Нейросети в разработке игр могут применяться в таких задачах, как генерация персонажа в 3D из снимка в 2D, анимация персонажа, генерация игровых локаций. Мы даем краткую выжимку последних статей для каждого из применений нейросетей в геймдеве.
Стилизация изображений
Задача стилизации изображения заключается в том, что бы модифицировать входное изображение в соответствии с определенным стилем. В качестве отсылки к стилю обычно берется второе изображение. На выходе модель отдает модифированное изображение. Одним из применений такой модели для разработки игр является генерация аватара пользователя.
Face-to-Parameter Translation for Game Character Auto-Creation
Где: ICCV’19
Генерируют изображение игрового персонажа на основе одной фотографии лица. Решают задачу поиска из возможные черт лица, две функции потерь: “discriminative loss” и “facial content loss”. Используют imitation learning. Единственный конкурирующий подход — 3DMM-CNN.
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
Где: ICCV’19
На вход подается список изображений вещей, на выходе генерируется изображение человека в одежде. Архитектура — Style GAN, немного модифицированная. Тренируют unconditional и conditional GAN. У unconditional результаты по FID метрике более правдоподобные. Дополнительно unconditional GAN тренируют решать задачу переноса позы и цвета одежды.
A Closed-form Solution to Photorealistic Image Stylization
Где: ECCV’18
Кто: NVIDIA
Генерируют стилизованные фотореалистичные изображения. Обучение делится на два шага: стилизация изображения и увеличение реалистичности сгенерированного изображения (smoothing step). Подход схож с Luan (2017) и WCT (2017).
Generating Artistic Portrait Drawings from Face Photos with Hierarchical GANs
Где: CVPR’19
Генерируют рисунок по фотографии с помощью иерархической GAN. Суть иерархической GAN в двухступенчатом генераторе (1 глобальная нейросеть и 6 локальных) и в двухступенчатом дискриминаторе (1 глобальная нейросеть локальных). 6 SOTA методов, с которыми сравнивались: Gatys, CNNMRF, Deep Image Analogy, Pix2Pix, CycleGAN, Headshot Portrait. Общепринятая метрика — Frechet Inception Distance.
Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Решают задачу image-to-image генерации. Это можно рассматривать как indirect style transfer. U-GAT-IT включает в себя модуль с вниманием и обучающуюся функцию нормализации. Модуль внимания учит модель фокусироваться на более важных частях изображения при генерации целевого изображения из входного. Прошлые модели с модулем внимания не были устойчивы к изменениям в формах между целевым изображением и reference изображением.
Генерация 3D из 2D изображений
Модели, которые решают эту задачу, генерируют 3D модель объекта на основе одного или нескольких входных изображений. В разработке игр такие модели могут использоваться для виртуализации каких-то объектов из реальной жизни и создания более персонализированного аватара.
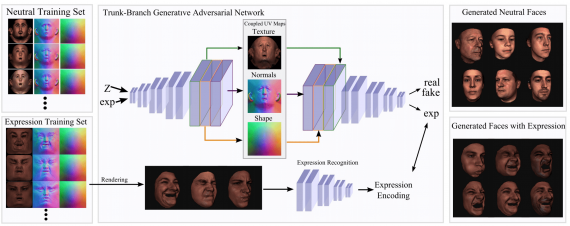
Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Используют GAN для генерации 3D модели лица человека. Дополнительно накладывают условия на GAN, чтобы модель генерировала 3D модель лица с заданным выражением.
Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
На вход модели подается одно или несколько изображений. Цель — восстановить 3D геометрию и текстуру одетого человека, сохранив при этом детали изображения. Предложенный алгоритм состоит из полностью сверточного кодировщика изображений и непрерывной функции, которая переводит эмбеддинг изображения в 3D-поверхность. Эта функция основана на многослойных перцептронах.
Dual Attention MobDenseNet for Robust 3D Face Alignment
Реконструируют 3D модель лица человека из одного изображения. Архитектура — сверточная нейросеть, в каждом слое есть блок Spatial group-wise enhance для улучшения распространения черт лица в разных ракурсах.
Генерация уровней и локаций
Модель принимает на вход изображение локации или граф, описывающий ее составляющие, и генерирует локацию в формате изображения или 3D модели. Это может упростить процесс создания игровых сцен при разработке игр.
DeepView: View Synthesis with Learned Gradient Descent
Нейросеть принимает на вход изображения одного вида с разных ракурсов и восстанавливает 3D модель.
Multi-branch Volumetric Semantic Completion from a Single Depth Image
Восстанавливают 3D модель локации из одного изображения глубины (depth image). Используют несколько дискриминаторов, чтобы повысить реалистичность сгенерированной модели.
Image Generation from Scene Graphs
Где: CVPR’18
Генерируют изображение из image graph (графовое представление содержания изображения). Используют один слой графовой сверточной сети и cascaded refinement network (CRN).
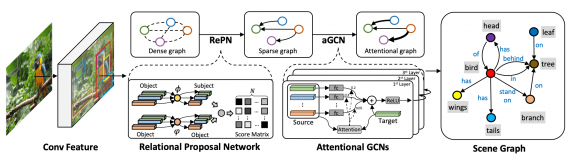
Graph R-CNN for Scene Graph Generation
Где: ECCV’18
Решают ту же задачу, что Image Generation from Scene Graphs. Добавляют к графовой сверточной нейросеть механизм внимания и называют это attentional Graph Convolutional Network (aGCN).
Probabilistic Neural Programmed Networks for Scene Generation
Где: NeurIPS’18
Генерируют изображение из текстового описания. Решение — PNPNet, вариационный автокодировщик.
Multi-Scale Local Planar Guidance for Monocular Depth Estimation
Где: State-of-the-art на задаче Monocular Depth Estimation on KITTI Eigen split
Предлагают метод для генерации depth images на основе одного изображения. Суть подхода — последовательно генерировать depth image для 1/8, 1/4 и 1/2 изображения (local planar guidance).
Лицевые анимации
Такие модели генерируют анимированные аватары на основе голоса или изображений лица.
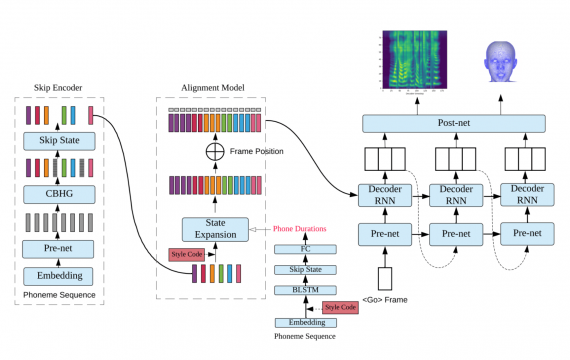
Duration Informed Attention Network For Multimodal Synthesis
Две модели внутри одной – одна генерирует голос на основе текста, а вторая — лицевую анимацию (координаты в 3D).
Data-Driven Physical Face Inversion
Кто: DisneyResearch
Генерируют 3D модель лица на основе нескольких изображений лица в разных ракурсах и предопределенной общей модели головы человека.
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Кто: Samsung AI, Skolkovo
Генерируют видеозапись говорящего человека из одного его изображения и референс видео говорящего человека. Meta-learning часть модели включает в себя нейросеть, которая сопоставляет изображения головы (с размеченными точками на разных частях лица) с векторами, которые содержат информацию о характеристиках лица, независимых от расположения лица на изображении. Генератор из входных размеченных точек лица синтезирует через сверточные слои выходные изображения. Целевая функция включает в себя perceptual loss и adversarial loss (реализована через условный дискриминатор проекций).
3D Face Synthesis Driven by Personality Impression
На вход подается 3D модель лица и лейбл выражения лица. Модель модифицирует 3D модель лица так, чтобы выражение лица соответствовало лейблу.
Анимации персонажей
Скелет персонажа восстанавливается по изображениям в полный рост. Такие модели могут использоваться в геймдеве для внедрения персонализированных аватаров пользователей полноценно в игру.
Predicting Animation Skeletons for 3D Articulated Models via Volumetric Nets
Модель предсказывает каркас анимированного объекта. На вход подается 3D модель объекта. Из 3D модели дополнительно извлекаются фичи о геометрической форме, которые используются для обучения нейросети.
3D Character Animation from a Single Photo
Кто: FAIR
Анимируют персонажа в 3D на основе одного изображения. 3D модель персонажа может двигаться (бегать, садиться, ходить).
Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks
Генерируют изображения аниме героя на основе заданной позы. Предлагают Progressive Structure-conditional GAN, чтобы минимизировать количество артефактов при генерации героя в полный рост.
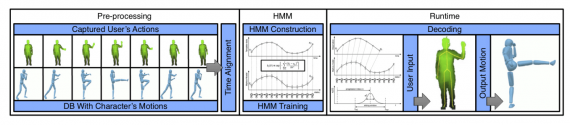
Animation-by-Demonstration Computer Puppetry Authoring Framework
Master of Puppets (MOP) — это фреймворк для анимации персонажа через демонстрацию действия. Пользователь показывает персонажу действие. Персонаж повторяет действие. Модель (hidden Markov model (HMM)) предсказывает дальнейшее действие, которое затем исполняется персонажем.