MiniMax выложил в open source модели MiniMax-01 с 456 миллиардами параметров: MiniMax-Text-01 для текстовых и MiniMax-VL-01 для визуально-языковых задач. MiniMax-01 стабильно обходит GPT-4o и Gemini-2 на бенчмарках с длинным контекстом, поддерживая стабильно высокую производительность (0.910-0.963) при длине контекста до 4M токенов. Полные веса моделей MiniMax-Text-01 и MiniMax-VL-01 доступны на Github.
Архитектура Minimax-01
Серия MiniMax-01 отличается от традиционных архитектур Transformer благодаря применению механизма Lightning Attention. Модель содержит 456 миллиардов параметров, из которых 45.9 миллиардов активируются на инференсе. Разработчики использовали гибридную структуру механизма внимания: 7 слоев Lightning Attention (линейное внимание) и 1 традиционный слой SoftMax attention.
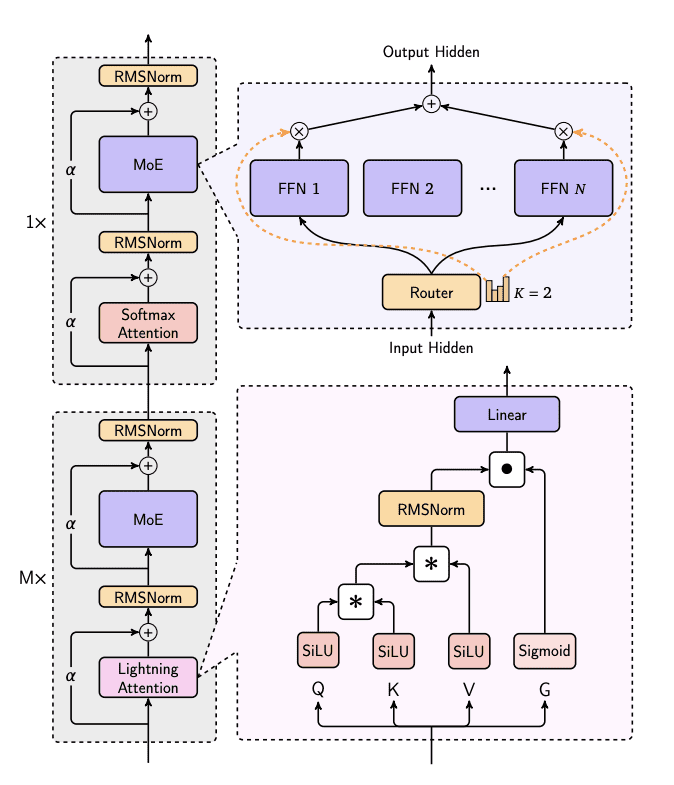
MiniMax-Text-01 имеет повторяющуюся блочную архитектуру с двумя ключевыми компонентами: слоями внимания и MoE (Mixture of Experts) обработкой. Каждый блок интегрирует слои RMSNorm с residual-соединениями (α), чередуя механизмы Lightning Attention и SoftMax Attention. Lightning Attention обрабатывает входные данные через SiLU-активированные Q/K/V преобразования и Sigmoid-гейт, в то время как компонент MoE использует Router для распределения входных данных между N Feed-Forward сетями с top-2 маршрутизацией. Такая архитектура эффективно обрабатывает длинные последовательности при сохранении производительности модели через сбалансированные механизмы внимания и экспертной маршрутизации.
Результаты бенчмарков
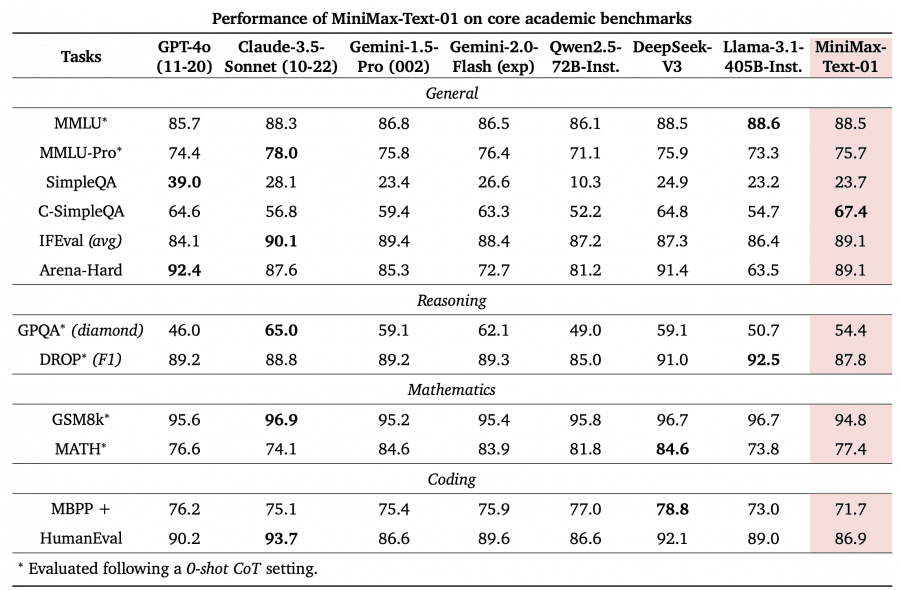
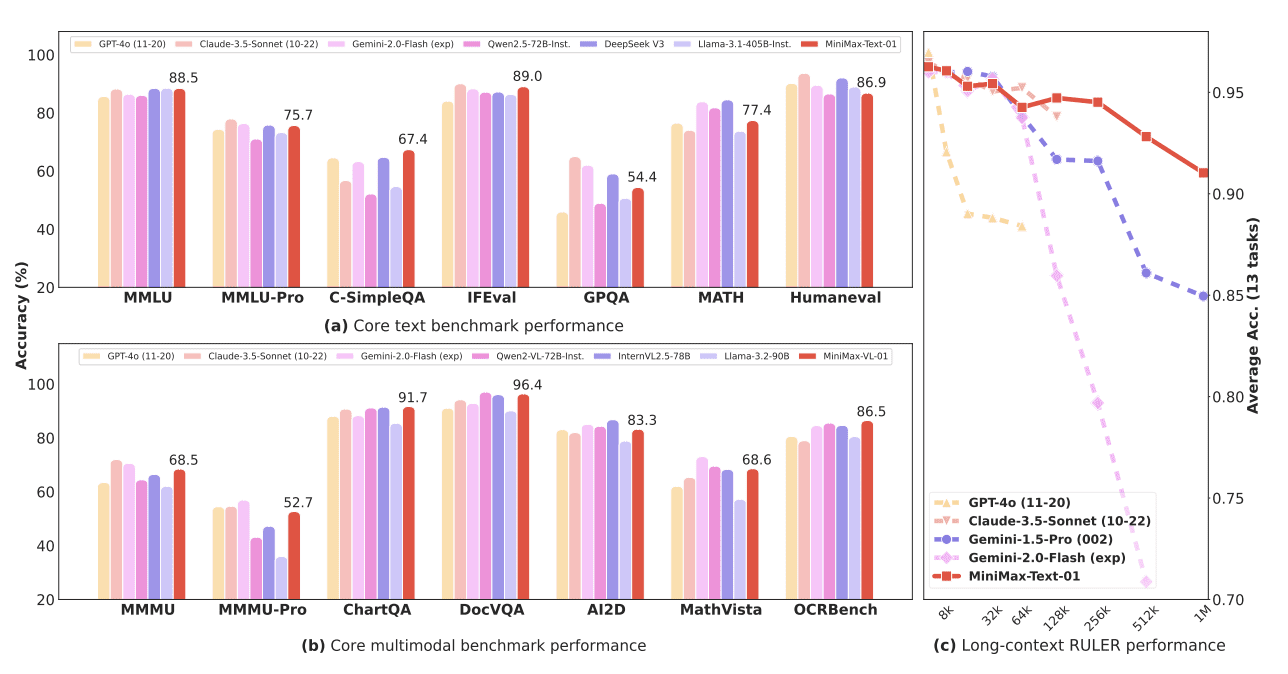
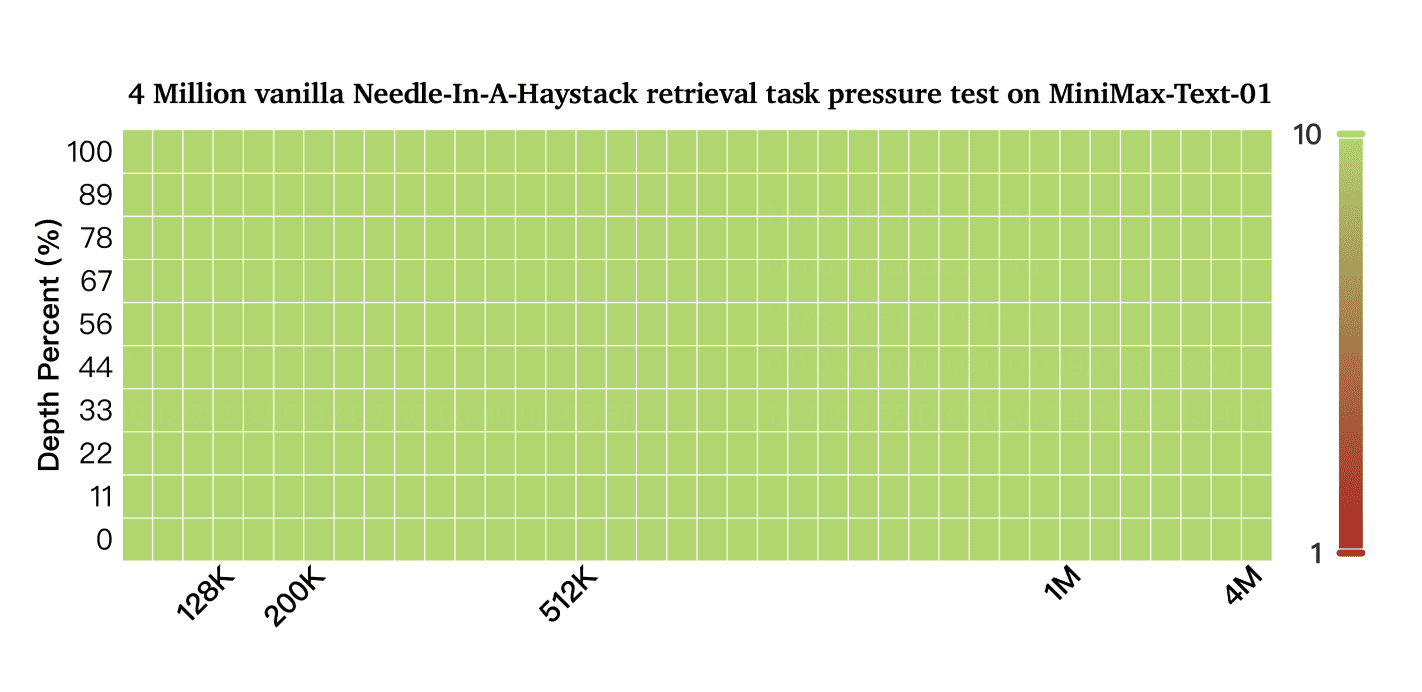
Модель на стандартных бенчмарках соответствует ведущим моделям от OpenAI, Claude и Google в понимании текста и мультимодальных данных. Особенно примечательно достижение 100% точности в задаче поиска Needle-In-A-Haystack с контекстом в 4 миллиона токенов при минимальной деградации производительности с увеличением длины входных данных.
Производительность Minimax-01 при различной длине контекста
MiniMax-Text-01 демонстрирует исключительное масштабирование производительности при различной длине контекста, особенно выделяясь на длинных последовательностях. В тестах Ruler она поддерживает стабильно высокие показатели от 4k до 1M токенов:
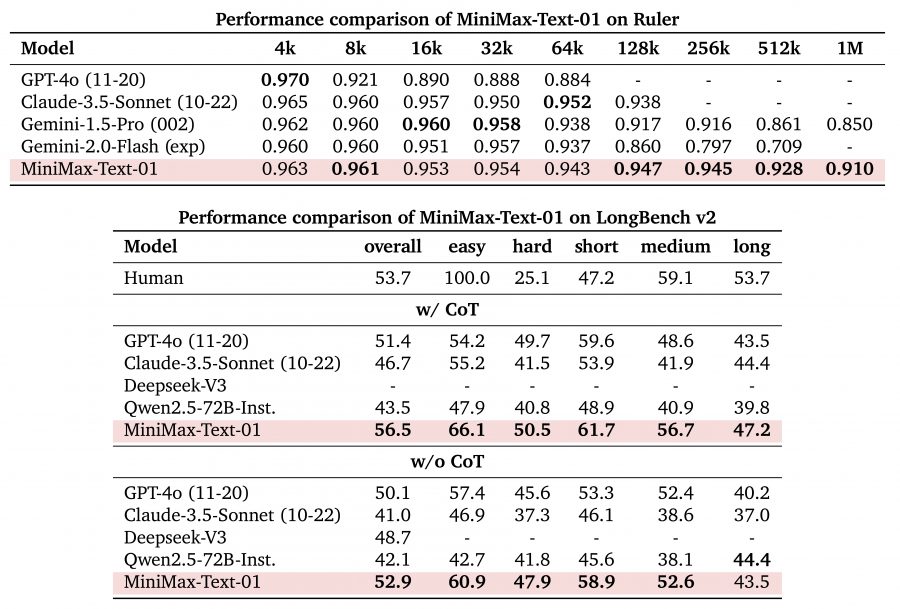
Короткий и средний контекст (4k-64k): удерживает результат выше 0.94, соответствуя или превосходя модели GPT-4o и Claude-3.5-Sonnet
Расширенный контекст (128k-1M): minimax-01 показывает стабильные оценки 0.947-0.910, превосходя всех конкурентов, таких как Gemini-2.0-Flash, результат которого падает до 0.709 на 512k токенах.
Производительность в LongBench
Модель демонстрирует превосходные возможности в бенчмарке LongBench v2, как с Chain of Thought (CoT), так и без него:
- Общая производительность: Достигает 56.5 (с CoT) и 52.9 (без CoT), превосходя все сравниваемые модели, включая GPT-4o
- Специфические сильные стороны: Особенно преуспевает в категориях ‘easy’ (66.1) и ‘short’ (61.7) с CoT
- Стабильная производительность: Поддерживает высокие показатели во всех тестовых категориях, демонстрируя сбалансированные возможности
Эти результаты бенчмарков подтверждают эффективность архитектуры MiniMax-Text-01, особенно подчеркивая её способность поддерживать высокую производительность при увеличении длины контекстных окон, что является crucial достижением для практических AI приложений.
Доступность и цены
- Чат: https://www.hailuo.ai/
- Доступ к API: MiniMax Open Platform
- Конкурентная ценовая структура: $0.2 за миллион входных токенов
- Возможности обработки визуально-языковых данных с MiniMax-VL-01
- Разработчики обещают регулярные обновления кода и развитие мультимодальных функций
Выпуск MiniMax-01 знаменует важный шаг вперед в развитии AI, особенно для AI Agents, где критически важна обработка расширенного контекста. Архитектура модели обеспечивает надежную основу для управления сложными взаимодействиями с длинным контекстом как в системах с одним агентом, так и в сценариях коммуникации между несколькими агентами.




