
Данные — это топливо, которое двигает глубокое обучение вперёд. Объём данных, свободно доступных в Сети, постоянно растёт. Большие датасеты с изображениями, такие как Pascal VOC, ImageNet и относительно свежий датасет Google Open Images продвинули точность распознавания выше человеческого уровня. Кроме того, исследовали собрали много специализированных датасетов, таких, как Food 101 и Soccer Player Detection (скорее всего, не без помощи подневольных студентов).
Но что делать, если датасета для вашей задачи не существует? Попробуем найти одно из решений этой проблемы: cделаем граббер, который способен создать датасет из результатов поиска картинок в Google или Bing. Он будет развёрнут на AWS Lambda с использованием бессерверной архитектуры, и тому есть две причины. Во-первых, благодаря этому граббер будет легко горизонтально масштабироваться, а во-вторых, просто хотелось поиграться с этой технологией. Код доступен по ссылке.
Я покажу вам этот метод на примере игрушечного проекта «Искусство или нет?» Этот проект попытается дать ответ на вековой вопрос, является ли тот или иной объект искусством.
“Искусственный” датасет
Для обучения классификатора, который знает, является ли нечто искусством, нам понадобятся картинки двух типов:
- Изображения искусства (положительные примеры)
- Изображения чего угодно ещё (отрицательные примеры)
Граббим Google Images
Немного погуглив, я нашёл списки разных видов искусства, которые решил использовать как запросы для поисковика. Вот некоторые из них:
- Абстрактное искусство
- Абстрактный экспрессионизм
- Акриловая живопись
- Античная поэзия
- Анимация
- Архитектура
- Ар-брют
- Ар-деко
- Ар-нуво
- …
В итоговый список вошло примерно 120 категорий искусства. Но его никак нельзя назвать полным и исчерпывающим, мы с этим ещё столкнёмся.
Создаем приложение
Мы будем писать приложение с помощью библиотеки Serverless. Скрипт для деплоя делает много разных вещей: создаёт Lambda-функции, загружает их код в облако, настраивает привилегии, создаёт таблицы DynamoDB, настраивает автоматическое масштабирование этих таблиц, и соединяет друг с другом триггеры, по которым срабатывают функции. Всё это происходит по одной простой команде:
sls deploy
Затем загрузим категории искусства в табличку DynamoDB (это делается простым скриптом). Каждый раз, когда в этой таблице добавляется (удаляется, обновляется) элемент, другой скрипт начинает собирать урлы картинок для этой категории. Будем называть этот скрипт «Граббером запросов».
Скрипт живёт внутри Lambda-функции.
Что такое AWS Lambda?
AWS Lambda — сервис, который запускает код в так называемом «бессерверном» (serverless) окружении. Это значит, что вам не нужно выделять серверы для вашего приложения, не нужно заниматься его администрированием или заботиться о масштабировании. Всем этим занимается AWS. Вы платите Амазону только за время, в течении которого работает приложение, с точностью до сотни миллисекунд. Lambda-функция срабатывает в ответ на различные события в облаке Амазона: в DynamoDB добавлена запись, на S3 загружен файл, на AWS API Gateway пришёл HTTP-запрос — возможных событий очень много.
Под капотом происходит следующее: как только происходит событие, которого ожидает Lambda-функция, AWS создаёт сервер (или воспользуется существующим), и запускает код функции в контейнере. Круто здесь то, что такая система способна масштабироваться до тысяч и более запусков в секунду. Ощущение как от технологии будущего.
Итак, у нас есть граббер запросов, который скармливает запросы поисковику (Google Images или Bing Image Search API) с помощьюPhantom.js и Selenium. Затем Lambda-функция прокручивает страницу до конца, чтобы загрузились все изображения. При необходимости скрипт нажимает на «Далее», пока картинки не закончатся. Затем со страницы собираются и сохраняются все ссылки на картинки.
Одна из особенностей Lambda — это то, что каждая функция должна работать не дольше пяти минут. Поскольку мы хотим скачать как можно больше картинок по каждой категории, мы не запускаем сбор урлов и скачивание в одной функции.
Вместо этого используется вторая таблица в DynamoDB, в которой Граббер запросов записывает ссылки на изображения, которые находит. Добавление в эту таблицу инициирует другую Lambda-функцию, которая скачивает картинку и сохраняет её на S3 для дальнейшего использования.
Цена DynamoDB
Я всё ещё в нерешительности насчёт DynamoDB, поскольку пользоваться им в течение длительного срока “вроде как довольно невыгодно”. Тем не менее, для подобных одноразовых проектов он в самый раз. AWS даёт бесплатно 25 единиц пропускной способности на чтение и запись. Это позволяет бесплатно делать 25 запросов на чтение и запись в секунду. Со включенным автомасштабированием, лимит для каждой таблицы может автоматически повышаться до 1000 запросов в секунду, а затем уменьшаться обратно в соответствии с нагрузкой. До тех пор, пока сумма выделенной пропускной способности за месяц не превышает в среднем 25, всё должно быть бесплатно. (Кажется, автор оригинальной статьи запутался в ценовой политике Амазона, что немудрено. Судя по всему, считается средняя пропускная способность не за месяц, а за час. — прим. перев.)
После того как Lambda-функции завершили свою магию, у нас образовалось около 1000 изображений для каждой категории — всего 120 тысяч картинок.
Если хотите обучиться на картинках локально, можете скачать датасет (здесь скрипт для этого). Вместо этого можно оставить датасет на S3 и обучаться в облаке Амазона.
Вот примеры собранных картинок. Как видно, на большинстве из них действительно изображено искусство.
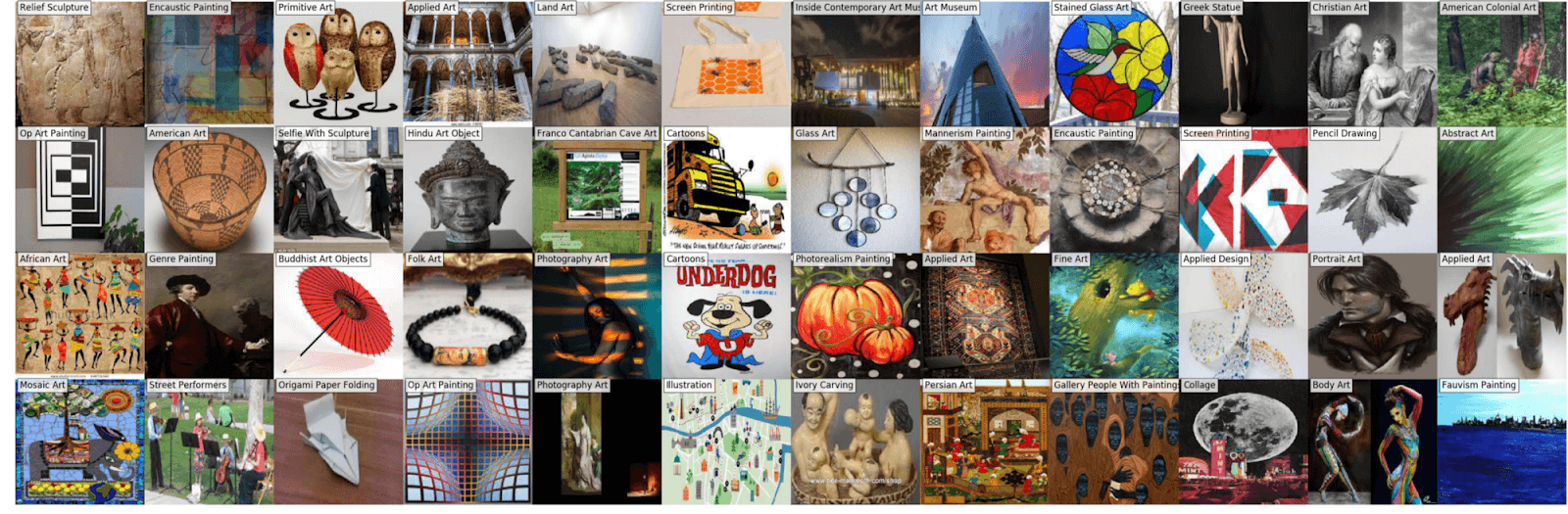
Проблемы своего датасета
На этом этапе у вас могли возникнуть два очень правильных вопроса.
Разве мы таким образом не выучим ошибку (bias) поисковика?
Это мы и делаем: выучиваем, что поисковик знает о данной категории. Я бы сказал, что это в некотором смысле выжимка знаний (Knowledge Distillation). Мы берём все данные и метаданные об изображениях, которые есть у Гугла, а также знания, накопленные их моделями, и выжимаем все эти знания в одну модель. И всё же, если Гугл не считает что-то хорошим примером абстрактного искусства, наша модель тоже будет так думать.
Разве мы не получим очень шумные данные?
Так и есть, и это может стать проблемой, если у вас нет способа почистить их. Например, если вы таким образом собираете датасет с различными моделями машин, вам нужно будет прогнать данные через детектор машин, и убрать изображения, на которых машин не обнаружено. Если вы делаете датасет селфи, как Эндрю Карпаты, вам нужно будет проверить, что на каждой картинке есть лицо.
Я не придумал, как почистить датасет в случае с искусством, так что решил надеяться, что поможет просто большой объём данных.
Собираем набор отрицательных примеров
Чтобы уметь отличать искусство от неискусства, модель должна увидеть примеры вещей, искусством не являющихся. К счастью, у нас есть датасет ImageNet, в котором, по удачному стечению обстоятельств, собрано много изображений таких вещей.
ImageNet LSVRC 2012 можно скачать с сайта Academic Torrents.
Чтобы не добавлять ещё больше шума в наш датасет, отфильтруем те классы ImageNet, которые не связаны семантически с нашими категориями.
Для этого мы воспользуемся векторными представлениями слов (word embeddings) из пакета Gensim. С их помощью мы переведём классы ImageNet и наши категории в их word2vec-версии.
Word2vec
Word2vec — это модель (группа моделей — прим. перев.), которая отображает слово в 300-мерный вектор, который называется его представлением. Сеть обучена помещать рядом в этом 300-мерном пространстве слова, которые встречаются в похожих контекстах — например, слова король и царь. У представлений слов есть много интересных свойств, но интереснее всего то, что они позволяют нам производить над смыслами слов арифметические операции. Например:
word2vec(король) — word2vec(мужчина) + word2vec(женщина) = word2vec(королева)
Эта статья подробно объясняет векторные представления слов и их свойства.
Многие собранные категории описываются несколькими словами (например, «Античная поэзия»), поэтому для них я сложил их векторные представления. Например, вектор для «американского колониального искусства» вычислялся как word2vec(американское) + word2vec(колониальное) + word2vec(искусство).
Затем я посчитал косинусное расстояние между векторами для классов ImageNet и всеми категориями. Чем больше расстояние, тем меньше семантическая близость.
Я выбрал 66% самых удалённых классов ImageNet. Из-за этого потерялись некоторые потенциально неоднозначные классы, такие как «ваза». Теперь модель не увидит многие сложные отрицательные примеры — вещи, которые похожи на искусство, но не являются ими. Тем не менее, я решил пока забыть про эту проблему.
Из выбранных классов мы случайно выберем столько же изображений, сколько у нас положительных примеров.
В итоге, в нашем датасете около 120 тысяч положительных примеров искусства, и около 120 тысяч отрицательных примеров.

Обучение и оценка
В качестве модели донастроим предобученную на ImageNet модель Inception ResNet V2. Изображения приведём к размерам 299 на 299.
Для увеличения датасета воспользуемся аугментацией: поворотами, обрезанием, сдвигом, увеличением и горизонтальным отражением.
Уберём только последний слой, и заменим его на дропаут с коэффициентом 0,8 и полносвязным слоем с двумя выходами.
После обучения последних 10 свёрточных слоёв модели в течение 5 эпох на валидационной выборке из 30 тысяч изображений достигается точность более 0,99.
Вот предсказания модели на валидационной выборке (второе изображение в третьем ряду классифицировано неверно).

Я собрал небольшую тестовую выборку из изображений, которые я сфотографировал сам.

Добавляем больше данных
Тем не менее, наш классификатор искусства лучше всего работает, когда объект (картина, статуя и т. д.) является основным на изображении. Так вышло из-за того, что Гугл в основном выдаёт изображения, которые прямо соответствуют запросу и не содержат лишнего шума (как и изображения в ImageNet — прим. ред.)
Чтобы справиться с этим, соберём второй набор категорий — ещё 30. Таким образом, мы надеемся получить фоновый шум, скачав изображений следующих вещей:
Галерея искусств
Музей искусств
Люди в музее
Селфи в музее
Инсталляция
…
Кроме того, добавим некоторые категории, которых не было в изначальном списке:
Граффити
Муралы
Перформанс
Уличные артисты
Декоративно-прикладное искусство
Религиозное искусство
…
Ожидаемо, это улучшило точность на изображениях, в которых есть люди. Кроме того, мы продемонстрировали огромное преимущество данного метода: мы смогли добавить новые объекты просто и недорого.
Наша модель выучила вероятностное распределение изображений, полученых из Гугла. Тем не менее, весьма вероятно, что настоящие картинки выглядят немного иначе и сломают модель. Предлагаю вам донастроить её с помощью типичных изображений, к которым вы хотите её применять. Потребуется гораздо меньше картинок. Код граббера выложен, можете с ним поиграться.
Несмотря на все возможные подводные камни, полагаю, что это ценный метод создания датасета в случаях, когда другие варианты недоступны или слишком дороги.






