Языковые модели обычно обучаются в два этапах: предварительное обучение без учителя и настройка под конкретные задачи и предпочтения пользователей. Новый метод LIMA (Less Is More for Alignment) основан на гипотезе, которая может перевернуть привычное представление о процессе обучения моделей.
Гипотеза поверхностного выравнивания
Согласно гипотезе поверхностного выравнивания (Superficial Alignment Hypothesis), почти все знания и способности моделей усваиваются во время предварительного обучения. Важный аспект настройки моделей на конкретные задачи — обучение модели отбирать подходящие форматы ответов. Если эта гипотеза верна, то достаточно настроить предварительно обученную модель языка на датасете из 1000 примеров.
В процессе исследования метода LIMA были проведены эксперименты, которые подтвердили гипотезу. Исследователи обучили модель с помощью предварительного обучения без учителя и использовали небольшой набор примеров для настройки модели на конкретные задачи и стилевые предпочтения пользователей.
Результаты LIMA
Для проверки гипотезы поверхностного выравнивания исследователи выбрали 1 000 примеров, схожих с реальными запросами пользователей, и высококачественные ответы к ним. 750 лучших вопросов и ответов отобраны на форумах, таких как Stack Exchange и wikiHow, с учетом качества ответов и разнообразия тем. 250 примеров составили вручную сгенерированные запросы и ответы, они обеспечили разнообразие задач и подчеркнули единообразный стиль ответа в духе искусственного интеллекта-ассистента. В конце обучили модель LIMA, предварительно обученную модель LLaMa с 65 миллиардами параметров, на этом наборе из 1 000 примеров.
Исследователи обнаружили, что для перехода от однократного следования инструкциям к диалогу с пользователем достаточно добавить всего 30 примеров диалогов к первоначальным 1000 примерам.

Удивительным образом, модель LIMA смогла достичь высокой производительности, используя небольшой набор примеров. Она научилась следовать определенным форматам ответов, включая сложные запросы, связанные с планированием путешествий или рассуждениями об альтернативной истории. Кроме того, модель демонстрировала хорошую обобщающую способность на незнакомых задачах, которые не представлялись в обучающих данных.
Сравнение ответов с другими моделями
Для сравнения LIMA с другими моделями генерировался один ответ для каждой тестовой подсказки. Затем волонтеры сравнивали ответы LIMA с каждой из базовых моделей и выбирали победителя. Эксперимент повторили, заменив волонтеров моделью GPT-4:
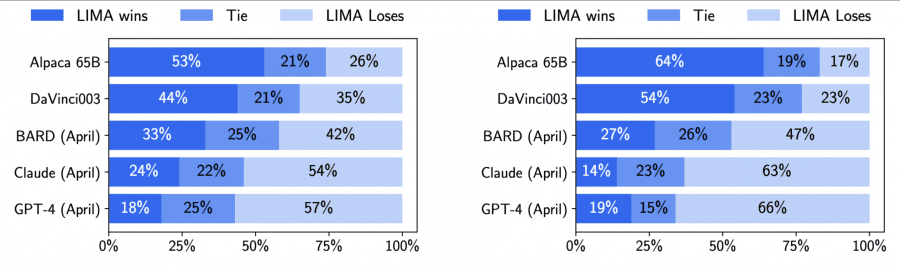
Ответы модели LIMA оказались эквивалентными или даже предпочтительными по сравнению с другими современными моделями, такими как GPT-4, Bard и DaVinci003. В случае сравнения с моделью GPT-4, LIMA показала лучшие или равные результаты в 43% случаев, а при сравнении с Bard и DaVinci003 эта статистика достигала 58% и 65% соответственно.
Было обнаружено, что качество вывода модели может значительно варьироваться в зависимости от того, что ей подается на вход, даже при использовании 2000 примеров. В частности, была обнаружена значительная разница между фильтрованными и нефильтрованными ответами на Stack Exchange:
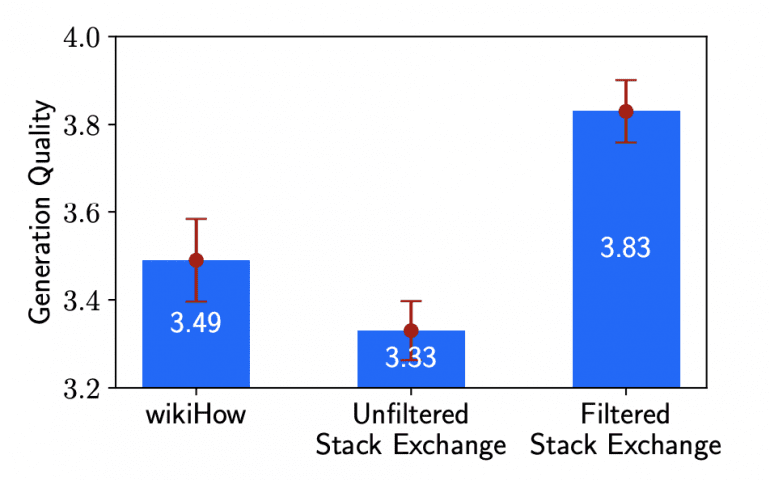
Результаты исследования подтверждают гипотезу о поверхностном выравнивании и указывают на то, что основная часть знаний, содержащихся в больших языковых моделях, усваивается во время предварительного обучения. Для обучения модели достаточно 1000 примеров, чтобы она могла генерировать высококачественный вывод под конкретную задачу. Это может значительно снизить затраты на обучение моделей и сделать процесс более эффективным и доступным.
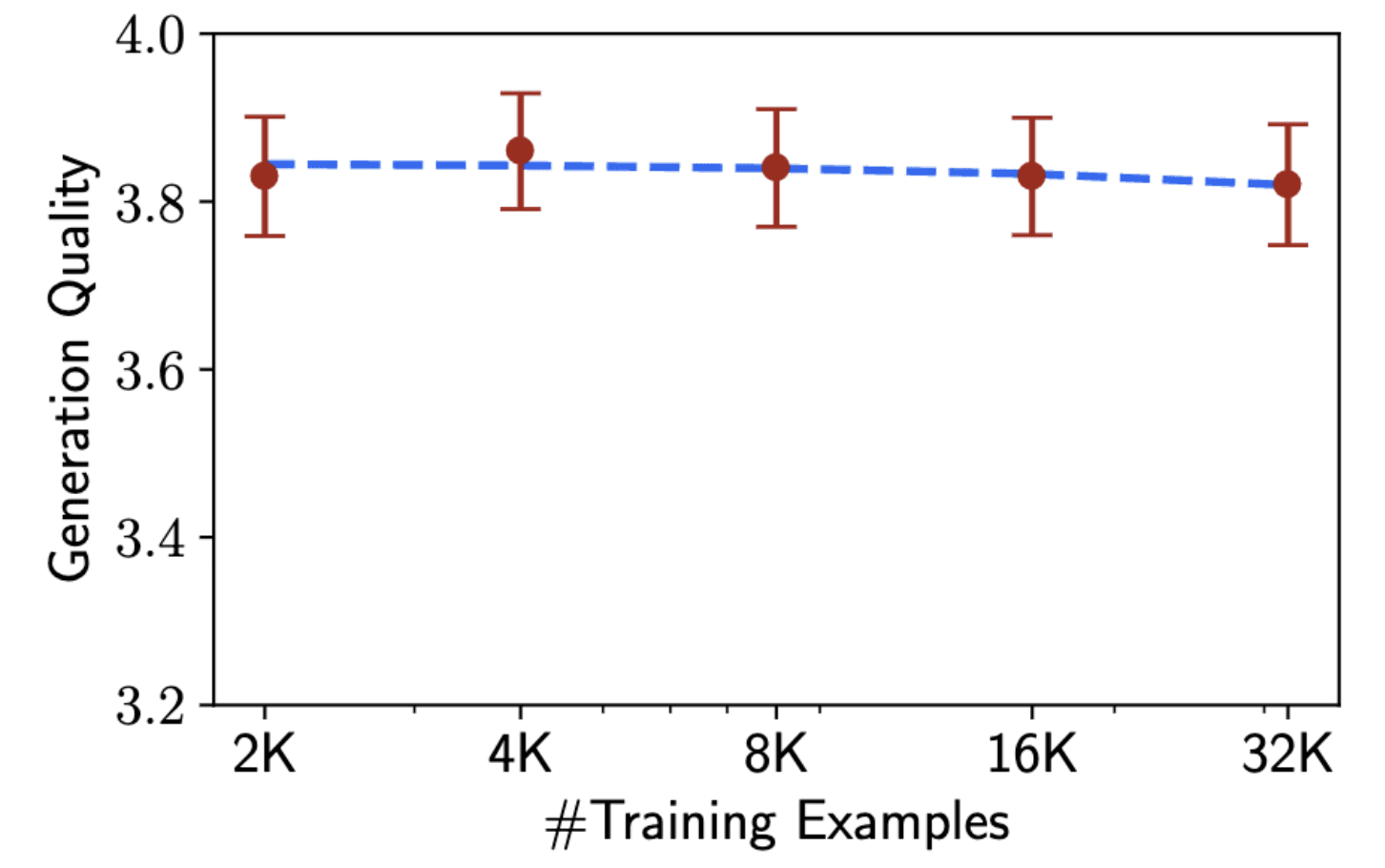
Однако необходимо продолжить исследования в этой области и подтвердить результаты метода LIMA с помощью дополнительных экспериментов. Возможно, дальнейшие исследования помогут расширить эти результаты и улучшить методы обучения языковых моделей.
Метод LIMA открывает новые перспективы в обучении языковых моделей и может привести к разработке более эффективных и точных моделей. Подтверждение гипотезы о поверхностном выравнивании позволит дальше углубиться в понимание процесса обучения моделей и оптимизировать их для различных задач обработки естественного языка.