Microsoft опубликовала веса DragNUWA – кросс-доменной модели генерации видео, обеспечивающей более прецизионный контроль над получаемым результатом по сравнению с аналогичными моделями. Контроль достигается за счет одновременного использования в качестве входных данных текстового запроса, изображений и траекторий объектов.
В предыдущих моделях генерации видео входными данными служил только текстовый запрос, в некоторых из них – еще и изображение, которое необходимо анимировать. Такой подход не позволяет полностью достичь желаемых результатов из-за трудностей текстового описания движения камеры и траекторий объектов.
Для решения данной проблемы Microsoft разработала DragNUWA, диффузионную модель, которая объединяет три домена – изображения, текст и траектории – для обеспечения полного управления семантикой, сценой и динамикой видео. Ключевое преимущество модели заключается в возможности гибкого задания угла обзора сцены, движения камеры и траекторий движущихся объектов.
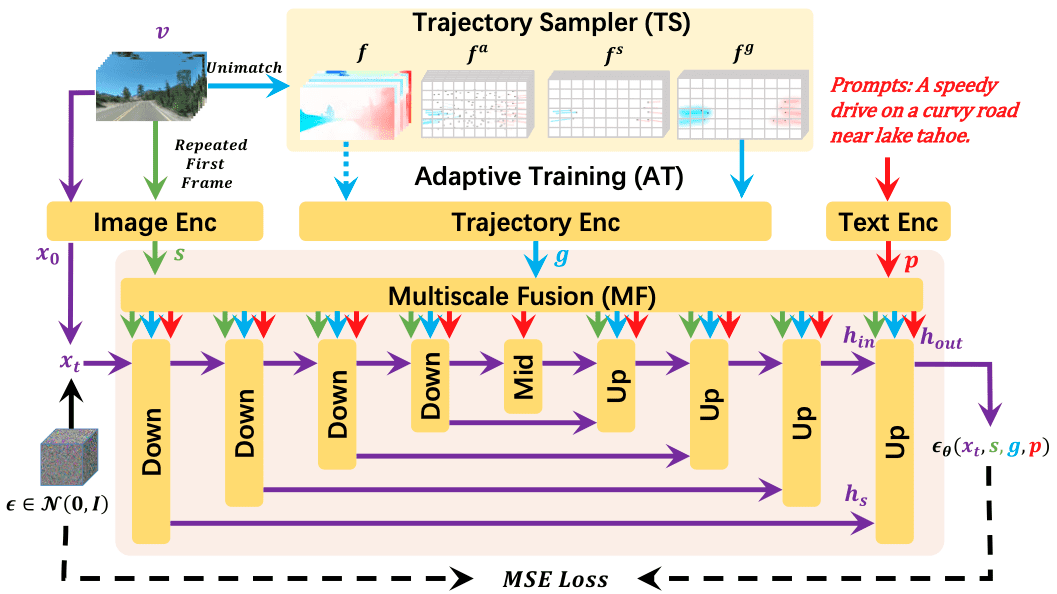
Например, можно загрузить изображение лодки в водоеме и добавить текстовую подсказку “лодка плывет по озеру”, а также указания, обозначающие траекторию движения лодки и течения воды. Траектория обеспечивает детализацию движения, текст описывает детали будущих объектов, а изображения помогают модели понять, в каком стиле должны быть изображены объекты. Модель позволяет реализовывать сложные траектории, например, движение игрока в футбол.
Microsoft опубликовала веса модели и демоверсию проекта в открытом доступе.