Ученые Итальянского университета совместно с исследователями из Australian Centre for Robotic Vision опубликовали алгоритм, который конвертирует демонстрационные видео в команды для роботов.
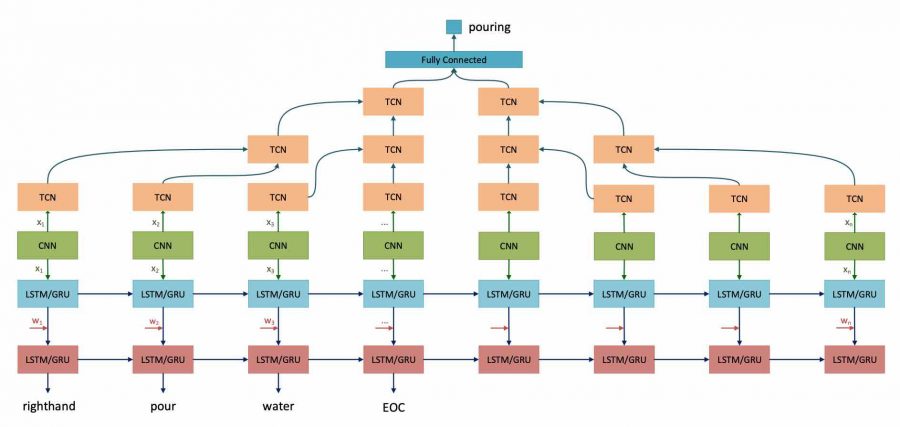
Архитектура V2CNet
Сеть V2CNet еть состоит из двух ветвей:
- ветвь классификации — использует входные объекты для изучения действия через сеть TCN;
- ветвь перевода — выполняет роль кодировщика-декодера с двумя слоями LSTM-GRU. Первый слой LSTM-GRU используется для кодирования визуальных объектов, после чего входные слова объединяются с выходом первого слоя LSTM-GRU и подаются во второй слой LSTM-GRU, чтобы последовательно генерировать выходные слова в виде команды.
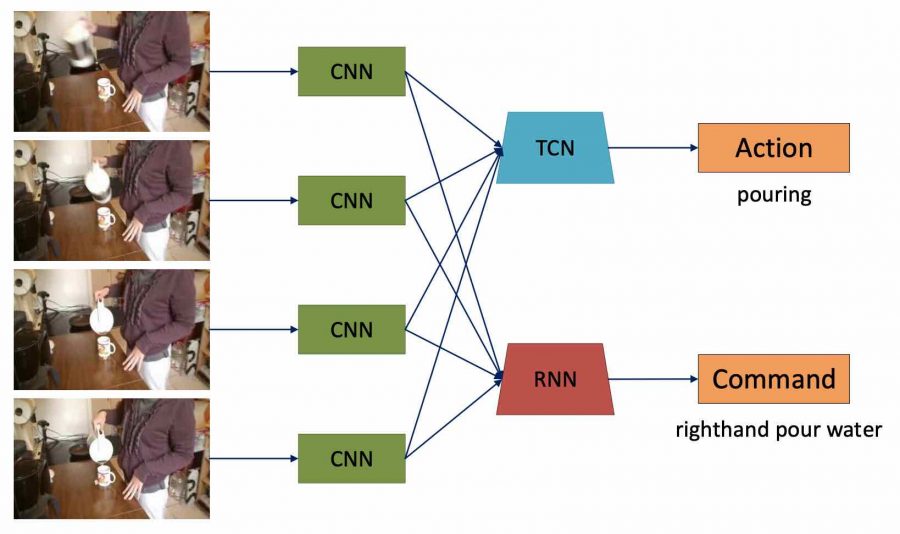
Датасет
Авторы предлагают новый способ выбора данных “video to — command” (IT-V2C), который фокусируется на тонком понимании действий в видеопотоке. С помощью IT-V2C создается новый датасет, который лучше подходит для обучения роботов, поскольку каждое действие в нем размечено максимально подробно.
Ниже приведен пример демонстрационных видео человека и покадровых действий в наборе данных IIT-V2C. Клипы записаны для сложных действий при различных условиях освещения:

Проверка модели
Для проверки модели исследователи создали дополнительный набор данных IIT-V2C, состоящий из видео демонстраций человека, вручную сегментированных на 11 000 коротких клипов, от 1 до 15 секунд, и аннотированных командным предложением, описывающим текущее действие. Авторы извлекали сказуемое из команды и использовали его в качестве класса действия для каждого видео. В результате этого было сформировано 46 классов.
Результаты
В экспериментах с использованием IT-V2C, методов извлечения признаков, а также с помощью рекуррентных нейронных сетей авторы утверждают, что нейросеть V2CNet успешно закодировала признаки для каждого видео и создала связанные команды. Результаты показывают, что использование сети TCN в классификации необходимо для повышения точности детекции и классификации.
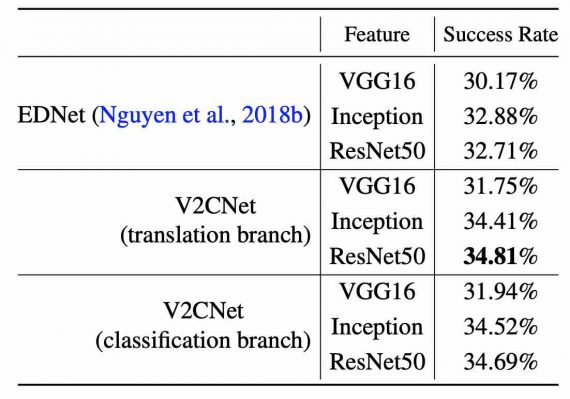
Тем не менее, показатель успеха классификации относительно низок, а проблема перевода видео в команды по-прежнему остается сложной, поскольку требует подробной разметки каждого механического действия.