Команда Mistral AI представила Mistral 7B — открытую языковую модель из 7,3 миллиардов параметров, которая превосходит вдвое большую модель Llama 2 13B на всех бенчмарках. При этом Mistral 7B достигает сравнимых результатов с Code Llama 2 в задачах генерации и исправления кода, хотя она не дообучалась специально для этих задач. Mistral 7B удалось достичь такого результата благодаря grouped-query механизму внимания и скользящему окну внимания (sliding window attention) при обучении на длинных последовательностях.
Подробнее о модели
Приятные особенности Mistral 7B
- Mistral 7B распространяется под лицензией Apache 2.0, что ее можно использовать как угодно без ограничений и свободно дообучать для своих задач. Вы можете запустить ее локально, развернуть на облачных платформах — AWS, GCP, Azure, или использовать на HuggingFace.
- Отсутствие цензуры. Mistral 7B готова отвечать на все вопросы и обсуждать любые темы. Никаких политик безопасности и ответственного использования не предусмотрено.
Flash attention
Mistral 7B использует механизм скользящего окна внимания (SWA), в котором каждый слой обращается к предыдущим 4,096 скрытым состояниям. Основное улучшение — линейная вычислительная сложность O(sliding_window.seq_len). На практике изменения, внесенные в FlashAttention и xFormers, обеспечивают увеличение скорости в 2 раза для длины последовательности 16k с окном 4k.
Механизм скользящего окна внимания использует слои трансформера, чтобы обращаться к прошлому состоянию за пределами размера окна: токен i на слое k обращается к токенам [i-sliding_window, i] на слое k-1. Эти токены обращаются к токенам [i-2*sliding_window, i]. Верхние слои имеют доступ к информации, находящейся дальше в прошлом, чем это подразумевает структура внимания.
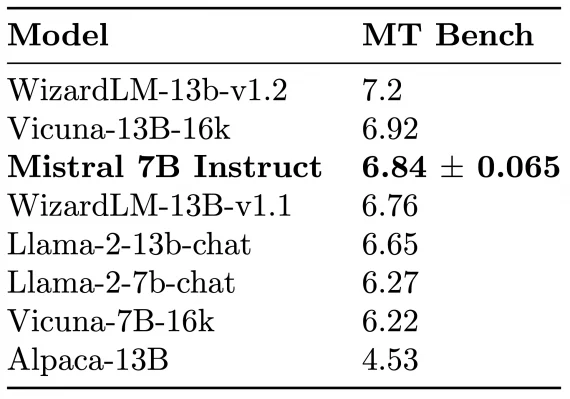
Для демонстрации возможностей fine-tuning, команда дообучила Mistral 7B Chat — и она опередила Llama 2 13B Chat и Alpaca 13B на тесте MT-Bench:
Как использовать модель
Разработчики предлагают три варианта использования Mistral 7b:
- Скачать модель, запустить код с инференсом модели локально;
- Развернуть модель на облачном сервисе — AWS, Microsoft Azure, Google Cloud при помощи skypilot;
- Пользоваться на HuggingFace.
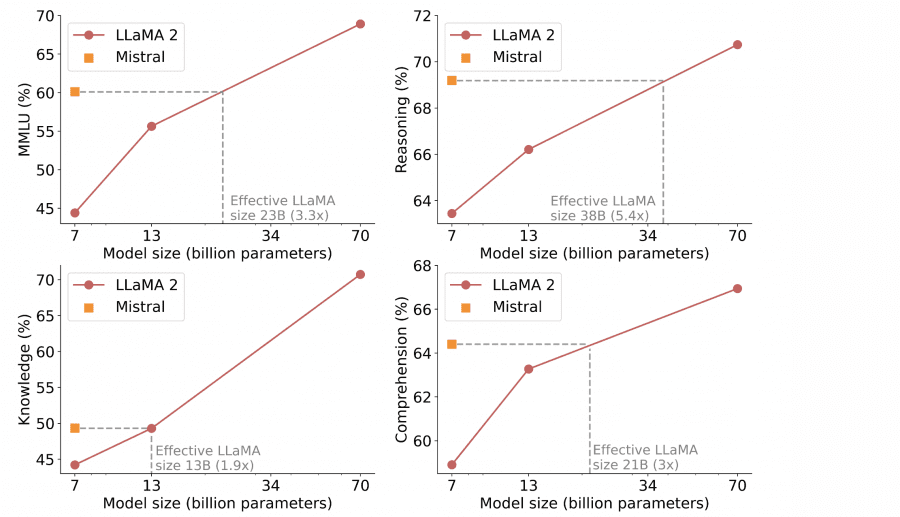
Результаты Mistral 7B
Производительность модели Mistral 7B и различных моделей Llama была оценена на группах бенчмарков:
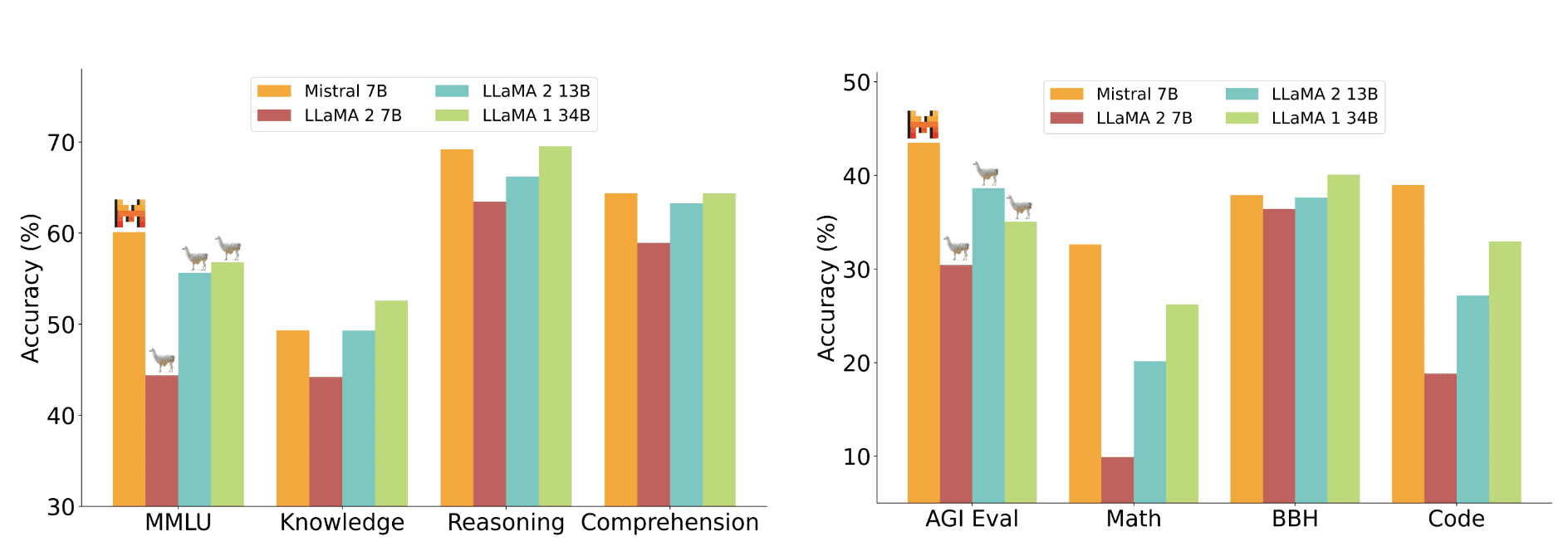
Mistral 7B значительно превосходит Llama 2 13B по всем метрикам и находится на уровне с Llama 34B (поскольку Llama 2 34B не была выпущена в открытом доступе, сравнивали с Llama 34B).
В таблице указаны результаты отдельно по каждому бенчмарку: