
В Google AI обучили нейросеть, которая определяет, насколько объекты на изображении отдалены от камеры. Предложенный подход сравним с state-of-the-art решениями. Это первая нейросеть, обученная для случая, когда и камера, и объекты на видео двигаются.
Реконструкция изображений из 2D в 3D — это открытая задача компьютерного зрения. Традиционный подход основывается на триангуляции, которая предполагает, что объект может быть рассмотрен как минимум с двух разных точек одновременно. Традиционный подход не работает в том случае, когда и камера, и объект движутся. Большинство существующих примеров фильтруют движущиеся объекты. Исследователи Google AI предлагают метод для построения карт глубины изображения, которые отражают, насколько близко объекты находятся к камере.
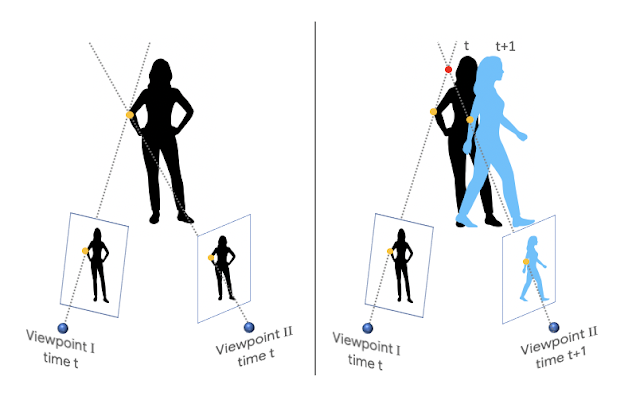
Данные для обучения модели были собраны с YouTube. Исследователи отобрали 2 тыс. видеозаписей, где люди имитируют манекенов: люди на видео статичны, двигается только камера. Затем с помощью традиционных методов, основанных на триангуляции, эти видео были размечены.
Архитектура нейросети
На каждом таймстемпе на вход нейросеть принимает RGB изображение, границы распознанных людей на изображении и начальная близость объектов (не людей). Начальная близость рассчитывается с помощью optical flow между входным изображением и изображением на предыдущем таймстемпе. На выходе модель выдает полную карту близости объектов (depth map) для входного кадра. Сгенерированная карта сравнивается с той, которая была получена традиционным методом на этапе сбора данных.
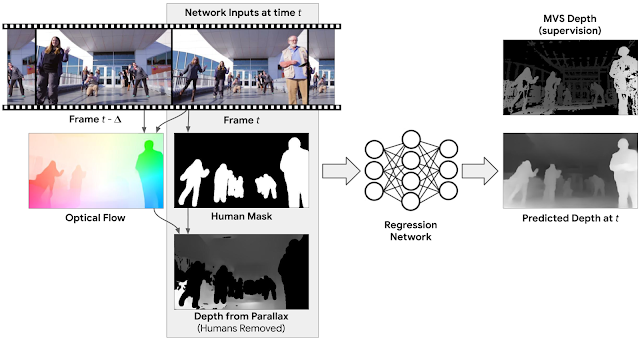
Процесс обучения нейросети
Оценка работы модели
Модель, которую предложили исследователи, выдает результаты, сравнимые с state-of-the-art подходами. В качестве конкурирующих подходов рассматриваются DORN, Chen et al. и DeMoN.

Видеодемострация работы модели:








