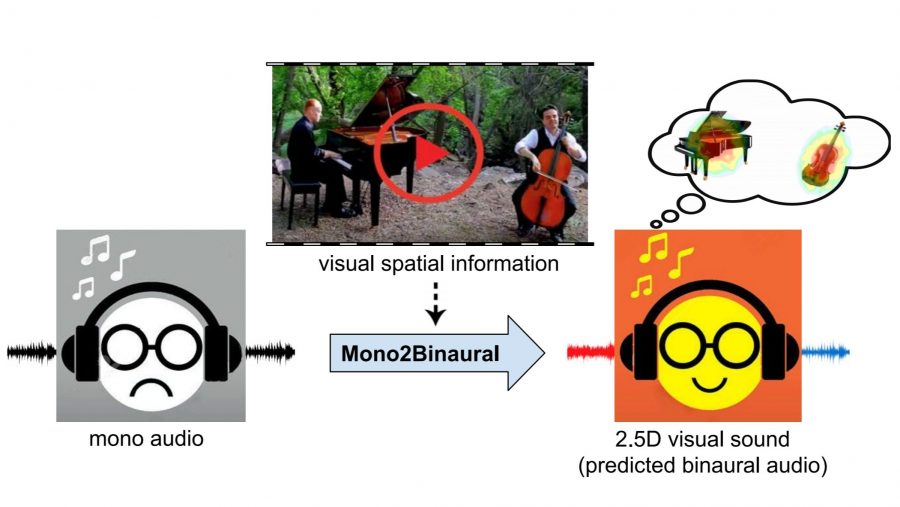
Рухан Гао из Техасского университета и Кристен Грауман из FAIR разработали метод преобразования монофонического звука в бинауральный при наличии одноканальной записи и видеоряда. Алгоритм назвали 2.5D Visual Sound, он работает на основе сверточных нейронных сетей.
«Бинауральная запись (лат. bi — два + auris — ухо) — метод звуковой записи, при котором используется специальное расположение микрофонов, предназначенное для последующего прослушивания через наушники» — Википедия.
Посмотрите видео с результатами экспериментов, опубликованное разработчиками. В нём наглядно показано различие между монофонической и бинауральной записью:
Алгоритм работы 2.5D Visual Sound
Метод 2.5D Visual Sound основан на сверточных нейросетях U-Net и ResNet. Алгоритм определяет, в каком направлении идет звук, используя визуальные признаки. Сначала нейросеть сопоставляет сцену на видеозаписи со звуком, чтобы понять откуда он идет, а затем искажает скорость, уровни и объем, создавая бинауральный эффект для слушателя.
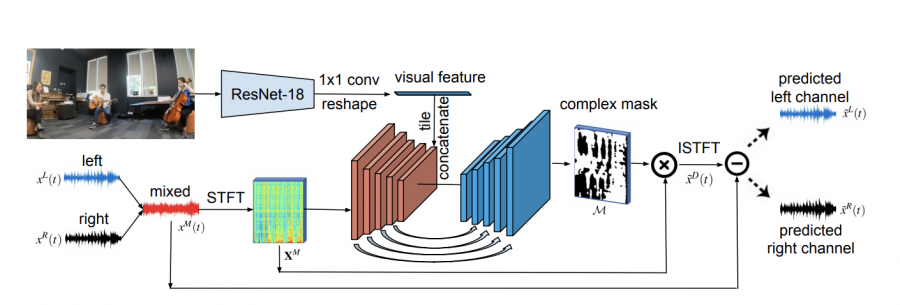
Для обучения сети разработчики записали 2265 музыкальных видео, общая длительность которых составила 6 часов. Создать эффект бинауральной записи на обучающих видео помогли бинауральные микрофоны, которые имитируют устройство человеческих ушей.

Пока нейросеть не умеет работать с источниками звука, которые не видны на видео. Но исследователи научили алгоритм разделять визуальные- и аудио-потоки на видеозаписях, например, звуки музыкальных инструментов.
Похожей разработкой занималась команда исследователей MIT-IBM Watson AI Lab и Колумбийского университета. Они предложили метод, который позволяет находить области изображения, из которых «исходят» звуки, и разделять их на набор компонент, которые создаются в разных пикселях изображения.