Исследователи из UC Berkeley и Adobe Research обучили нейросетевой классификатор, который определяет фейковые изображения. Классификатор обучался на сгенерированных одной моделью изображениях. При этом он обобщается на изображения, которые были сгенерированы другими генеративными нейросетями. Стандартный классификатор, который был обучен на сгенерированных ProGAN изображениях, обобщается на другие CNN-архитектуры, датасеты и способы обучения. Это достигается при помощи аккуратной пред- и пост-обработки и аугментации данных. Исследование показывает, что текущие генеративные модели, основанные на CNN, имеют общие систематические недостатки.
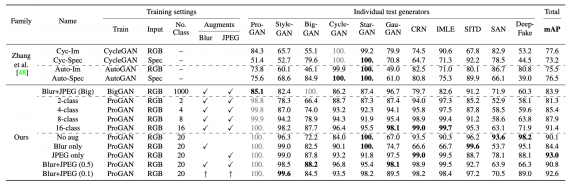
Целью исследования было обучить универсальный классификатор, который разделял бы реальные изображения от тех, что были сгенерированы нейросетями. Чтобы протестировать классификатор, исследователи отобрали 11 разных архитектур для генерации изображений, которые основаны на сверточной нейросети. Среди архитектур ProGAN, StyleGAN, BigGAN, CycleGAN, StarGAN, GauGAN и DeepFakes.
Обучающий датасет
Исследователи собрали датасет ForenSynths с изображениями, которые сгенерировали 11 разных генеративных CNN-нейросетей. Модели подбирались так, чтобы охватить разнообразие возможных архитектур, датасетов и функций потерь. Все модели в выборке имеют upsampling convolutional структуру.
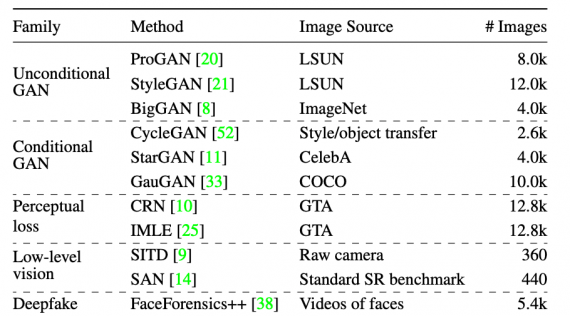
Чтобы сделать распределения реальных и сгенерированных изображений максимально близкими, реальные изображения предобработали по пайплану. Подробно пайплайн предобработки разобран в статье.
Тестирование классификатора
Работу классификатора протестировали на всех 11 рассмотренных генеративных архитектурах. Классификатор обучался на данных ProGAN. Ниже видно, что предсказательная точность у модели для изображений, сгенерированных StarGAN, — 100%.