MinerU — open-source модель для извлечения и структурирования контента из документов, представленная исследователями из Лаборатории Искусственного Интеллекта Шанхая. MinerU автоматизирует извлечение текста, формул, таблиц и изображений из документов, таких как научные статьи, учебные пособия и финансовые отчеты, преобразуя их в форматы Markdown и JSON. Это решение облегчает интеграцию данных в NLP-модели и базы знаний.
MinerU поддерживает следующие типы данных: 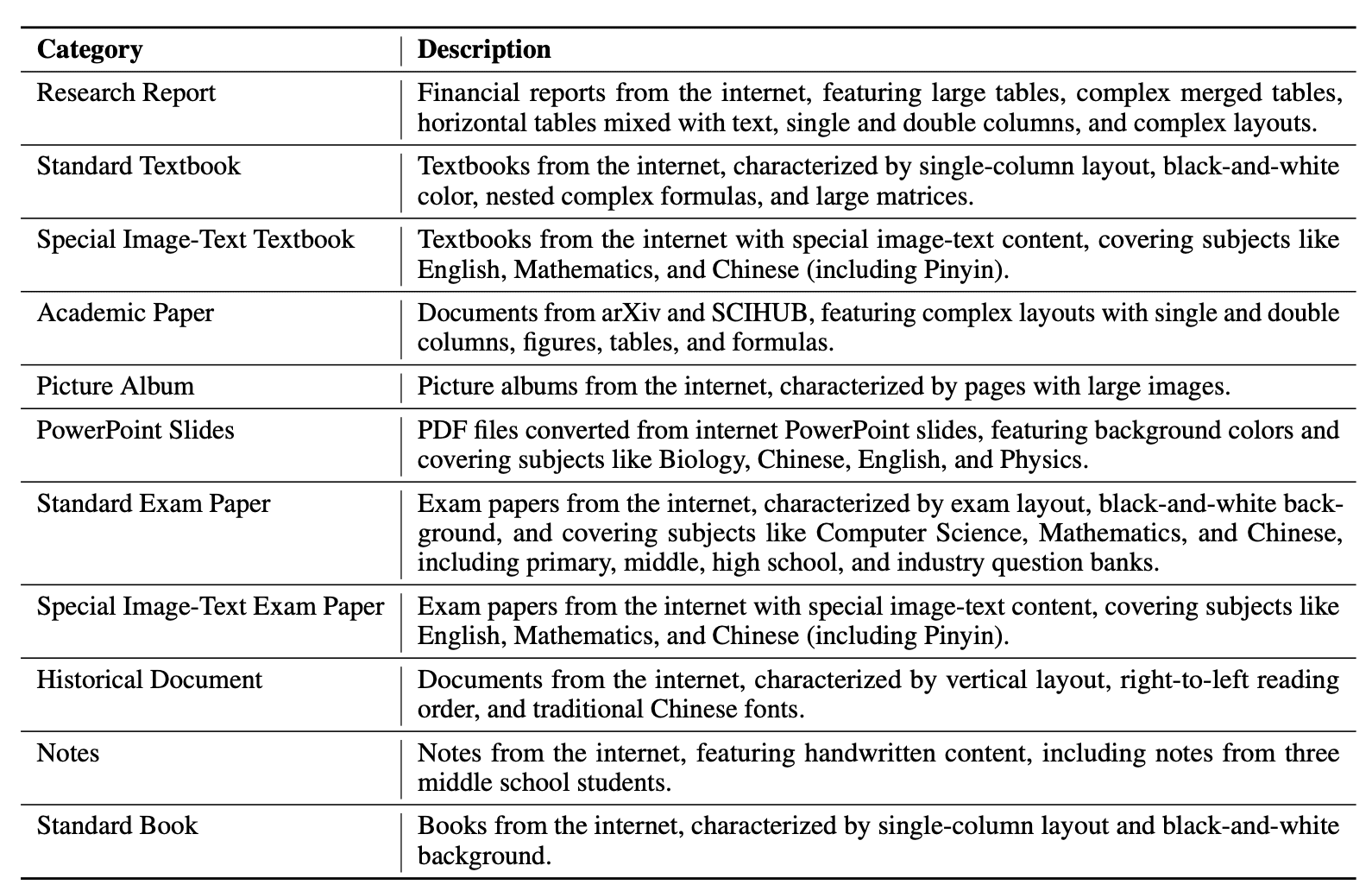
В цифрах
- 11 категорий документов в тестовом датасете;
- 24 157 встроенных и 1 829 отображаемых формул, аннотированных для обучения;
- 93,3% AP50 для распознавания структуры научных статей, что превосходит SOTA модели.
С развитием моделей LLM и RAG, качественное извлечение данных из документов становится все более важным для повышения качества обучения моделей и создания базы знаний.
Архитектура модели
MinerU использует многомодульную архитектуру, основанную на PDF-Extract-Kit. Модель LayoutLMv3 настраивается для точного распознавания элементов структуры документа. Для обнаружения формул применяется модель на базе YOLOv8, что позволяет значительно улучшить распознавание сложных форматов.
Модель UniMERNet используется для распознавания математических формул, а для обработки таблиц применяется TableMaster и StructEqTable. Оптическое распознавание символов (OCR) осуществляется с использованием Paddle-OCR.
Результаты и сравнение
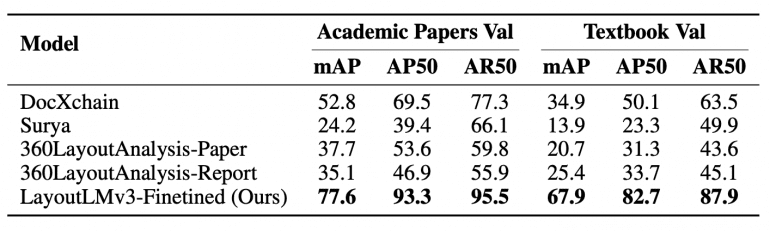

Основные результаты:
- Распознавание структуры: 77,6% mAP для научных статей (по сравнению с 52,8% для DocXchain);
- Обнаружение формул: 87,7% AP50 для научных статей (по сравнению с 60,1% для Pix2Text-MFD);
- Распознавание формул: 0,968 CDM (по сравнению с 0,951 у коммерческой Mathpix).
Открытый код
Код MinerU доступен в репозитории GitHub, где предоставлен полный конвейер обработки, предобученные модели и тестовые наборы данных.
В будущем команда планирует:
- Обновлять основные компоненты с учетом новых данных;
- Оптимизировать скорость инференса для работы в реальном времени;
- Разработать более обширный бенчмарк для различных типов документов.
MinerU представляет собой значительный шаг вперед в технологиях извлечения данных, обеспечивая высокий уровень производительности для разных типов документов и создавая основу для дальнейшего улучшения LLM и RAG систем.