На конференции ICLR 2019 разработчики Google Magenta представили новый подход к синтезу аудио с помощью генеративно-состязательной нейронной сети. GANSynth позволяет генерировать музыку в 50 000 раз быстрее методов, основанных на авторегрессии, таких как WaveNet от DeepMind.
В работе исследователи адаптировали модель WaveGAN и предложили несколько новых архитектур на базе PGGAN — метода, который используется для генерации изображений.
GAN для создания музыки
Генеративно-состязательные сети сегодня используются в основном для создания высококачественных изображений. В задачах синтеза аудио доминируют модели авторегрессии подобные WaveNet и Transformer, которые генерируют музыку напрямую, предсказывая одну последовательность за раз. Однако последовательная генерация делает процесс очень медленным.
Вместо последовательной генерации звука, GANSynth генерирует всю последовательность параллельно, синтезируя аудио в 50000 быстрее, чем WaveNet. В отличие от автоэнкодеров оригинальной WaveNet в которой используется скрытый код с распределением по времени, GANSynth генерирует все аудио из одного латентного вектора, что упрощает разделение глобальных функций, таких как высота и тембр и позволяет контролировать их независимо.
Для обучения нейросети исследователи использовали набор данных NSynth, состоящий из 300000 отдельных нот 1000 музыкальных инструментов. Много примеров сгенерированной музыки можно послушать здесь. На них показано, как тембр интерполируется по ходу произведения.
Результаты
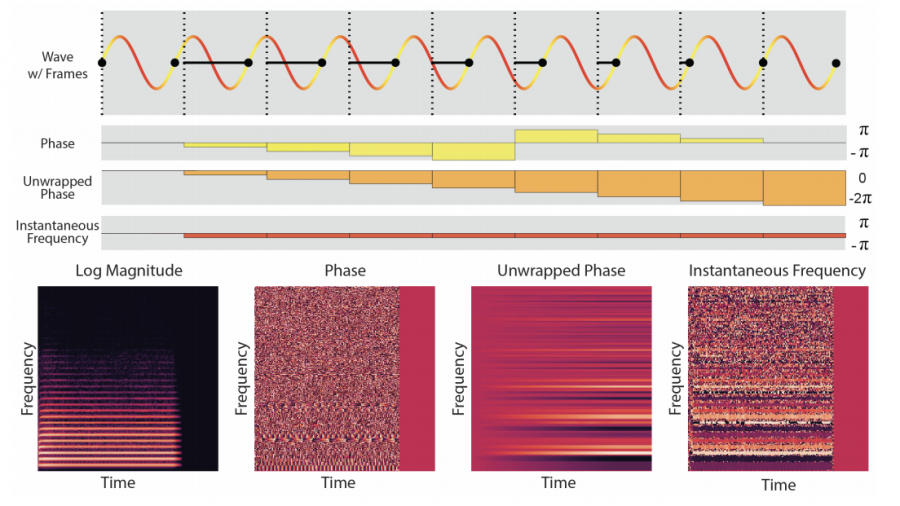
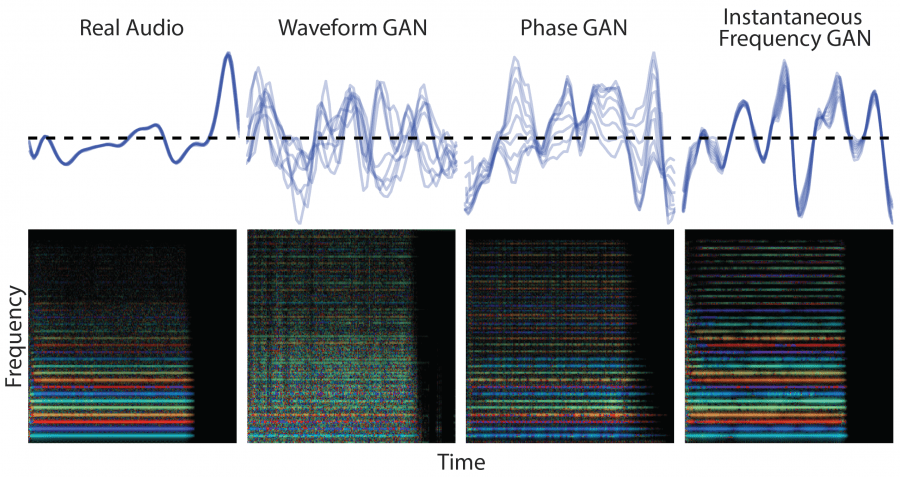
Во время экспериментов ученые разработчики обнаружили, что метод IF-GAN, который генерирует мгновенные частоты (instantaneous frequencies) для фазового компонента превосходит другие модели в когерентности сигнала. На рисунке ниже показаны типы сигналов. WaveGAN и PhaseGAN имеют много фазовых неровностей, в то время как результат IF-GAN гораздо более последовательный, с небольшими вариациями от цикла к циклу.
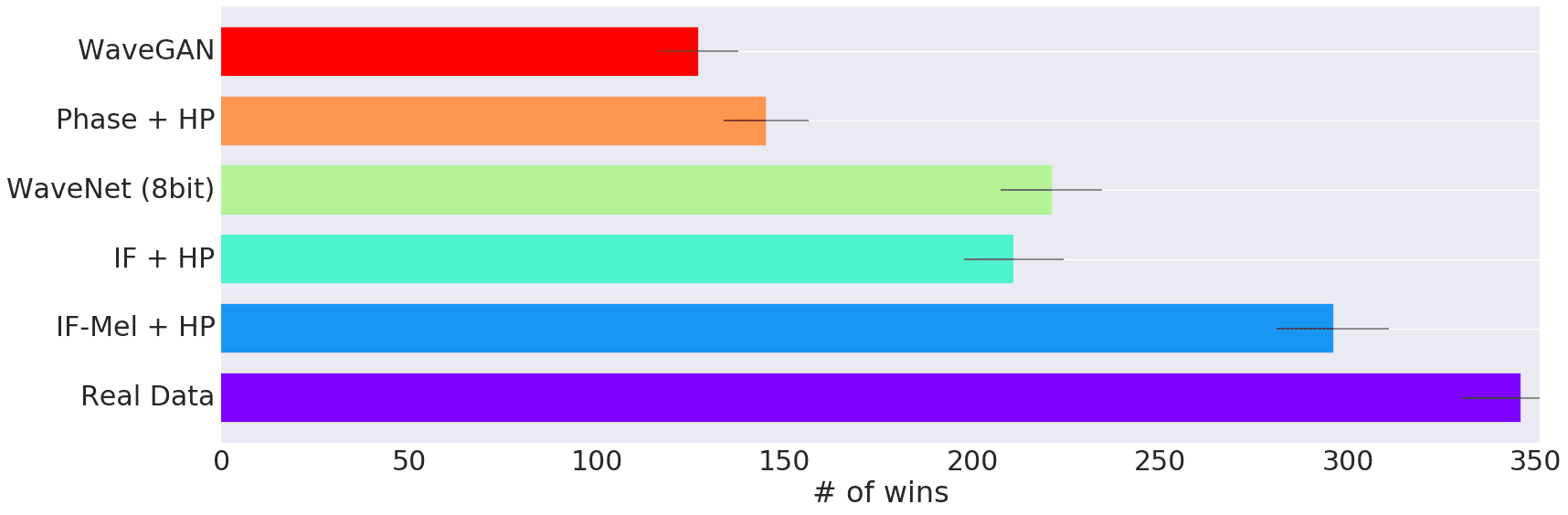
На графике ниже показаны результаты тестов прослушивания. Людям проигрывали аудио примеры двух методов и спрашивали, какой звучит лучше.
 Работа представляет собой один из первых шагов в использовании GAN для создания высококачественного звука и открывает пути для дальнейших исследований, например генерации речи с помощью GAN. В блоге разработчики отмечают, что описанные выше методы хорошо работают для музыкальных сигналов, но пока создают заметные артефакты в задачах синтеза речи.
Работа представляет собой один из первых шагов в использовании GAN для создания высококачественного звука и открывает пути для дальнейших исследований, например генерации речи с помощью GAN. В блоге разработчики отмечают, что описанные выше методы хорошо работают для музыкальных сигналов, но пока создают заметные артефакты в задачах синтеза речи.