Разработчики FAIR собрали датасет, который ускорит и повысит эффективность обучения диалоговых систем и чат-ботов Facebook. Датасет содержит 5 миллионов персонажей и 700 миллионов диалогов с сайта Reddit.
В основе нового датасета набор данных PERSONA—CHAT, который был создан совместно исследователями Монреальского института изучения алгоритмов и командой Facebook AI, и содержал 1000 персонажей. Датасет имел серьезные недостатки и ограничения.
«PERSONA—CHAT был создан с использованием механизма искусственного сбора данных на базе Mechanical Turk. В результате ни диалоги, ни персонажи не были репрезентативны для реальных взаимодействий пользователей и ботов, контекст оставался ограниченным» — объяснили исследователи в статье.
Чтобы устранить ограничения первого набора данных, исследователи Facebook создали новый крупный датасет с 5 миллионами персонажей и 700 миллионами диалогов. Он состоит из комбинаций реальных разговоров пользователей, извлеченных из онлайн—платформы Reddit.
Исследователи обучили диалоговую end-to-end модель на новом датасете.
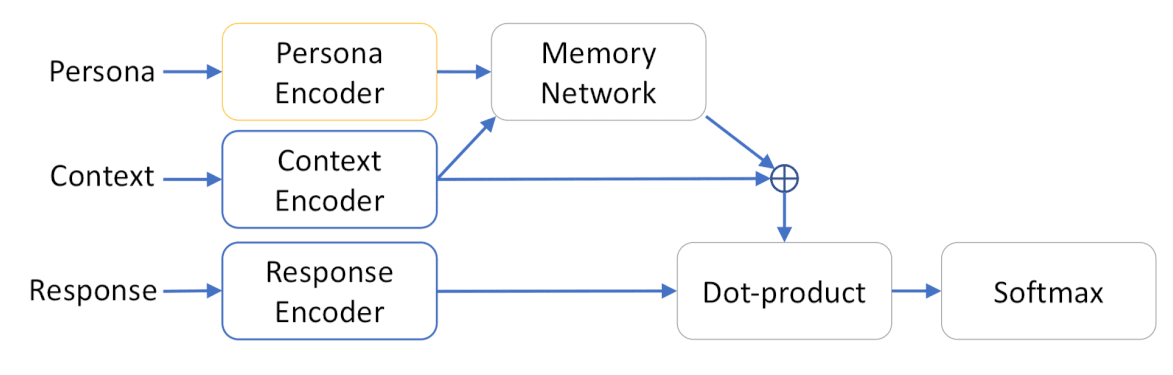
Задачей исследователей было научить модель давать правильные ответы на вопросы, основываясь на личности отвечающего и контексте.
Persona: [“I like sport,” “I work a lot”]
Context: “I love running.”
Response: “Me too! But only on weekends.”
Persona — личностные установки отвечающего, context — предложение, на которое нужно ответить. Response — это ответ, который даёт модель, опираясь на характеристику личности и контекст.
В будущем исследователи планируют доработать модель для использования в диалоговых системах. Голосовые помощники и чат-боты, обученные на большем количестве данных, смогут вести более плавные и глубокие диалоги с пользователями.