Python-библиотека NLPAug позволяет устранить дисбаланс между классами данных в текстовых датасетах путем замены слов на синонимы, двойного перевода и других методов. Использование библиотеки повышает эффективность нейросетей, оперирующих с текстами, без необходимости изменения архитектуры модели и ее тонкой настройки.
Содержание датасета, используемого для обучения нейросети — один из ключевых фактором, определяющих ее эффективность. Наиболее распространенными проблемами датасетов, приводящими к невозможности построить надежную модель машинного обучения, являются недостаточное количество данных и дисбаланс различных групп данных, представленных в датасете. Аугментация данных — это синтез новых данных из уже имеющихся данных. Аугментация может применяться к любому типу данных — от чисел до изображений. Например, чтобы увеличить количество изображений, можно деформировать (вращать, обрезать и т. д.) имеющиеся фотографии. Гораздо более сложной задачей является аугментация текстовых данных. Например, изменение порядка слов на первый взгляд может показаться может полностью изменить смысл предложения.
Библиотека NLPAug предоставляет эффективные инструменты для быстрой аугментации текстов:
- замена определенного количества слов их синонимами;
- замена определенного количества слов словами, которые имеют аналогичные (основанные на косинусном сходстве) векторные представления (такие как word2vec или GloVe);
- замена слов на основе контекста с использованием трансформеров (например, BERT);
- двойной перевод, то есть перевод текста на другой язык и обратно, в ходе которого происходит замена нескольких слов.
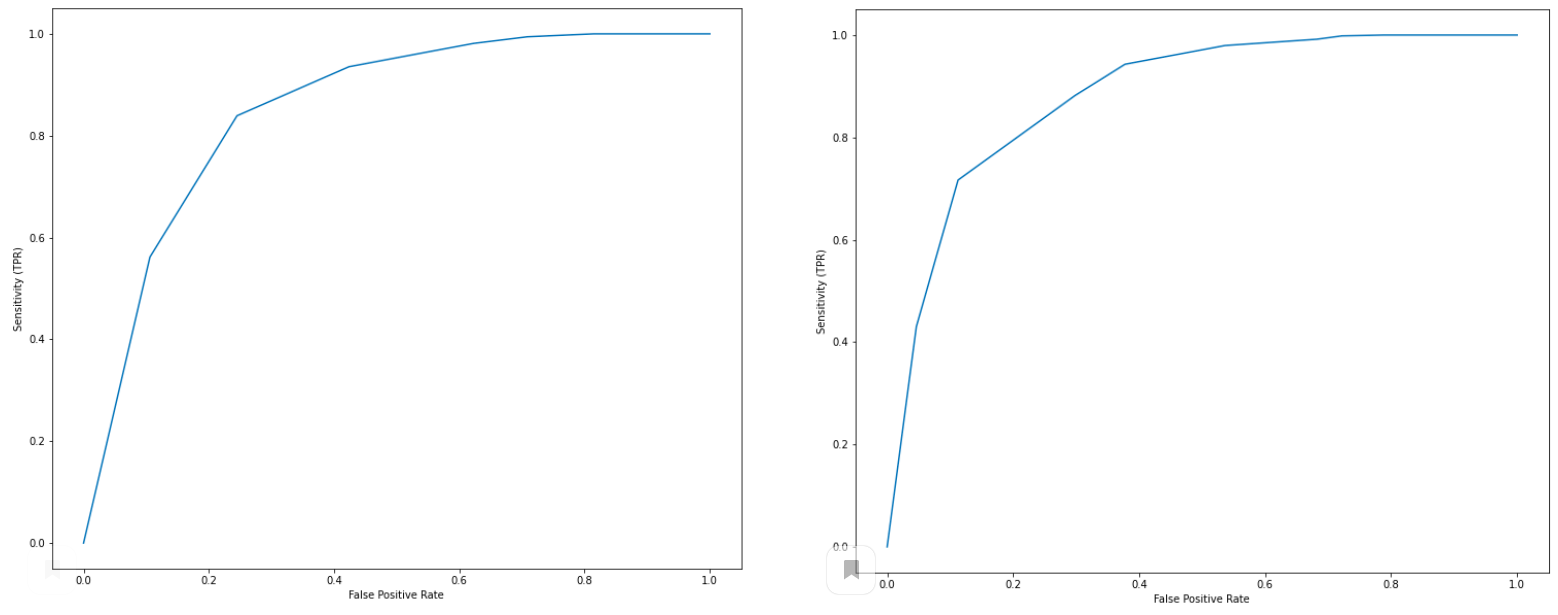
NLPAug дает возможность увеличения эффективности моделей (например, в терминах ROC-кривых) без изменения архитектуры и тонкой настройки нейросетей. В качестве примера можно рассмотреть датасет, состоящий из 7000 отзывов Yelp на кофейни, для которого выполняется анализ тональности текстов и сравнение с оценками кофеен по 5-балльной шкале, выставленными авторами отзывов. Исходно датасет сильно несбалансирован: количество положительных отзывов в 6.5 раз превышает количество отрицательных. В примере выполняется аугментация отрицательных отзывов: из каждого такого отзыва генерируется два новых, в которых максимум 3 слова меняются на синонимы. Выполнение этой операции занимает менее 1 минуты на CPU, требует менее 5 строк кода и приводит к увеличению показателя AUC с 0,85 до 0,88: