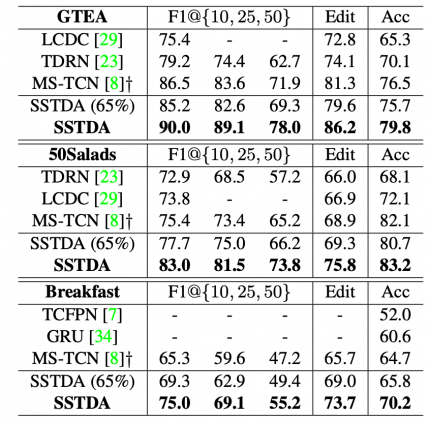
SSTDA — это self-supervised нейросетевая модель, которая распознает действия на видеозаписи. По результатам экспериментов, SSTDA обходит текущие state-of-the-art подходы на трех датасетах: GTEA, 50Salads и Breakfast. При этом модель требует только 65% размеченных данных для обучения. Код проекта доступен в открытом репозитории на GitHub.
Описание проблемы
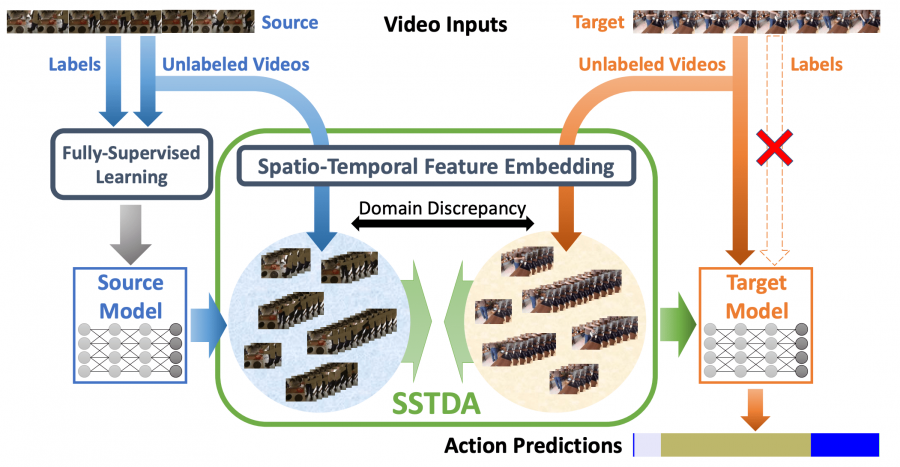
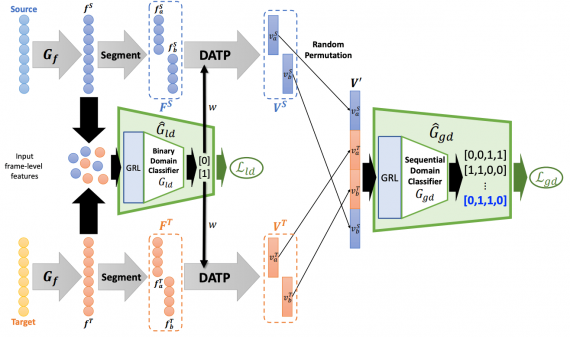
Одной из сложностей решения задачи распознавания действий является проблема пространственно-временной вариативности. Например, люди на видеозаписи выполняют одно действие разными способами. Исследователи используют неразмеченные видеозаписи, чтобы решить эту проблему. Они переформулировали задачу сегментации действий в кросс-доменную задачу с несоответствием доменов, которое вызвано пространственно-временной вариативностью. Чтобы сократить несоответствие, исследователи предлагают Self-Supervised Temporal Domain Adaptation (SSTDA) модель. SSTDA решает две вспомогательные задачи: бинарная и последовательная классификация домена. Решение этих задач позволяет соотнести пространства признаков разных доменов. SSTDA справляется с задачей распознавания действий лучше, чем предыдущие подходы, которые основаны на Domain Adaptation (DA).
Архитектура модели
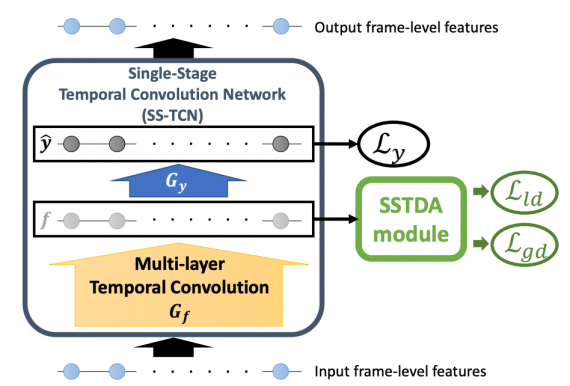
SSTDA основана на существующей state-of-the-art модели для сегментации действий, — MS-TCN. MS-TCN — это многоэтапная сверточная нейросеть, которая на каждом этапе обучения применяет многослойный TCN, чтобы извлечь признаки из кадра. Затем полносвязный слой осуществляет предсказание класса действия. Результаты с разных этапов стакаются. В MS-TCN на каждом этапе модель берет предсказания с прошлого этапа, чтобы выдать предсказание для текущего этапа.
Чтобы снизить зависимость модели от размеченных данных, исследователи ввели две задачи, которые SSTDA решает во время обучения. Ниже видно, что к базовой модели добавляется модуль SSTDA, который делает нейросеть self-supervised.
Проверка работы модели
Исследователи проверили работу модели на трех датасетах для сегментации действий: GTEA, 50Salads и Breakfast. SSTDA сравнивали с state-of-the-art подходами: LCDC, TDRN и MS-TCN. Вариант модели, которая обучалась с 65% размеченных данных выдает схожие с предыдущими методами результаты. При этом нейросеть, которая обучалась на всех размеченных данных, обходит существующий state-of-the-art.