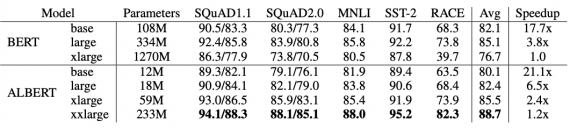
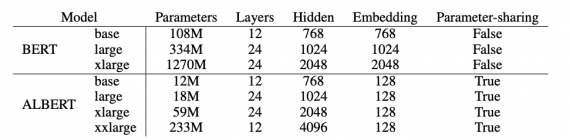
A LITE BERT (ALBERT) — это оптимизированная версия BERT от Google. Разработчики использовали два метода для снижения количества параметров нейросети: параметризация векторных представлений и обмен весов между слоями нейросети. По результатам экспериментов, ALBERT обходит самую полную версию BERT на задачах GLUE, RACE и SQuAD. Аналогичная версия BERT-large в ALBERT имеет в 18 раз меньше параметров и может быть обучена в 1.7 раз быстрее.
Увеличение размера модели на этапе предобучения векторных представлений слов часто результирует в улучшение качества предсказаний. Несмотря на это, обучение крупных моделей имеет очевидный недостаток — ограниченность вычислительных ресурсов. Это вытекает в увеличение времени на обучение модели и увеличения требований к объему памяти. Чтобы избавиться от этих проблем, исследователи из Google разработали 2 техники для оптимизации размера BERT. ALBERT масштабируется лучше, чем стандартный BERT. Чтобы модель выдавала более устойчивые результаты была использована self-supervised функция потерь, которая фокусируется на согласованности слов внутри предложения. Это помогает модели генерировать более связный текст для входных текстов, которые состоят из нескольких предложений.
Методы уменьшения размера модели
Существующие решения для снижения размерности модели являются параллелизация модели и управление памятью. Эти методы справляются с проблемой ограниченности памяти. Однако они не повышают устойчивость модели к увеличению и уменьшению размера.
Что внутри ALBERT
ALBERT основана на архитектуре стандартного BERT, но модифицирована с помощью двух методов для снижения количества параметров. Методы включают в себя:
- Матрица векторных представлений слов делится на две маленькие матрицы: размер скрытых слоев напрямую отделяется от размера векторов (factorized embedding parameterization);
- Нейросеть передает параметры между слоями, чтобы параметры не росли с увеличением глубины нейросети (cross-layer parameter sharing)
Уменьшение параметров выступает как регуляризатор нейросети и стабилизирует обучение нейросети.
Результаты экспериментов
Ниже видно, что при значительном сокращении размера ALBERT выступает либо сравнимо, либо лучше BERT. Везде в качестве метрики использовалась точность.