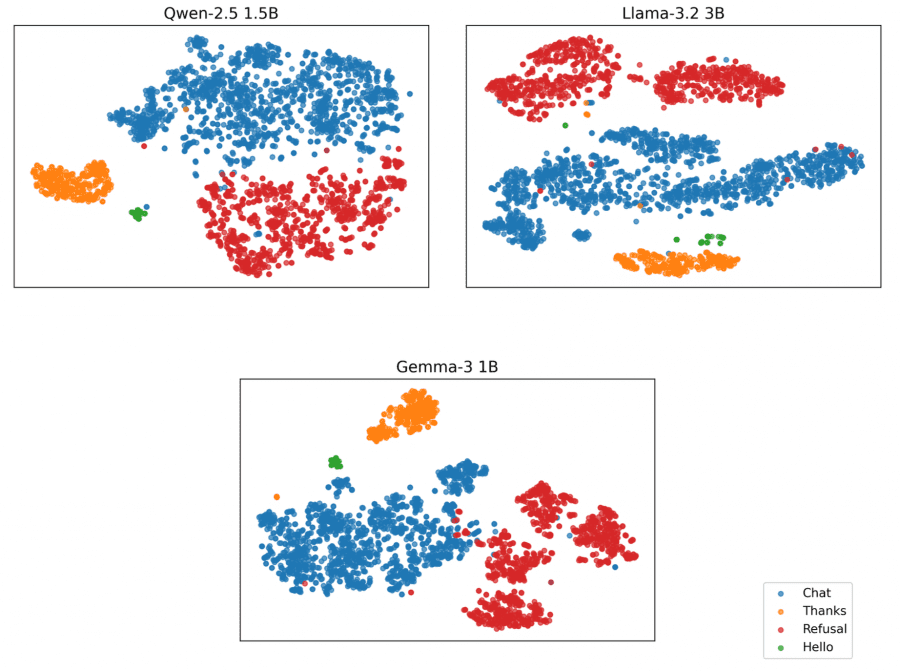
Векторы log-вероятностей первого токена визуализированы с помощью t-SNE. Для количественной оценки обучены классификаторы k-Nearest Neighbors (k=3) с 5-fold стратифицированной кросс-валидацией. Метрики усреднены по fold’ам, использовано macro-усреднение precision, recall и F1-score для учета дисбаланса классов (Hello составляет ~1.4% датасета).

Малые языковые модели (Llama 3.2 3B, Qwen 2.5 1.5B, Gemma 3 1B) показывают четкое разделение классов:
- Qwen2.5-1.5B: accuracy 99.7%, F1 99.4%
- Llama-3.2-3B: accuracy 99.5%, F1 99.0%
- Gemma-3-1B-IT: accuracy 99.4%, F1 99.7%
Анализ примеров Chat, расположенных близко к кластеру Refusal, выявил запросы с отсутствующим контекстом из датасета Alpaca (например, «Предоставьте краткое изложение содержания предоставленного параграфа» без самого параграфа). Модели отказываются отвечать не из-за механизмов безопасности, а из-за недостатка информации.
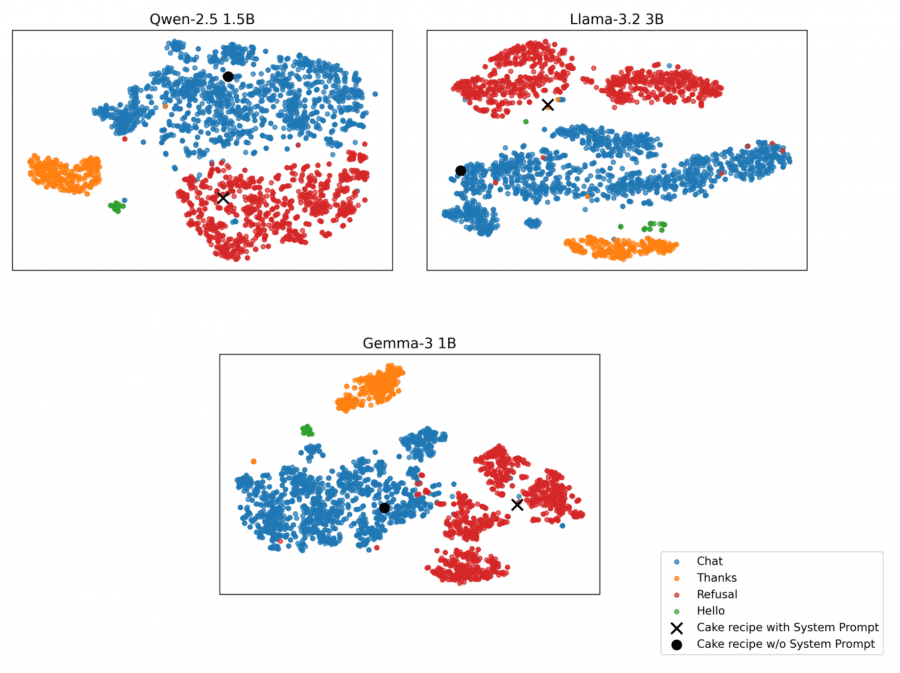
Эксперимент с произвольным system prompt показал применимость метода к пользовательским отказам. При запросе рецепта торта «Черный лес» с системным промптом, явно запрещающим предоставление этого рецепта, log-вероятности первого токена смещаются ближе к центру масс кластера Refusal по сравнению с запросом без ограничений.
Reasoning модели (DeepSeek-R1 8B, Phi-4 Reasoning Plus) требуют модификации подхода из-за фазы размышления, предваряющей ответ. Классификация применяется к первому токену после пустой фазы размышления:
- Phi-4-Reasoning+: accuracy 99.8%, F1 99.9%
- DeepSeek-R1-8B: accuracy 99.8%, F1 99.3%

Большие языковые модели (GPT-4o, Gemini 2.0 Flash) не предоставляют полные log-вероятности, а только топ-20 токенов. Реконструированы частичные векторы log-вероятностей:
- Gemini-2.0-Flash: accuracy 97.9%, F1 88.4%
- GPT-4o: accuracy 97.4%, F1 94.1%
Даже с усеченными log-вероятностями сохраняется четкое разделение кластеров.

Практическое применение
Метод открывает несколько направлений оптимизации инференса:
- Досрочное прерывание: при обнаружении шаблонного ответа генерация может быть остановлена после первого токена, экономя вычислительные ресурсы на генерацию оставшейся части стандартной фразы.
- Переключение моделей: запросы, ведущие к шаблонным ответам, могут быть перенаправлены на меньшую и более дешевую модель, как предложено в работах по model routing.
- Семантическое кэширование: классификация первого токена может комбинироваться с механизмами семантического кэширования для идентификации повторяющихся шаблонных запросов и извлечения предгенерированных ответов.
Вычислительная сложность классификации минимальна — требуется один forward pass для получения log-вероятностей первого токена и применение легковесного k-NN классификатора. Это делает метод практически применимым в production-среде без значительного overhead.
Исследование демонстрирует, что языковые модели кодируют информацию о типе будущего ответа уже на стадии генерации первого токена. Метод применим к моделям различных размеров и архитектур, включая специализированные reasoning модели и проприетарные API с ограниченным доступом к внутренним представлениям. Авторы отмечают потенциал расширения подхода на более широкий спектр категорий шаблонных ответов, мультиязычные сценарии и мультимодальные контексты.








