Исследователи из UC Berkley разработали нейросеть, которая на основе речи человека генерирует жесты. Модель обходит state-of-the-art решения по количественной метрике. Исследователи опубликовали датасет с видеозаписями монологов и размеченными жестами, на котором обучалась нейросеть.
Когда человек говорит, он передает информацию не только вербально, но и с помощью жестов. Коммуникационные взмахи руками и схожие движения сопровождают речь человека и передают часть информации. Модель работает end-to-end: на вход получает спектограмму речи, а на выходе отдает те жесты ладонями и руками, которые спикер вероятнее всего совершит. Спектограмма — визуальное представление аудиоволны в виде 2D изображения. Модель обучалась на шумных размеченных автоматически данных.
Видеодемонстрация работы нейросети:
Данные
Исследователи представили датасет, который состоит из 144 часов видеозаписей с речью с распознанными жестами для каждого фрейма. В датасете присутствуют речи 10 различных спикеров, для которых можно было найти многочасовые видеозаписи монологов.
Спикеры были специально подобраны разнообразные: телеведущие, лекторы и публичные деятели. Контент речей ранжируется от химии до чтения религиозных трудов.
Архитектура модели
Обучение модели можно разделить на следующие шаги:
- Сверточный кодировщик аудиозаписи уменьшает размерность 2D спектограммы до 1D сигнала;
- Трансляционная модель (G) предсказывает соответствующий набор 2D поз;
- L1 регрессия рассчитывает ошибку между сгенерированными позами и настоящей разметкой;
- Состязательный дискриминатор отвечает за последовательность поз и их соответствие стилю невербальной коммуникации спикера
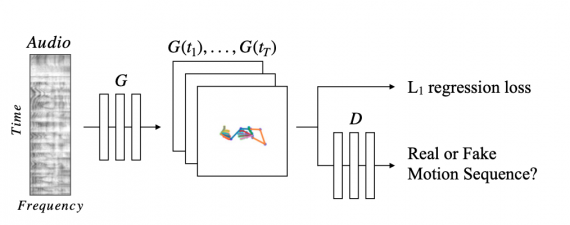
Архитектура в кодировщике аудизаписи — UNet. Предсказанные движения рук должны быть последовательны и плавные. Это достигается с помощью аудиокодировщика всего фрейма и предсказания всех поз фрейма сразу, а не рекуррентно.
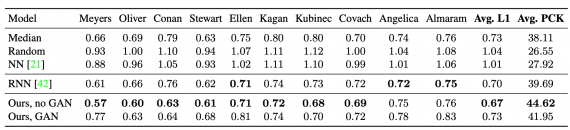
Сравнение моделей
Для сравнения в качестве простых решений были выбраны: предсказание медианной позы, предсказывание случайно выбранной позы, ближайшие соседи, RNN. Метрика оценки качества моделей — процент корректно предсказанных точек позы (PCK).
Видно, что модель без дискриминатора для большинства спикеров в данных давала лучшие результаты.