Предположим, что у вас есть корпус, подобный The Pile, состоящий из 22 доменов: веб-страницы, Википедия, новости, Github, книги. Исследователи Google и Stanford University предложили алгоритм DoReMi для оптимизации пропорций выборок из разных доменов, чтобы ускорить обучение больших языковых моделей.
Алгоритм «Перевзвешивание доменов с использованием минимакс-оптимизации» (DoReMi) сначала обучает небольшую прокси-модель с использованием метода групповой распределительно-устойчивой оптимизации (Group DRO) по доменам для получения пропорций доменов без знания о последующих задачах.
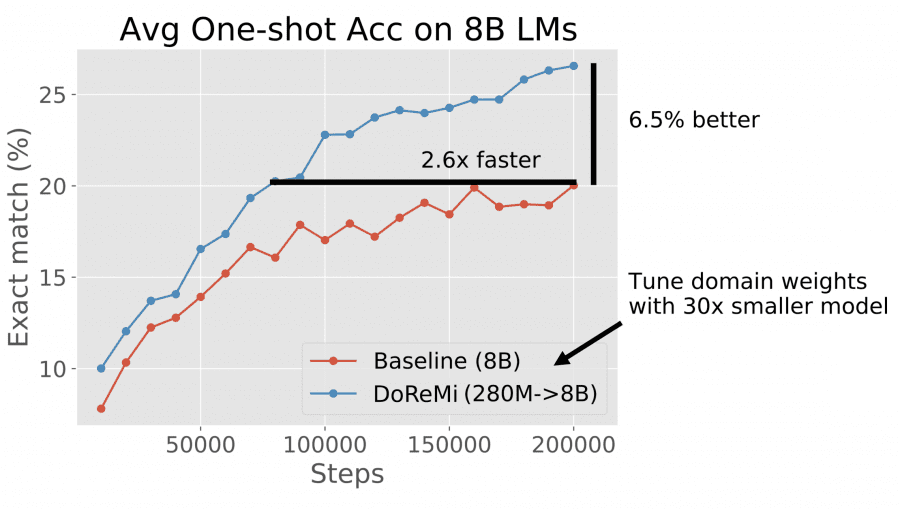
Исследователи оптимизировали веса небольшой модели с 280 млн. параметров для обучения в 30 раз большей модели с 8 млрд. параметров, затратив на 92% меньше вычислительных ресурсов. DoReMi улучшает точность единичного спуска по средним значениям на 6,5 пункта и достигает базовой точности в 2,6 раза быстрее при предварительном обучении на The Pile.
Метод
Метод состоит из трех шагов. В первом шаге легкая эталонная модель обучалась на полном корпусе с одинаковыми пропорциями доменов. Второй шаг — «оптимизация с распределительной устойчивостью» (Group DRO) для получения весов для каждого датасета. Наконец, большая модель обучалась с использованием полученных пропорции доменов.
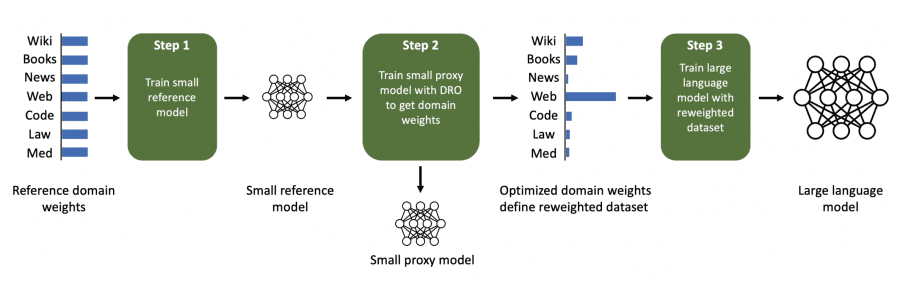
Сложным является второй шаг — распределительная устойчивая оптимизация. В основе этого метода лежит обучение модели таким образом, чтобы минимизировать потери на самом плохом наборе данных. Для этого усиливаются градиенты из наборов данных, на которых модель в настоящий момент показывает худшие результаты.
Важно отметить, что здесь используется не сырые значения потерь, а разница между текущими потерями и потерями, полученными эталонной моделью. Эта уменьшаемая потеря помогает сосредоточиться на данных, которые могут быть изучены, но еще не были полностью освоены.
Процесс повторяется несколько раз для улучшения результата. Веса датасетов из предыдущей итерации используются в качестве отправной точки для следующей итерации.
Результат
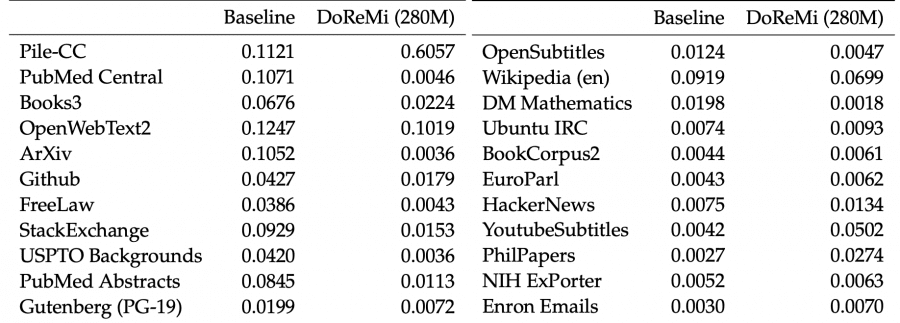
Удивительно, использование этих весов улучшает перплексию для каждого набора данных, включая те, которые были уменьшены.
Их весовая схема также улучшает метрики оценки на выходе:
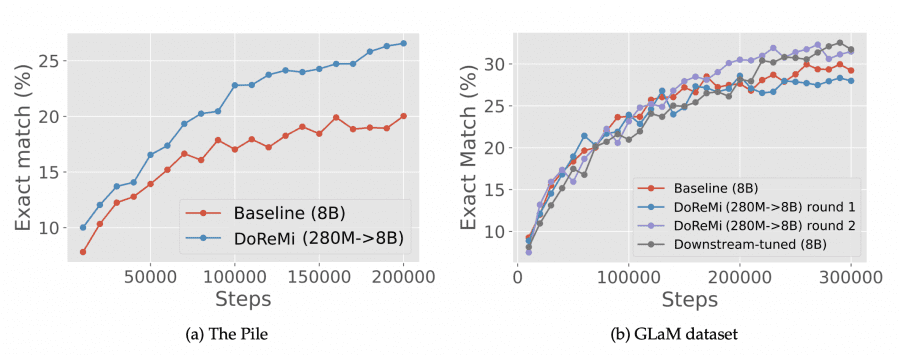
Поскольку The Pile общедоступен, эти веса датасетов могут быть немедленно использованы исследователями, которые занимается предварительным обучением текстовых моделей.







