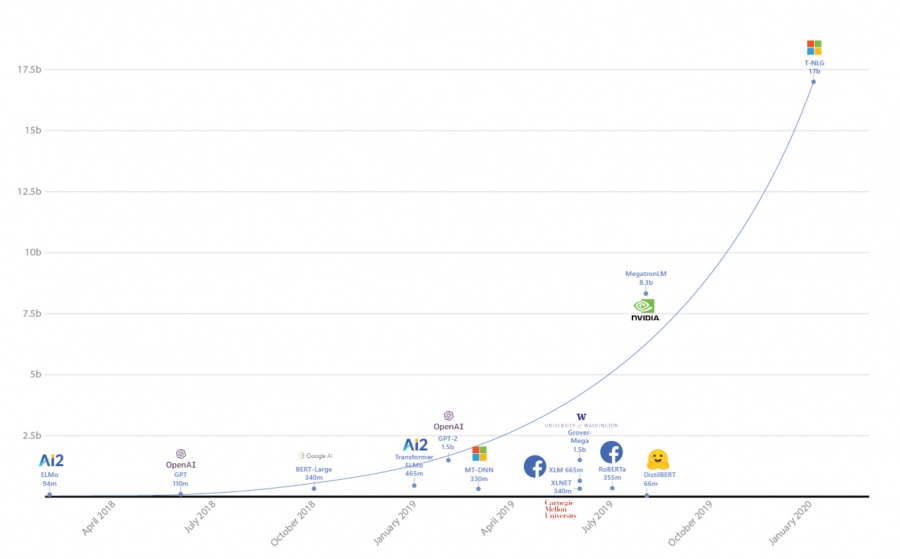
Turing Natural Language Generation (T-NLG) — это языковая модель с 17 миллиардами параметров, которую обучили исследователи из Microsoft. На данный момент это самая крупная языковая модель из существующих. T-NLG обходит state-of-the-art подходs на нескольких задачах из обработки естественного языка. Исследователи использовали библиотеку DeepSpeed и оптимизатор ZeRO, чтобы ускорить обучение модели. DeepSpeed — это библиотека для распределенного обучения DL моделей. Библиотека совместима с PyTorch. На данный момент модель находится в закрытом доступе.
Крупные языковые модели, как BERT и GPT-2, с миллиардами параметров стали state-of-the-art подходами на большинстве NLP задач. Среди задач — вопросно-ответная система, диалоговые агенты и понимание документов (document understanding).
Генеративные модели естественного языка могут применяться для ассистирования контент-мейкеров и для улучшения пользовательского опыта пользователей виртуальных ассистентов. Последние исследования в обработке естественного языка показывали, что увеличение размера модели положительно влияет на ее качество. Исследователи из Microsoft решили обучить модель, размер которой превысит размеры предыдущих моделей.
Предобучение T-NLG
Любую модель с более чем 1.3 миллиардом параметров нельзя поместить на единственную GPU. Это приводит к необходимости распараллелить процесс обучения модели на несколько GPU. Чтобы предобучить T-NLG, исследователи использовали:
NVIDIA DGX-2 систему, в которой GPU связаны с собой с помощью InfiniBand, что ускоряет взаимодействие между разными GPU;
Tensor slicing, чтобы разделить модель на 4 NVIDIA V100 GPU;
Библиотеку DeepSpeed и оптимизатор ZeRO;
Итоговая модель имеет 78 слоев Трансформера с скрытой размерностью 4256 и 28 attention heads. Чтобы результаты были сравнимы с Megatron-LM, исследователи предобучали модель с теми же гиперпараметрами.




