Большая часть исследований на стыке компьютерного зрения и NLP фокусируется на наборе небольших задач, которые изучаются по отдельности. Однако навыки обработки визуальной и текстовой информации для решения разных задач значительно перекликаются. Исследователи обучили одну нейросетевую модель, которая решает 12 задач из области vision-and-language так же хорошо или лучше, чем state-of-the-art.
Задачи включают в себя:
- Визуальную вопросно-ответную систему (visual question answering);
- Извлечение изображения по подписи (caption-based image retrieval);
- Распознавание объектов на изображении по описанию (grounding referring expressions);
- Мультимодальная проверка (multi-modal verification)
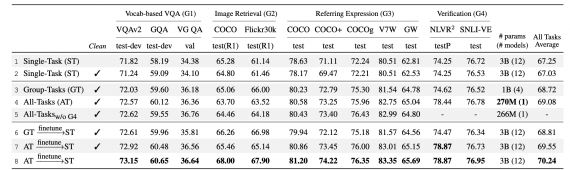
12-в-1 модель позволяет сократить число параметров модели с 3 миллиардов до 270 миллионов в сравнении с моделями, обученными для отдельных задач. При этом в среднем качество предсказаний модели возрастает на 2.05 пунктов для всех задач.
Обучение модели
В качестве архитектуры модели исследователи используют ViLBERT. Нейросеть решает 6 задач на 12 датасетах. Предобучали модель на датасете Conceptual Caption. Предобученную модель затем дообучали на 12 датасетах, которые принадлежали к одной из 6 задач.
Оценка работы нейросети
Исследователи сравнили обученную многозадачную модель с моделями, которые обучали на отдельных задачах. Многозадачное обучение позволяет в среднем улучшить качество модели.