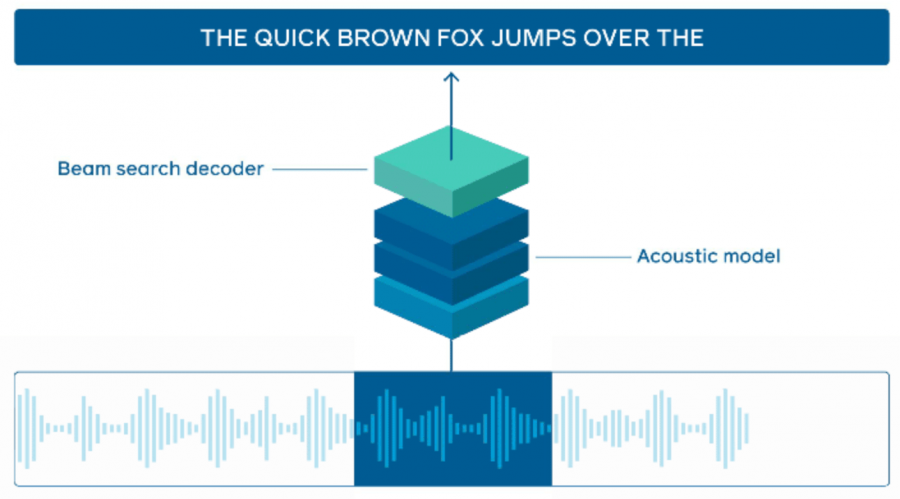
Онлайн распознавание речи — это задача транскрибирования речи в реальном времени из входного потока аудиоданных. FAIR опубликовали нейросетевую модель, которая обходит state-of-the-art подходы для онлайн распознавания речи на датасете LibriSpeech.
Большинство исследований по автоматическому распознаванию речи фокусируются на улучшении точности существующий моделей, вместо оптимизации инференса для использования модели в реальном времени. Для такой задачи, как генерация субтитров видео, задержка между аудио и появлением субтитров должна быть минимальной. В таком случае системы по онлайн распознаванию речи сталкиваются с ограниченными временными ресурсами на генерацию текста из аудио. Чтобы решить эту проблему, исследователи предлагают использовать фреймворк для инференса Wav2letter@anywhere. Wav2letter@anywhere основан на ранее опубликованных моделях wav2letter и wav2letter++.
Существующие подходы по большей части поддерживают исключительно рекуррентные нейросети. В Wav2letter@anywhere используется сверточная архитектура. Такой подход позволяет обрабатывать данные в 3 раза быстрее и достигает state-of-the-art точности.
Как это работает
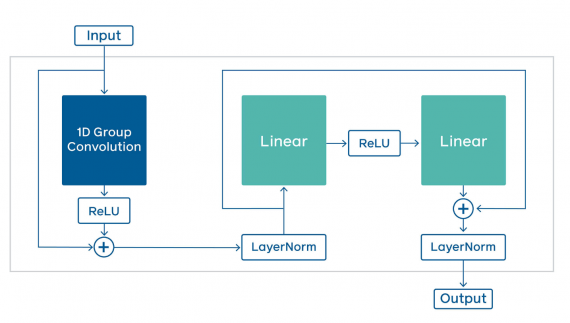
Ключевой составной частью wav2letter@anywhere модели является time-depth separable (TDS) свертка. TDS позволяет заметно сократить размер модели и количество выполняемых операций без потери в точности предсказаний.
Тестирование работы модели
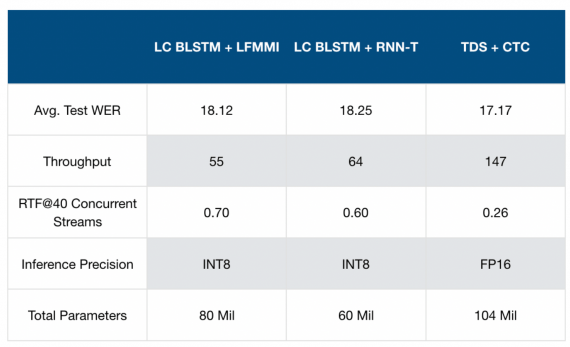
Исследователи сравнили Wav2letter@anywhere с двумя базовыми подходами: LC BLSTM + lattice-free MMI hybrid system и LC BLSTM + RNN-T end-to-end system. Ниже видно, что Wav2letter@anywhere выдает более точные результаты при более высокой проходимости. Однако количество параметров в предложенной модели выше по сравнению с конкурирующими нейросетями.