Исследователи Microsoft представили LeMa (Learning from Mistakes) – алгоритм с открытым исходным кодом для улучшения способности больших языковых моделей решать математические задачи. LeMa заставляет модель учиться на своих ошибках, имитируя процесс обучения людей.
Принцип работы алгоритма основан на том факте, что человек эффективнее решает задачу, если он в процессе решения анализирует каждый шаг своих рассуждений и корректирует их при нахождении ошибок.
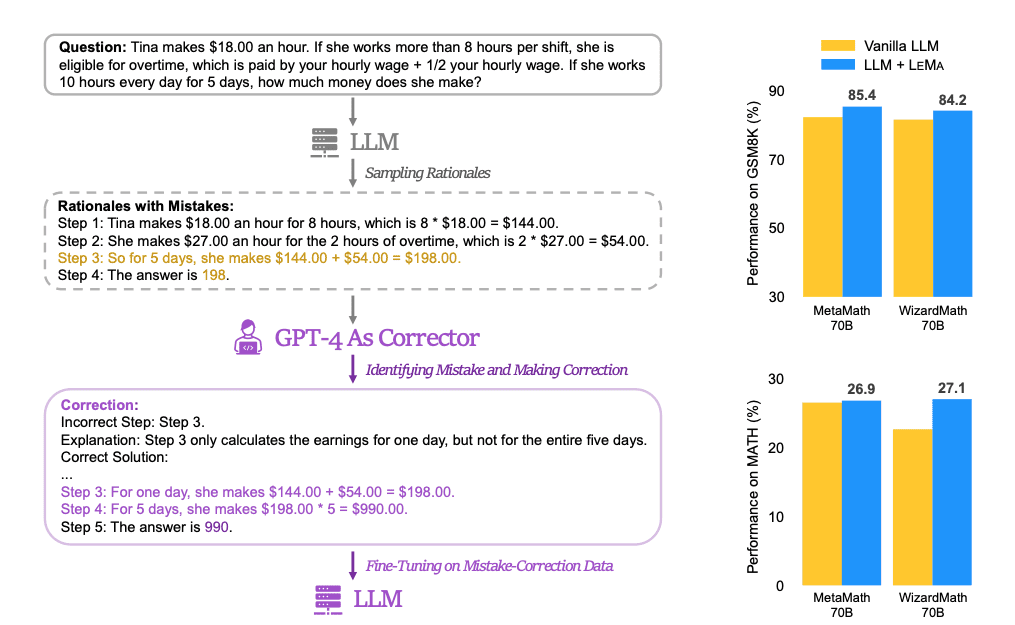
Ученые собрали обучающий датасет на основе ответов нескольких языковых моделей, в которых они генерировали ошибочные пути рассуждения при решении математических задач. Эти ответы передавались GPT-4. Запрос к GPT-4 содержал условие задачи, ответы моделей и задание определить неверные рассуждения, объяснить суть ошибок и предоставить корректное решение, начиная с момента первой ошибки:

Выбор GPT-4 для коррекции ошибок обусловлен тем, что при ручной проверке данная модель показала наилучшее качество при решении поставленной задачи. Всего для обучения использовалось, в зависимости от исходной модели, от 26 до 45 тысяч примеров пар «решение модели – исправленное решение». Затем полученный датасет использовался для дообучения моделей.
По данным Microsoft, алгоритм смог увеличить точность решения математических задач в каждой из пяти ключевых языковых моделей, участвующих в исследовании. Более того, специализированные на решении математических задач модели WizardMath и MetaMath после дообучения с помощью LeMa достигли точности 85% и 27% на бенчмарках GSM8K и MATH. Эти показатели являются рекордными для моделей с открытым кодом.
Код алгоритма и все данные исследования опубликованы на GitHub.