
ByteDance и POSTECH представили токенизатор TA-TiTok (Text-Aware Transformer-based 1-Dimensional Tokenizer), новый подход к созданию доступных и эффективных text-to-image моделей. Маскированная генеративная модель MaskGen с токенизотором TA-TiTok достигла SOTA для text-to-image моделей, обучаясь только открытых данных. Исследователи опубликовали код и веса модели на Github.
Технические детали TA-TiTok
TA-TiTok — это токенизатор, который отвечает за преобразование изображений в компактные представления (токены). Его основная цель — эффективно преобразовывать изображения в последовательности токенов, которые могут обрабатываться генеративными моделями.
TA-TiTok уникальным образом интегрирует текстовую информацию на этапе детокенизации, ускоряя сходимость и улучшая производительность. TA-TiTok также выигрывает от упрощенного, но эффективного одноэтапного процесса обучения, устраняя необходимость в сложной двухэтапной дистилляции, используемой в предыдущих одномерных токенизаторах. Такая архитектура обеспечивает беспрепятственное масштабирование на большие наборы данных.
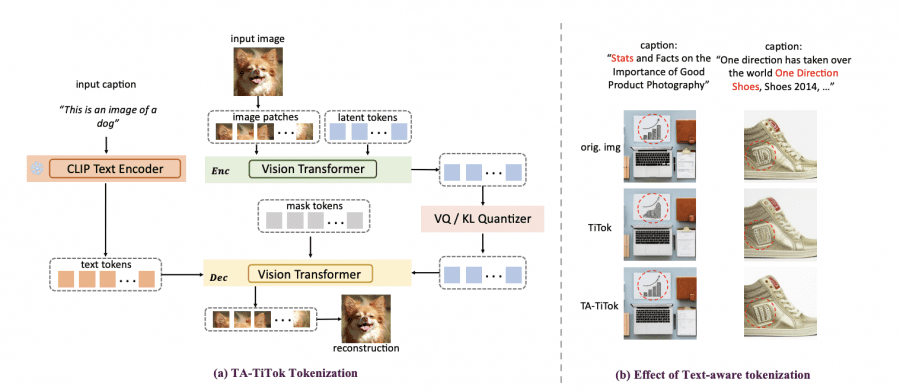
Исследователи представила три фундаментальных улучшения оригинального фреймворка TiTok:
- Оптимизированный процесс обучения. Исследователи заменили традиционное двухэтапное обучение одноэтапным.
- Поддержка двух типов токенов. TA-TiTok реализует как дискретные (VQ), так и непрерывные (KL) форматы токенов:
- Векторно-квантованный (VQ) вариант обеспечивает прямое отображение в записи кодовой книги
- Вариант с ключевыми потерями (KL) позволяет использовать непрерывное латентное пространство. Эта гибкость позволяет оптимизироваться под конкретные задачи и требования к производительности.
- Обработка с учетом текста. Интегрируя текстовый энкодер CLIP на этапе детокенизации, TA-TiTok достигает лучшего семантического соответствия между генерируемыми изображениями и текстовыми описаниями.
Модель MaskGen
MaskGen — это генеративная модель, которая использует токенизацию TA-TiTok для преобразования текста в изображение. Она принимает токены, созданные TA-TiTok, вместе с промтом и создает новые изображения. MaskGen представлена в разных размерах (MaskGen-L с 568 млн параметров и MaskGen-XL с 1,1 млрд параметров) и может работать как с дискретными, так и с непрерывными токенами от TA-TiTok.
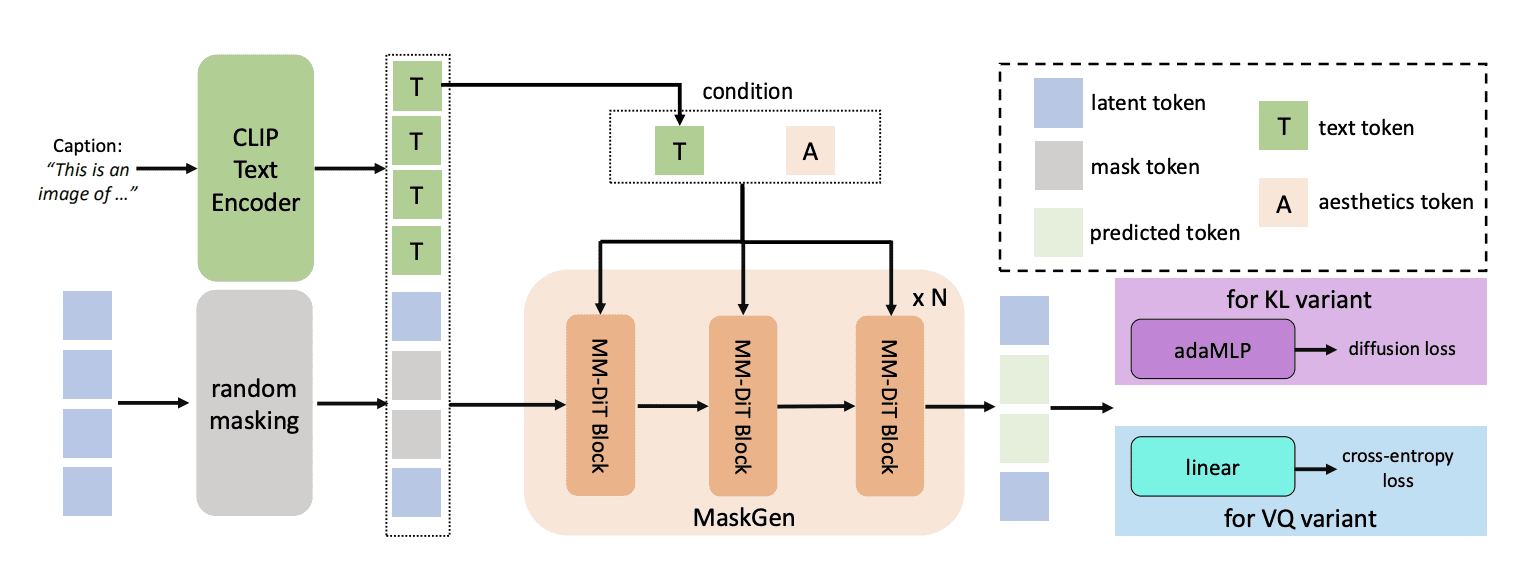
Реализация на открытых данных
Модель обучена исключительно на публичных датасетах: DataComp, CC12M, LAION-aesthetic, JourneyDB, DALLE3-1M.
Исследователи использовали критерии фильтрации для оценки качества данных, включая требования к разрешению и оценки эстетических качеств изображения.
Количественные показатели производительности
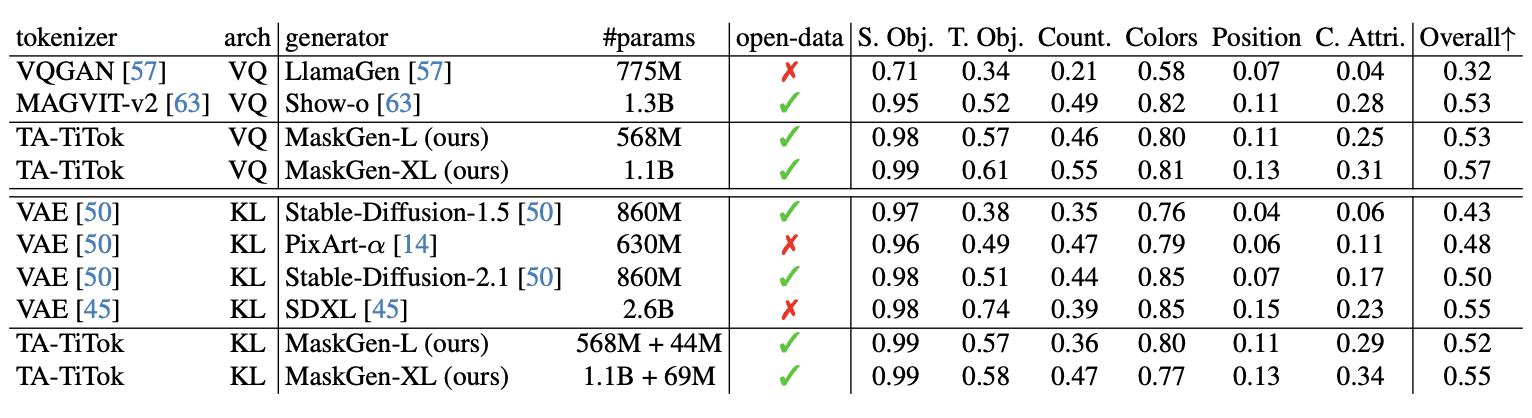
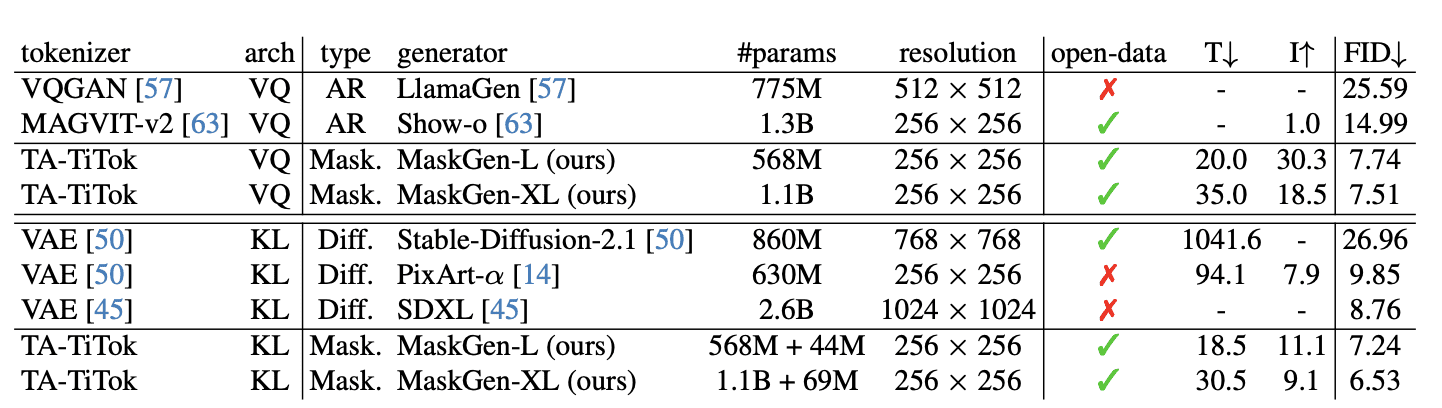
Сравнение метрик производительности:
- MaskGen-L (568 млн параметров) достигает показателя FID 7,74 на MJHQ-30K, превосходя Show-o (14,99) при этом предлагая в 30,3 раза более быстрый инференс
- Модель требует всего 2% времени обучения по сравнению с SD-2.1 при достижении лучшей производительности
- MaskGen-XL (1,1 млрд параметров) достигает показателей FID 7,51 и 6,53 на MJHQ-30K при использовании дискретных и непрерывных токенов соответственно.
Вычислительные требования
Необходимые вычислительные затраты для работы модели:
- Время обучения: 20,0 8-A100 дней для MaskGen-L и 35,0 8-A100 дней для MaskGen-XL
- Размеры батча: 4096 для дискретных токенов и 2048 для непрерывных токенов
- Скорость обучения и параметры оптимизации полностью детализированы для воспроизведения
MaskGen представляет собой одну из первых масочных генеративных моделей с открытым весом и открытыми данными, достигающую производительности, сопоставимой с современными моделями.






