Компания DeepMind представила результаты работы AlphaZero — универсального алгоритма для игры в настольные игры, который обучается самостоятельно, зная только правила. AlphaZero уже обыграл алгоритмы AlphaGo, Elmo и Stockfish — экс-чемпионов мира по го, сёги и шахматам.
Разработчики впервые представили алгоритм AlphaZero в 2017 году. Он победил программу AlphaGo — алгоритм DeepMind, который специализировался только на игре в го. AlphaGo вошел в историю, выиграв у одного из лучших игроков в го Ли Седоля в 2016 году.
Новый алгоритм
AlphaZero просчитывает 60 тысяч ходов в секунду в шахматах и сёги, по сравнению с 60 миллионами у Stockfish и 25 миллионами у Elmo. При этом, AlphaZero использует глубокую нейронную сеть, чтобы сосредоточиться на самых многообещающих вариантах развития партии. Главная особенность алгоритма состоит в том, что нейронная сеть AlphaZero постоянно самообучается. Параметры обновляются прямо в процессе игры, не дожидаясь окончания матча.
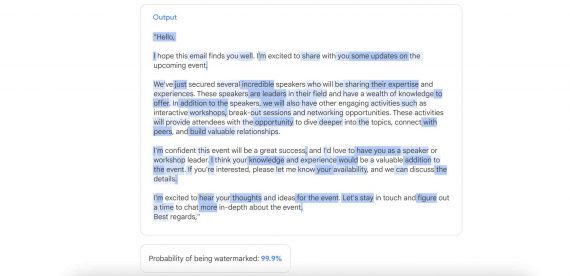
В го AlphaZero победил AlphaGo Zero, выиграв 61% игр. В сёги AlphaZero победил Elmo в 91,2% случаев. В шахматах результат AlphaZero против Stockfish составил 155 побед и 6 проигрышей из 1000, 839 игр было сыграно вничью. Разработчики использовали отдельные версии алгоритма для каждой игры. Обучение длилось 9 часов для игры в шахматы, 12 часов для сёги и 13 дней для го.
AlphaZero может обучиться любой игре, которая предоставляет всю информацию о принятии решений. Покер и многопользовательские игры, такие как StarCraft II, Dota и Minecraft сложнее для обучения. Однако эксперты полагают, что программы, которые смогут победить людей, появятся в ближайшие 2-3 года. Алгоритмы OpenAI уже обыграли лучших игроков в Dota 2, хотя и в ограниченной версии игры.