MinerU2.5 — компактная vision-language модель с 1.2 миллиардами параметров для парсинга PDF документов, представленная командой Shanghai Artificial Intelligence Laboratory. Модель достигает state-of-the-art результатов в парсинге PDF при минимальных вычислительных затратах благодаря двухэтапной стратегии обработки: анализ структуры на уменьшенном изображении и детальное распознавание фрагментов в исходном разрешении. Код доступен на GitHub, веса модели — на Hugging Face.
В цифрах
- 1.2B параметров против 1.7-72B у конкурентов;
- 2.12 страниц PDF/секунду на A100 — в 4 раза быстрее MonkeyOCR-pro-3B;
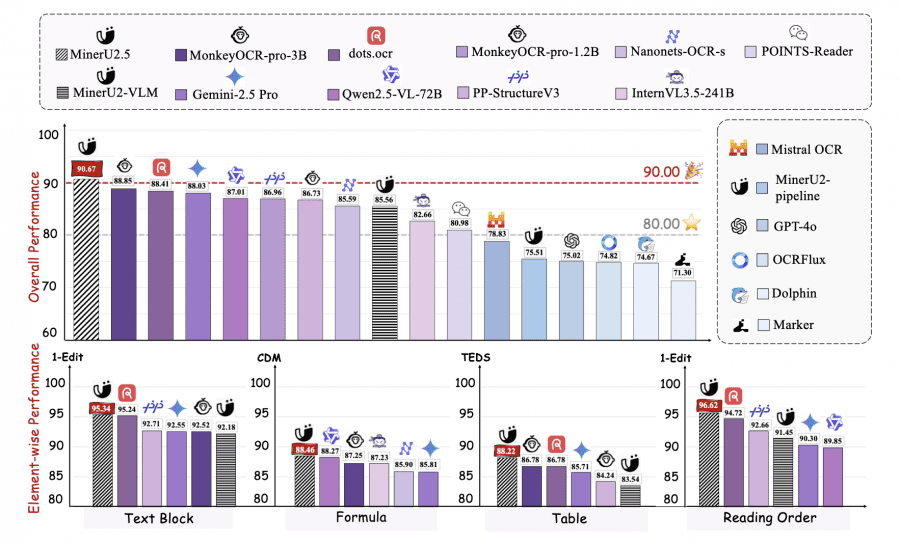
- 90.67 балла на OmniDocBench, превосходя dots.ocr (88.41) и MonkeyOCR-pro-3B (88.85).
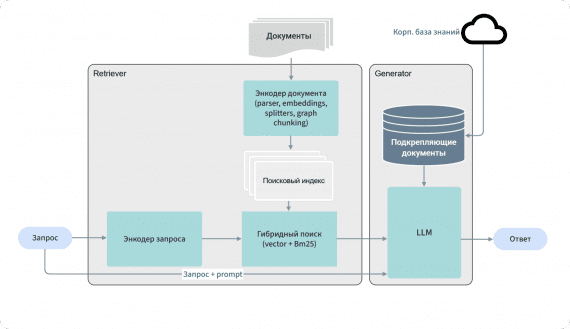
MinerU2.5 представляет принципиально иной подход к парсингу PDF по сравнению с традиционными пайплайн-архитектурами. Вместо последовательного применения специализированных моделей для каждой задачи, используется единая vision-language модель, которая разделяет глобальный анализ структуры и локальное распознавание содержимого.
Архитектура модели для парсинга PDF
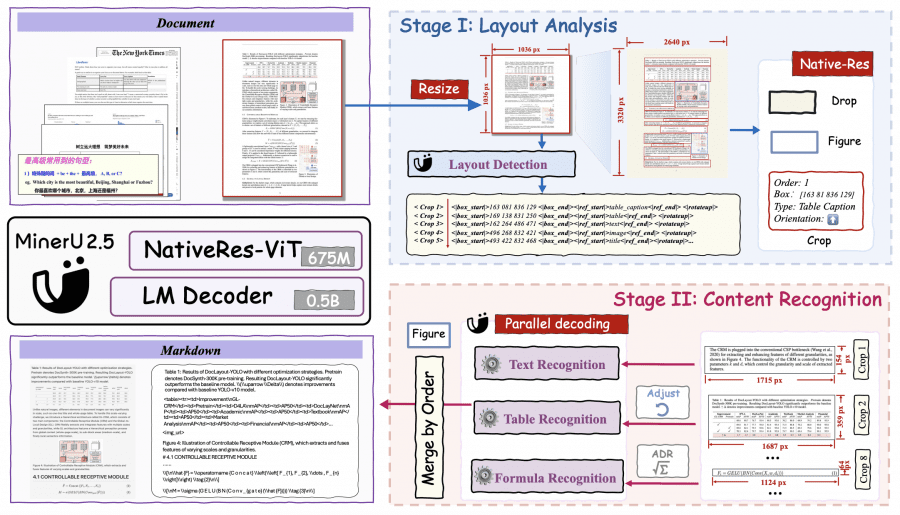
MinerU2.5 состоит из трёх компонентов: кодировщик изображений NaViT на 675 миллионов параметров (инициализированный от Qwen2-VL), модуль слияния патчей и языковая модель Qwen2-Instruct на 0.5 миллиарда параметров. Визуальный кодировщик поддерживает динамическое разрешение входных изображений с 2D-RoPE для позиционного кодирования, а для декодера применяется M-RoPE вместо стандартного 1D-RoPE для улучшенной обработки фрагментов с различными соотношениями сторон.
На первом этапе парсинга PDF страница масштабируется до 1036×1036 пикселей для анализа структуры документа. Выбор размера обусловлен балансом между видимостью глобальной структуры и вычислительной эффективностью — меньший размер приводит к потере деталей, больший запускает квадратичную сложность NaViT. В отличие от подходов с сохранением пропорций, фиксированный размер миниатюры улучшает стабильность локализации ограничивающих рамок.
На втором этапе модель использует результаты детекции для вырезания ключевых регионов из исходного изображения, которые обрабатываются в нативном разрешении с ограничением до 2048×28×28 пикселей. Это предотвращает потерю деталей от чрезмерно мелких фрагментов и избыточные вычисления от слишком крупных.
Двухэтапный подход снижает вычислительные затраты на порядок по сравнению с end-to-end методами, которые обрабатывают весь PDF документ в высоком разрешении с квадратичной сложностью O(N²). Разделение задач повышает интерпретируемость парсинга, уменьшает галлюцинации и позволяет независимо оптимизировать каждый этап.
Data Engine и обучение
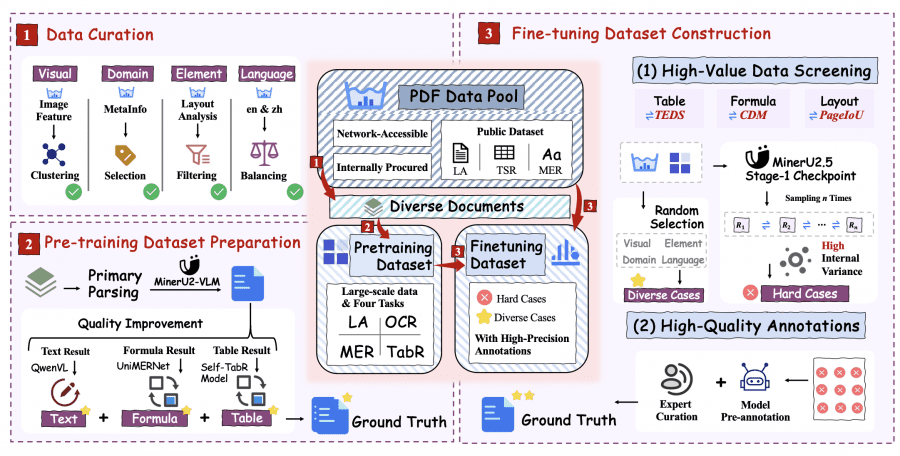
Обучение MinerU2.5 проходит три этапа. Этап 0 включает два подэтапа: выравнивание языка и изображений, где обучается только модуль слияния патчей на данных пар изображение-описание от LLaVA-Pretrain, и визуальная настройка по инструкциям, где размораживаются все параметры для обучения на задачах описания изображений, визуального выравнивания и оптического распознавания символов от LLaVA-Instruct.
- Этап 1 (предварительное обучение парсингу PDF) использует 6.9 миллионов примеров за 2 эпохи: 2.3 миллиона для анализа структуры, 2.4 миллиона для текстовых блоков, 1.1 миллиона для формул и 1.1 миллиона для таблиц. Документы масштабируются до фиксированного разрешения с относительными координатами для анализа структуры;
- Этап 2 (тонкая настройка парсинга PDF) проводится на компактном датасете из 630 тысяч примеров за 3 эпохи. Датасет включает высококачественные примеры из Этапа 1 и новые сложные случаи, выявленные через инженерию данных с применением стратегии итеративного поиска через согласованность инференса.
Эта стратегия выполняет несколько запусков вывода со стохастической выборкой для каждого образца. Высокая согласованность результатов указывает на уверенное предсказание, низкая — на сложный пример, требующий ручной разметки. Для анализа структуры используется метрика PageIoU, для формул — CDM, для таблиц — TEDS.
Для анализа структуры PDF разработана унифицированная система тегов, включающая не только базовые элементы (текст, заголовок, таблица, формула), но и редко учитываемые элементы (колонтитулы верхние и нижние, номера страниц) и детализированные категории (код, алгоритм, ссылка, список). Метрика PageIoU измеряет покрытие страницы на уровне пикселей, что лучше соответствует визуальному восприятию по сравнению с традиционными метриками пересечения и объединения.
Для распознавания формул в PDF применяется декомпозиция на атомарные формулы (неделимые семантические единицы) и составные формулы (упорядоченные наборы атомарных формул). Фреймворк атомарной декомпозиции и рекомбинации разбивает составную формулу на атомарные строки через анализ структуры, распознаёт каждую строку в формате LaTeX, а затем структурно объединяет результаты с корректным форматированием внутри окружений выравнивания.
Для таблиц используется оптимизированный язык структуры таблиц — промежуточное представление, которое сокращает количество структурных токенов с 28 до 5 и уменьшает среднюю длину последовательности на 50% по сравнению с HTML. Конвейер обработки включает четыре этапа: детекцию таблицы и угла поворота, коррекцию геометрии, распознавание в формате OTSL и конвертацию в HTML.
Результаты парсинга PDF и сравнение
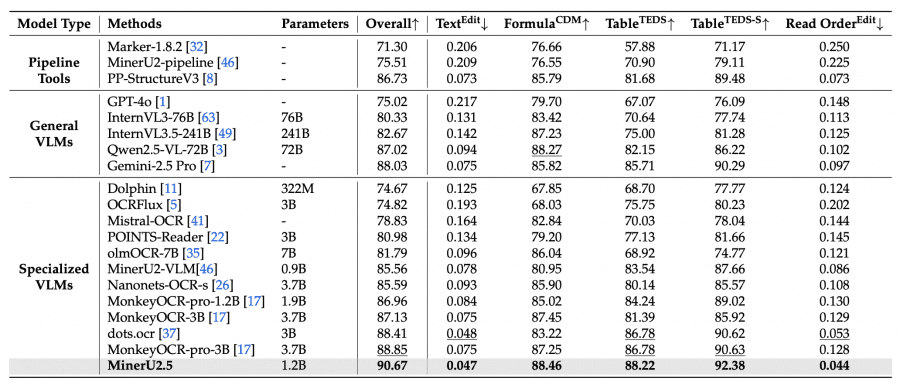
MinerU2.5 демонстрирует лучшие результаты парсинга PDF на основных бенчмарках: 90.67 на OmniDocBench, превосходя MonkeyOCR-pro-3B и dots.ocr по всем метрикам:
На Ocean-OCR benchmark модель достигает edit distance 0.033 и F1-score 0.945 для английского текста, 0.082 и 0.965 для китайского:

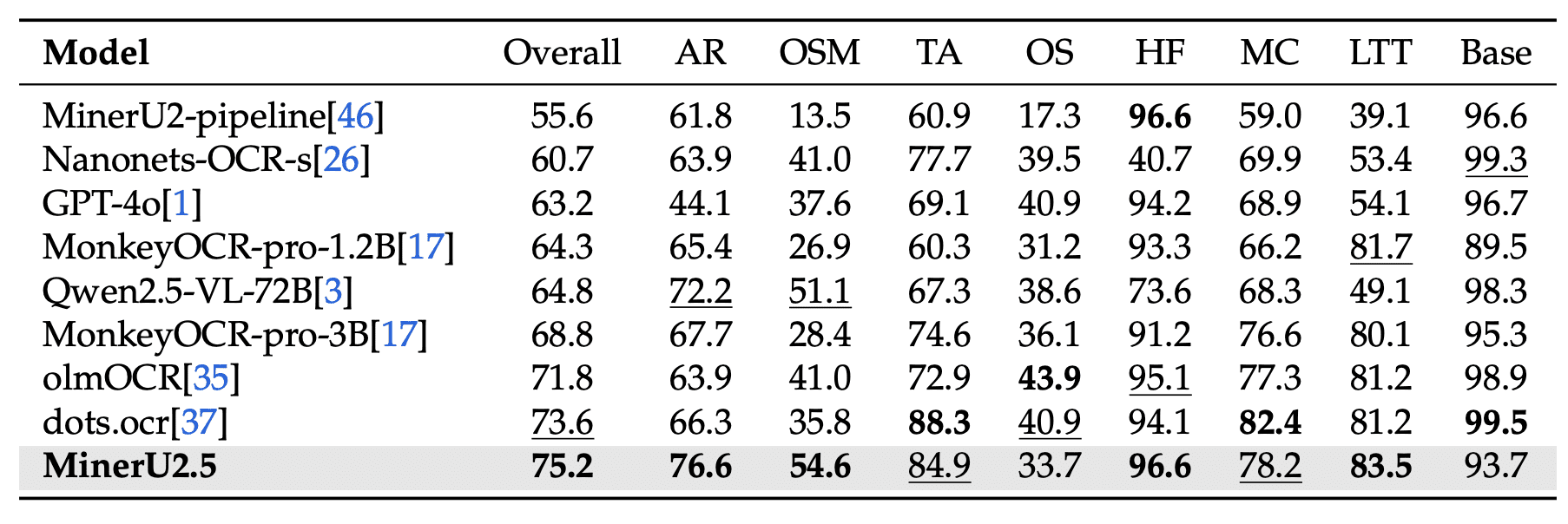
На olmOCR-bench общий балл 75.2, MinerU2.5 лидирует в категориях arXiv Math (76.6) и Old Scans Math (54.6):
Производительность парсинга PDF составляет 2.12 страницы/секунду на A100 80G и 2337.25 токенов/секунду для stage II, что превосходит MonkeyOCR-Pro-3B в 4 раза и dots.ocr в 7 раз. На RTX 4090 скорость составляет 1.70 страниц/секунду, на H200 — 4.47 страниц/секунду. Даже без оптимизаций развертывания модель достигает базовой производительности 0.95 страниц/секунду и 1045 токенов/секунду, превосходя другие сравниваемые модели в стандартных конфигурациях.
MinerU2.5 демонстрирует компактную и эффективную архитектуру для парсинга PDF документов. Модель достигает state-of-the-art результатов на нескольких бенчмарках при размере всего 1.2 миллиарда параметров, превосходя значительно более крупные модели в точности и скорости обработки различных типов PDF документов.