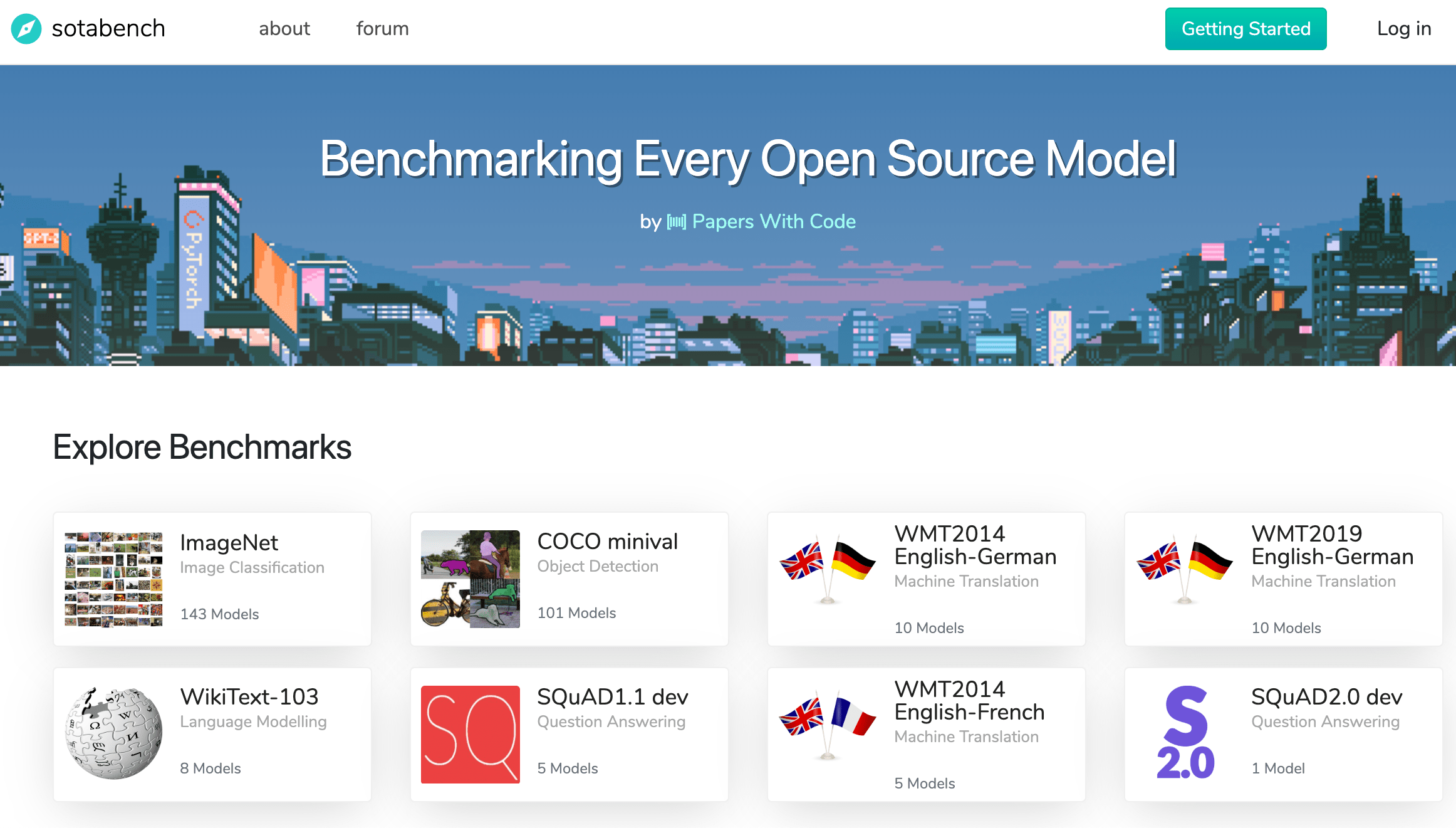
Sotabench — это платформа для агрегации и ранжирования моделей, которые решают отдельные задачи. Любой желающий может проверить свою модель на доступных задачах и сравнить с остальными моделями. На текущий момент доступно 8 задач: 2 из компьютерного зрения и 6 из обработки естественного языка. Проект был опубликован разработчиками Papers with Code.
Цель Sotabench в том, чтобы стандартизировать проверку работы открытых ML-моделей. Sotabench — это двойник проекта Papers with Code. Однако Papers with Code фокусируется на результатах, которые были опубликованы в оригинальных статьях. В то время как в Sotabench модели проверяются в системе.
Процесс проверки модели интегрирован с GitHub и доступен для любого желающего. Пользователи могут добавлять собственные модели и датасеты. Например, есть возможность загрузить на платформу свою имплементацию модели из статьи и сравнить ее с другими имплементациями без необходимости вручную прогонять эксперименты.
Как добавить свой репозиторий
Процесс добавления своего репозитория состоит из двух шагов: локально оценить модель и подключиться к GitHub репозиторию.
Каждая задача на Sotabench имеет свои инструкции по использованию. Например, чтобы использовать задачу классификации изображений на датасете ImageNet, необходимо создать .py файл определенного формата. Другой способ — использовать обертку на PyTorch для локальной оценки модели.
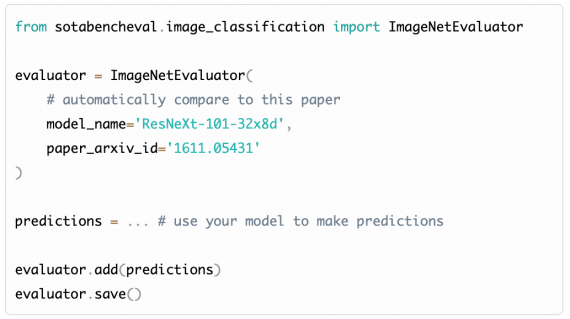
Разработчики сравнивают Sotabench с непрерывной интеграцией. Отличие в том, что вместо юнит-тестов, с каждым новым коммитом платформа пересчитывает модели.