Исследователи из DeepMind предложили использовать модифицированный вариационный автокодировщик для генерации правдоподобных разноплановых изображений. VQ-VAE-2 конкурирует по результатам с state-of-the-art подходами. Архитектура помогает избавиться от недостатков использования GAN-ов для генерации изображений.
Сейчас для генерации изображений стандартным подходом является использовать генеративные нейросети (GANs). Несмотря на их популярность, они имеют такие проблемы, как недостаток разнообразия сгенерированных изображений и остановка работы генератора, которая приводит к генерации части множеств изображений (mode collapse). Исследователи модифицировали Vector Quantized Variational AutoEncoder (VQ-VAE), чтобы решить эти проблемы.
Архитектура модели
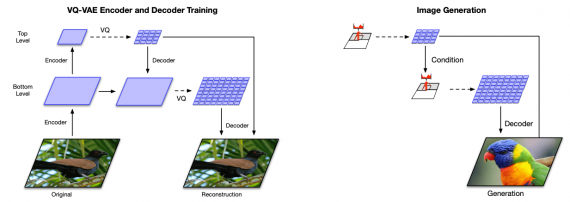
Стандартную VQ-VAE модель можно представить как систему коммуникации кодировщика и декодировщика. Кодировщик преобразует изображение в латентные переменные, а декодировщик реконструирует изображение из латентных переменных.
VQ-VAE-2, вместо одного преобразования, делает два: на верхнем и нижнем уровнях. На верхнем уровне моделируются глобальные характеристики изображения, а на нижнем уровне, который зависит от результата верхнего, моделируются локальные характеристики. Предложенная модификация заключается в добавлении иерархичности.
Сам процесс обучения состоит из двух шагов:
- Сначала обучается VQ-VAE-2, чтобы закодировать изображения в скрытое дискретное пространство;
- Затем с помощью PixelCNN генерируется изображение
Такая структура позволяет генерировать более устойчивые и реалистичные изображения.
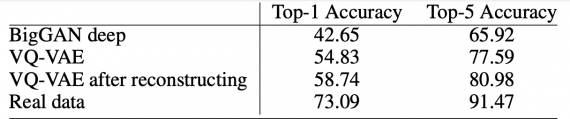
Оценка работы модели
Исследователи обучили проверяли модель на данных ImageNet 256 × 256 и FFHQ. Последний датасет состоит из 70000 высококачественных портретов людей с разнообразными внешними характеристиками. Несмотря на то, что генерация лиц считается менее сложной задачей, чем ImageNet, модель должна уметь запоминать такие зависимости, как цвет глаз. В качестве конкурирующей архитектуры была выбрана BigGAN deep. Ниже видно, что VQ-VAE-2 обладает более высокой точностью, чем конвенциональная генеративная нейросеть.