Исследователи из DeepMind обучили генеративную модель, которая сегментирует действия на видеозаписи. Модель обучается распознавать действия без реальной разметки действий на видеозаписи. Несмотря на свою простоту, алгоритм выдает сравнимые с state-of-the-art результаты.
Описание задачи
Поиск границ в непрерывном потоке информации — это один из основных процессов в человеческом сознании. Чтобы понять и запомнить, что происходит в окружающем мире, человек должен уметь распознавать границы начала и окончания действий. Кроме того, необходимо отдель значимые действия от незначительных. Задача модели заключается в том, что бы выделить в видеозаписи части, которые ответственны за отдельные действия, и классифицировать эти действия. Такая проблема называется временной сегментацией действий (temporal action segmentation). Прошлые исследования фокусируются на случае, когда модели доступна разметка видеозаписи на действия. Исследователи в DeepMind предлагают архитектуру модели, которая обучается без учителя или с частичным привлечением учителя.
Данные для обучения
Для обучения модели исследователи использовали датасет CrossTask. В датасете каждое видео привязано к определенному действию. Например, сделать кофе. Задачи были взяты из статей WikiHow, а видео — из поискового результата YouTube. Обучающие данные содержат 2,700 видеозаписей с 18 разными действиями.
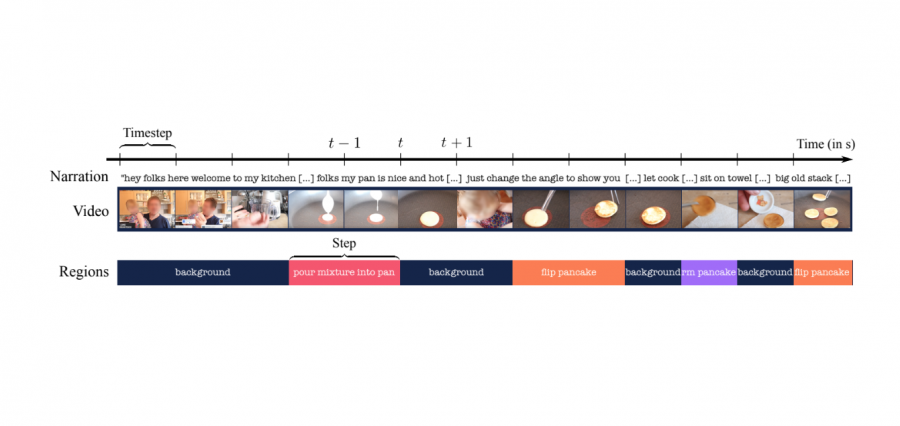
Видеозапись с задачей разбита на подзадачи, которые последовательно приводят к решению задачи. Для каждого видео есть разметка, на каком момент начинается и заканчивается подзадача. Модель учится сегментировать видеозапись на участки с подзадачами и классифицировать подзадачи. При этом во время обучения модели недоступна разметка подзадач.
Архитектура подхода
Исследователи используют полумарковскую модель первого порядка (first-order semi-Markov model). Выбор архитектуры обуславливается тем, что полумарковская модель напрямую моделирует временные участки, их длину, вероятностное распределение и признаки. Модель при обучении максимизирует вероятность признаков. Это позволяет обучать алгоритм без размеченных временных участков на видеозаписи.

Результаты экспериментов
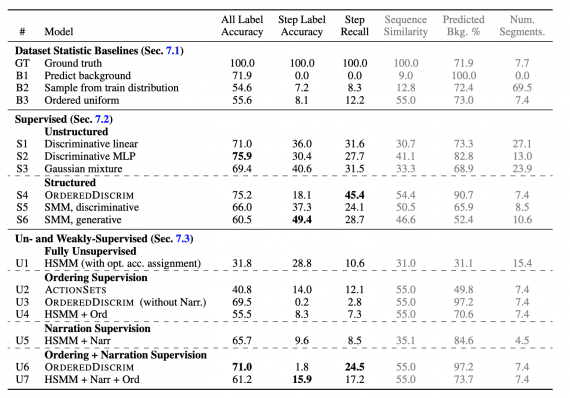
Исследователи сравнивают предложенную генеративную модель с алгоритмами из Zhukov et al. (2019) и Richard et al. (2018). Кроме того, они использовали статистики по датасету в качестве статических бейзлайнов. По результатам экспериментов, видно, что предложенная модель выдает схожие с state-of-the-art результаты.