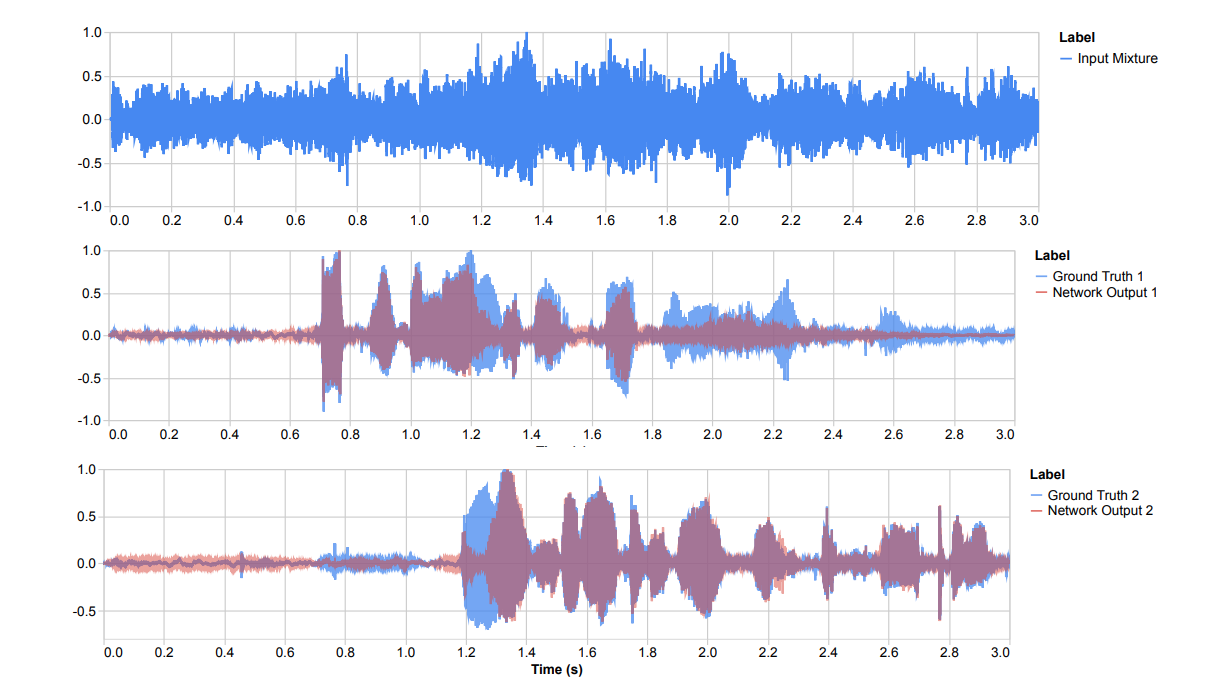
Cone of Silence — это нейросетевая модель, которая разделяет спикеров на аудиозаписи, записанной с нескольких микрофонов. Модель выдает аудиодорожку с речью спикера и предсказывает расположение спикера относительно микрофонов. Нейросеть справляется с аудиозаписями, где спикеры говорят одновременно и перебивают друг друга.
Нейросеть изолирует источники звука для отдельного угла. Экспоненциально уменьшая угол, модель локализует и разделяет источники звука за логарифмическое время. Алгоритм работает на аудиозаписях с любым числом передвигающихся спикеров. По результатам экспериментов, модель выдает state-of-the-art результаты и на задаче локализации источника шума, и на задаче разделения спикеров.
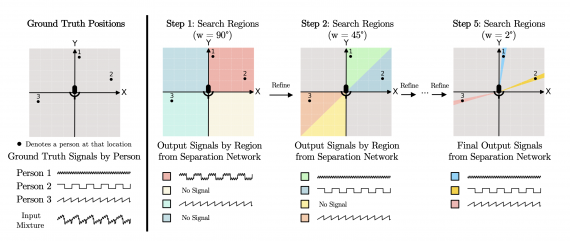
Подробнее про работу модели
На первом этапе алгоритм делит аудиозапись на регионы в 90 градусов. Части аудиозаписи без звука не учитываются. Алгоритм продолжает делить аудиозапись на меньшие части, пока не достигнет итогового шага, где регион охватывает 2 градуса.
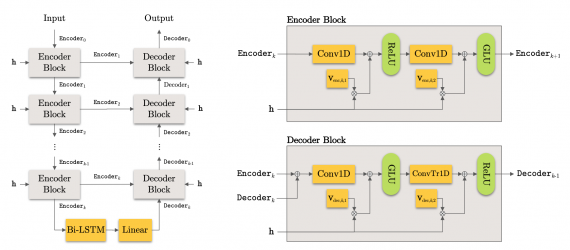
Тестирование работы нейросети
Работу модели сравнивали с state-of-the-art подходами. Ниже видно, что предложенная архитектура обходит предыдущие модели, основанные на данных звуковых волн и на спектрограммах.