Исследователи Университета Висконсин-Мэдисон представили text-to-image диффузную модель PACGen (Personalized and Controllable Text-to-Image Generation) для переноса объекта с изображения на новую сцену, сгенерированную по текстовой подсказке. Для этого требуется подать на вход несколько изображений объекта, текстовую подсказку с описанием новой сцены и выделить область, в которую следует поместить объект.
PACGen достигает сравнимого или даже более высокого качества для персонализированных объектов по сравнению со state-of-the-art моделями. Потенциал модели огромен, например, дизайнеры рекламы могут размещать свою продукцию в любом желаемом месте на рекламном баннере.
Исследователи пока не опубликовали код модели, по заявлению авторов он появится в репозитории на Github в ближайшее время.
Метод
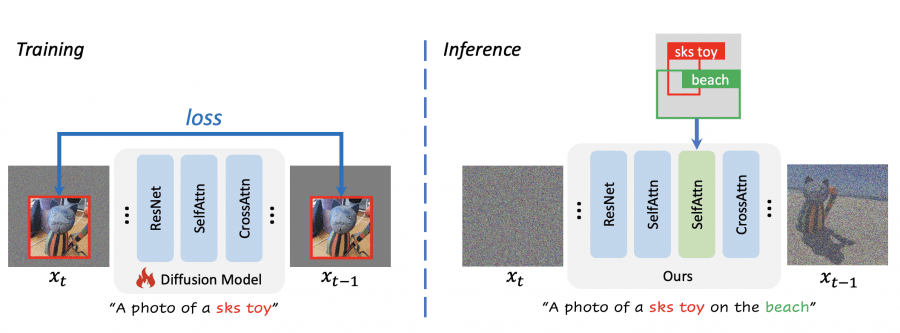
Исследователи объединили две open source модели, построенных на архитектуре Stable Diffusion. Диффузная модель DreamBooth хорошо справлялась с переносом поданного на вход объекта на новую сцену, но испытывала трудности с контролем местоположения и размера объекта:

Чтобы это исправить, исследователи подключили к DreamBooth адаптерные слои модели GLIGEN, хорошо умеющей генерировать поданные на вход объекты в указанной области, но плохо справляющейся с сохранением идентичности объекта. В результате получилась новая модель PACGen, точно контролирующая расположение и размер выбранного объекта на новой сцене. Метод регионально-управляемой выборки обеспечил сохранение качества и достоверности сгенерированных изображений на выходе.
С помощью внедрения техники аугментации данных, которая включает случайное изменение размера и положения изображений из тренировочной выборки, PACGen обучилась разделять идентичность объекта и пространственную информацию для создания персонализированных изображений:
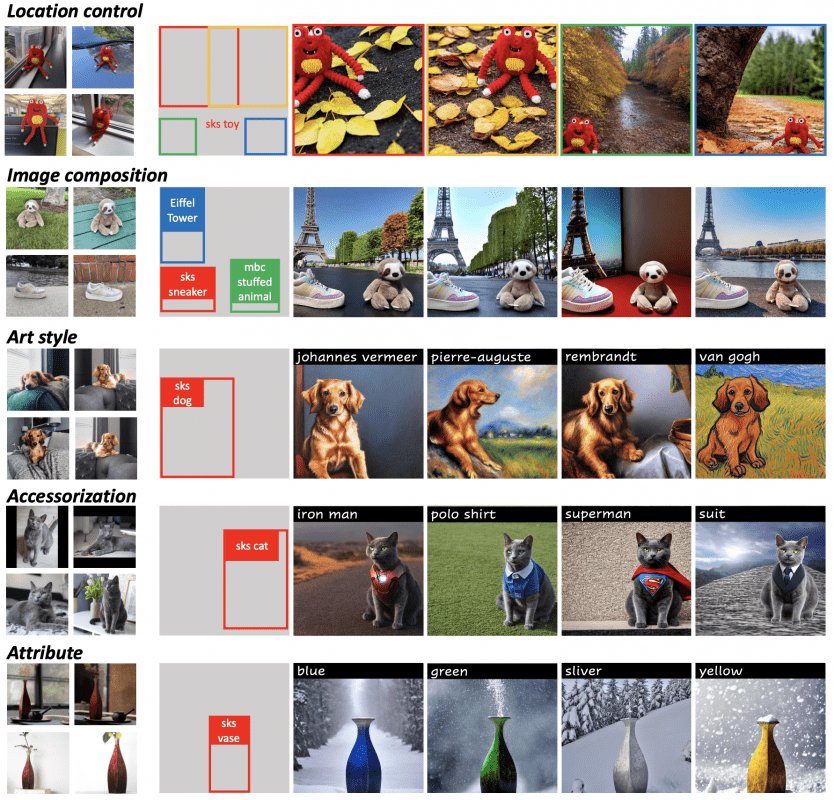
Результаты PACGen
Метод предлагает множество вариантов применения. PACGen позволяет генерировать объекты в указанных рамкой местах в прописанных сценах и художественных стилях:
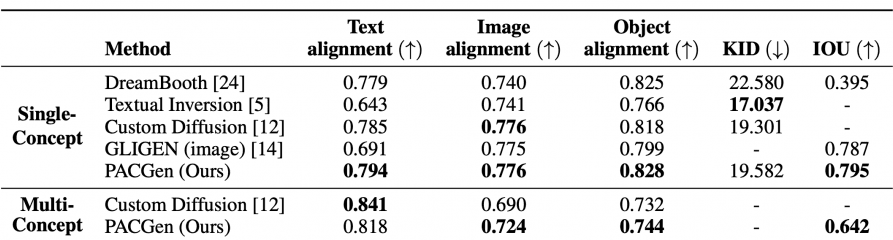
Количественное равнение со state-of-the-art моделями: