
Gorilla — модель, обученная на основе LLaMA, которая превосходит производительность GPT-4 в написании вызовов API. Gorilla генерирует корректные вызовы API для моделей машинного обучения без галлюцинаций, адаптируется к изменениям в документации и принимает во внимание ограничения API. Производительность настроенной модели превосходит GPT-4 на трех масштабных наборах данных.
Исследователи выложили код, модель, данные и демонстрацию Gorilla в отрытом доступе.
Подробнее о Gorilla
Gorilla позволяет большим языковым моделям использовать инструменты вызова API. Получая на вход запрос на естественном языке, модель находит семантически и синтаксически правильное API для вызова. С помощью Gorilla впервые продемонстрировано, как использовать LLMs для точного вызова более 1 600 API (их число постоянно растет).
На картинке показан алгоритм обучения и работы модели. Верхняя часть представляет собой процедуру обучения: авторы собрали исчерпывающий набор данных API для машинного обучения. Во время вывода (нижняя часть) модель поддерживает два режима — с извлечением и без извлечения. В примере она способна предложить правильный вызов API для создания изображения на основе запроса пользователя на естественном языке.
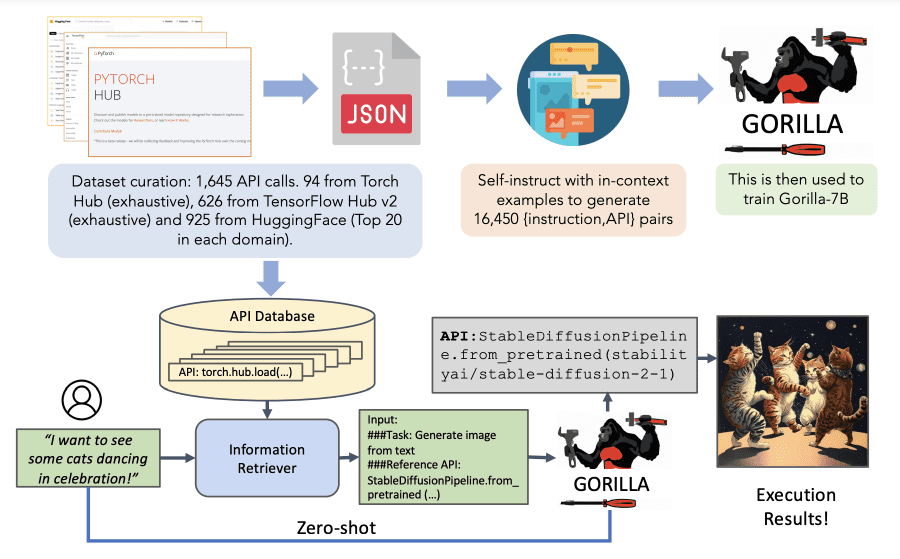
Для оценки возможностей модели авторы создали набор данных APIBench, который включает в себя API HuggingFace, TorchHub и TensorHub. Если хотите добавить свое API, просто создайте пул-реквест в репозитории и напишите авторам на электронную почту.
Пример вызова API
Модель способна правильно определить задачу и предложить полностью подходящий вызов API. Примеры вызовов API, сгенерированные GPT-4, Claude и Gorilla для данного запроса показаны на примере ниже. GPT-4 предлагает несуществующую модель, а Claude выбирает неправильную библиотеку.

Поскольку API функционируют как универсальный протокол общения между программами, правильное использование может улучшить возможность LLMs взаимодействовать с другими инструментами.






