Для изучения нового языка алгоритмы машинного перевода требуют много текстовых данных. Нужный объём сложно получить, особенно в случае с редкими языками, например урду. FAIR представили новый подход для перевода с редких языков с незнакомой грамматикой, используя обучение без учителя.
Как работает
Нейросеть учится, используя векторные представления слов и контекст. Слова представляются в виде вектора в многомерном пространстве. Алгоритм анализирует семантические свойства пар слов, и находит слова близкие по контексту. Например, «котёнок» ближе к словам «кошка» и «животное», чем к слову «ракета», потому что чаще используется рядом с ними. Наличие контекста характерно для всех языков.

Грамматика
Система хорошо работает для перевода словосочетаний, но с целыми текстами возникла проблема: алгоритм не учитывает грамматические свойства языка. Чтобы сделать перевод более корректным, разработчики обучили нейросеть правильной структуре предложений. Теперь на последнем этапе обработки модель сравнивает переведённые словосочетания с грамматически верными конструкциями.
Результаты
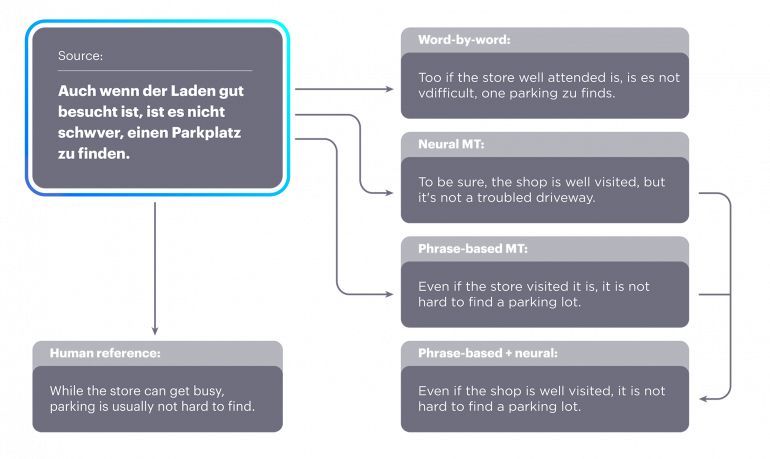
Алгоритм протестировали на переводах с французского и немецкого на английский. Эффективность оценивалась с помощью BLEU по шкале от 0 до 100. Качество перевода улучшилось на 10 баллов в сравнении с другими методами: word-by-word, Neural MT, Phrase-Based MT.
Исходный код проекта доступен на GitHub.